
4/23 5/14 5/28 6/11(1) 6/11(2) 6/25(1) 6/25(2) 7/9 7/30 8/20 9/17 10/26 11/12(1), 11/12(2) 11/26 12/10 12/17 1/21(1), 1/21(2) 2/4 2/18a 2/18b 3/18
Levelt, W. J. M. (1989). Speaking: From intention to articulation. Cambridge, Mass: The MIT Press.
Chapter 1 (pp. 1-14)
1.0 Introduction
■「スピーキング」という行為は人間の持つ最も複雑な技能のひとつで、その習得過程や状態は人の成長とともに絶えまなく変化し、発展していく。
■この本では、様々な下位システムや構成要素を内包する、複雑な認知的技能であるスピーキングについて述べるが、この章ではまず、話し言葉が生みだされる背景にある処理システムを分割していくことから始めたい。
■以下がこの章の各節の概要である。
1.1 ある話し手の発話をケーススタディとして紹介し、スピーキングの処理システムの大ま かな構造を述べる
1.2 話者の意図が発話されるまでの処理システムの様々な構成要素について
1.3 前節で述べられたシステムについてより詳細に記述する(その自律性や自動性について)
1.4 (上に同じ)
1.5 それら構成要素の協働作用により生まれる「増加的産出(incremental production)」につ いて述べる
1.1 A Case Study
■以下はSvartvik & Quirk(1980)にある、2人の教授(ともに40歳代)と1人の学生(18歳)で行われた会話である。教授は学生のシェイクスピアについての知識を試している。
教授1: [e:m] …would you say Othello was [e:] … a tragedy of circumstance…or a tragedy of character.
(沈黙)
学生: I I don’t know the way…play WELL enough sir.
■これは面接試験での会話だが、ここで「沈黙」があったのは、学生が自分の知識を探って、教授の質問に対する答えを見つけようと考えていたからではない。実は、この前に同じ質問を教授2が学生にすでに聞いており、話を聞いていなかったと思われる教授1に対しどう対処すべきか、学生が考えていたからである。
■ここでわかるのは、発話の初段階では文脈などの要素をもとに「どういう目的や意図をもって話すか」という決断が成される、ということである。上の例で学生は、(1)自分が質問に答えられないことを教授に推測させることで、教授のミスを指摘することの無礼さを隠そう、(2)自分はOthelloについて全く知識がないわけではないと教授に思わせよう、という意図を持って発話をしていると考えられる。このような意思決定をこの本では「macroplanning」と呼んでいる。
■一方、上記の例では他に3つの決断が行われており、これらは発話内の情報が新旧どちらであるかなど、発話の中身に関することで「microplanning」と呼ばれる。上記の発話での3つの決断とは、(1)Othelloを「劇(play)」という語に置き換えたこと、(2)Othelloとそれに関する自分の知識量が回答の答えであるべきと認知すること、(3)劇についての知識の量に焦点を当て「WELL」という単語に核強勢を置くこと、である。
■一旦これらの決断が成されると、次に「心的辞書(mental lexicon)」と呼ばれる語彙貯蔵庫へのアクセスが行われる。このプロセスには意味情報以外に、統語・形態素・音韻的情報も関わる。
■第6・7章で扱うが、この心的辞書へのアクセスにはまず統語(ときに形態素)などの非音韻的な情報が用いられる。これをレマ情報(lemma information)、または略してレマ(lemma)と言う。先の例では、レマknowは経験者(experiencer)としての主語(ここではI)と、目的語(または補語)を必要としており、この規則に従って語彙を正しい順序に並べることを「文法符号化(grammatical encoding)」と呼ぶ。またこれに加えて、don’tという助動詞を用いる、playという語を用いる、WELLに核強勢を置く、主格Iを用いる、などの種々の決定により「表層構造(surface structure)」と呼ばれるものが形成される。
■ではなぜ「way」という誤りが生まれたのか。これは表層構造内のplayとWELLの発音が混ざり合ってしまった結果として考えられ、この種の誤りは発話における「音韻符号化(phonological encoding)」の存在を示す重要な証拠となる。話者は表層構造内のレマの音韻像を検索した後に、発話のためのphonetic/articulatory planを組み立てるのである。
■最後に、学生はwayと言ってしまった自分の誤りに気づくことができた。これは学生が自身の発話や相手の様子をモニター(monitor)していて、そこからフィードバックを得ているからである。
■以上の流れをまとめると以下のようになる。
①発話目的の選択
②意図を相手に伝えるための手段や概念の決定
③語彙へのアクセス
a. 統語表層構造の形成
b. phonetic planの組み立て
④発話のモニター
1.2 A Blueprint for the Speaker
■図1.1にある様々なプロセスは、互いに関連していて、ある過程ではアウトプットであったものが、別の過程ではインプットになったりする。この節では、この発話に至る情報の流れを作る各構成要素を紹介していきたい。
1.2.1 Conceptualizing
■Conceptualizerという処理システムで行われるのは概念化(conceptualizing)という処理で、この結果生みだされるのはpreverbal messageというものである。
■このmessageを生みだすには2つの知識が必要である。
①手続き的知識(procedural knowledge):
「IF X THEN Y」のような「条件→実行」型のシステムに関する知識。結果は作動記憶(Working Memory)内で貯蔵される。
②宣言的知識(declarative knowledge)
命題的知識(propositional knowledge)とも呼ばれる。「マンハッタンは危ない」といったもので、長期記憶(Long-Term Memory)内にある。経験により蓄えられた知識だけでなく、目の前の会話から得られる情報(相手が誰か、周りの音など)や、それまでの会話の内容もこの知識に入るが、これらはそれぞれ特にsituational knowledgeやdiscourse recordと呼ばれる。
■生みだされたpreverbal message(この時点ではアウトプット)はインプットとしてFormulatorへと伝えられる。前節で述べたようにpreverbal messageの計画段階にはmacroplanningとmicroplanningの2つがある。
1.2.2 Formulating: Grammatical and Phonological Encoding
■Formulatorは概念構造(conceptual structure)を言語構造(linguistic structure)へ翻訳する構成要素である。これには2つのステップがある。
①文法符号化(grammatical encoding):
この処理には(1)レマへのアクセスと(2)統語構造の形成という過程がある。レマへのアクセスでは、宣言的知識としてのレマ情報のうち意味(meaning or sense)が心的辞書より取り出される。統語構造の形成では、レマ情報としての統語情報(syntax)が活性化され(動詞giveは行為者としてX、Xから渡される所有物Y、そして受取り手のZが必要など)、表層構造が形成される。この結果はSyntactic Bufferへと取り込まれる。
②音韻符号化(phonological encoding):
発話のためのphonetic planを形成する段階。形態素情報(例 dangerous = 語幹:danger + 接辞:-ous)も活性化され、強勢の置かれる音節の確認などが行われる。そしてさらに上位の音韻処理が行われ、文強勢がどこに置かれるかも決定される。より意識的にphonetic planが作られると考える場合にはinternal speechと呼ぶこともある。
1.2.3 Articulating
■phonetic planを調音器官に送り、実際に発話する過程。調音はわずかにinternal speechに遅れるため、phonetic planは一時的にArticulatory Bufferという貯蔵装置に蓄えられる。こうして調音されたinternal speechはovert speechとなる。
1.2.4 Self-Monitoring
■internal speechとovert speechの両方に注意を払うことを指し、これはAuditionという構成要素で行われ、最終的にSpeech-Comprehension Systemで自分の発話が意味・音韻・統語などの観点から適切であるか判断される。この診断結果はparsed speechとしてConceptualizerへと送られ次の発話へ利用される。
■このようなモニターはovert speechになる前の作動記憶内のinternal speechに対しても行われる。Levelt (1983)やFay(1980b)などの発話例に見られるように、話者は単語を言い切る前に意味や文法の間違いに気づき、言い換えたり、発話自体を中断することがあるとわかっている。
■また話者はFormulatorに送られる前のpreverbal messageもモニターすることがある。ここでは、談話の流れや、話者と聞き手の知識の共有度などを考慮した場合に、意図した内容が伝わるか、ということを吟味する。Conceptualizerのmonitoringという箇所がこれを主に行っている構成要素になる。
<コメント>
用語がたくさん出てきた。手続き的知識と宣言的知識の本文の説明が短く再確認が必要であるとの意見が出た。
2009/5/14
Chapter 1 (pp. 14-28)
◎前回紹介したプロダクションモデルに現れた用語(一部)の日本語訳について
<参考文献>
馬場哲生編著 (1997)『英語スピーキング論』東京:河源社
村野井仁 (2006)『第二言語習得研究から見た効果的な英語学習法・指導法』東京:大修館書店
1.3 Processing Components as Relatively Autonomous Specialists
■前節で紹介したような処理システムの区分方法が、これまでのスピーキングのモデル(e.g. Garrett, 1975; Kempen & Hoenkamp, 1987; Bock, 1982; Cooper & Paccia-Cooper, 1980; Levelt, 1983; Dell, 1986; etc)に比べ妥当であるかどうか決定するには、様々な実証的・理論的考察を加えなければならない。
■はじめに議論すべきは、それぞれの構成要素はいくぶん自律的(relatively autonomous)で、専門的(specialist)でなければならないということである。例えばGrammatical Encoderは、概念関係を文法構造へ転換するのを専門とし、この過程で他の構成要素との連携はない。
■これに相対する考えは、1つの構成要素が全ての構成要素からの情報(アウトプット)をインプットとして受けるというものである。この場合、多様な情報を処理するアルゴリズム(処理手順)をどう定義し、具体化するかという問題がある。
■しかし一般的に、あるシステムを分割するには、(a)各構成要素が受けるインプットをできるだけ限定し、(b)各構成要素の機能が他から受ける影響を最小限にする、という2つの条件が必要である。これはときに「情報の規格化(informational encapsulation)」と呼ばれ、図1.1のモデルはこれらの条件を満たしていると言える。つまり構成要素-インプット、構成要素-アウトプットが1対1の対応関係になっている。
■これらの仮説は強くも儚いものだが、実験的に証明することもできる。後の7.5で扱うが、例えばFormulatorからConceptualizerへの直接的なフィードバックがあるかどうかについては、今のところ「否(negative)」という答えが出ている。
■一方、ある構成要素に含まれる複数の下位要素が異なる自律性(autonomy)を持つということはあるかもしれない。例えば、Formulatorの下位処理である文法コード化(grammatical encoding)が音韻コード化(phonological encoding)からのフィードバックを受けるという可能性を指摘した研究もある(Levelt & Maassen, 1981; Dell, 1986; および第7・9章を参照)。
■以上より、各構成要素が「いくぶん自律した専門家(relatively autonomous specialist)」であるという考えに立つと、次の4つの疑問を解決する必要が出てくる。
① 各構成要素がインプットとして受ける、またはアウトプットとして送る情報の種類とは何か?
② インプット情報をアウトプットへ変換するのに必要なアルゴリズム(処理手順)は何か?
③ そのアルゴリズムをリアルタイムで実行可能にするのはどのようなプロセスか?
④ どこからインプットが来て、どこへアウトプットが行くのか(ある構成要素は複数のインプット資源とアウトプットの送り先を持ちうるか)?
■本書を通してこれらの質問を繰り返して取り上げ、各構成要素について検討を重ねるが、その際にはまずアウトプット(Grammatical Encoderならsurface structure)の特徴(grammatical encoding algorithm)を描き出すことから始めなければならない。そしてそれを明らかにするのは主に発話中の誤り(speech errors)である。(→問題①に対する考察)
■次に構成要素間の関係について考えないといけない。ある構成要素のアウトプットは同時に次の構成要素にとって特有のインプットになると述べたが、そうでない場合があるのかどうか、つまりフィードバックが行われるかという問題も吟味しなければならない。これは次節の「executive control」のところで扱っている。(→問題④に対する考察)
■2章以降では、各構成要素の出力表象?(output representation)とそれに付随するアルゴリズムと処理プロセスについての議論がされるが、これには理論と実証的研究の両面からの考察が必要である。この章では概要を述べるに留めたい。(→問題②・③に対する考察)
■概念化の段階で用いられるアルゴリズムは、先に述べた「条件→実行(IF X THEN Y)」型の手続き的知識に基づいたプロセスで、これにより産まれたものはproductionsと呼ばれる。この手順は一般化が可能なため、XやYの内容を決める変数としての宣言的知識(declarative knowledge)とは異なる性質のものである。
■問題③に関連して、複数のアルゴリズムは発話の流暢さを保つためにリアルタイムで行われなければならない。それをモデル化したのが下の図1.2で、「コネクショニスト(connectionist)」や「拡散活性?(spreading activation)」の考えに基づいている。この神経回路構造でのアルゴリズムは、ネットワークで結ばれたノード(node)と呼ばれるものが互いに活性化しあうということである。constructの例が以下の①~③である。
①レマconstructに一致する音声形式(sound form)の検索開始
②音節への分解
③con-が活性化・発火(fire) → c・o・nがそれぞれ活性化・発火
↓
-structが活性化・発火(fire) → s・t・r・u・c・tがそれぞれ活性化・発火

■このコネクショニズムに基づいた活性化モデルは様々な研究者により細部(拡散の方向や、活性の時間など)が異なるため「理論(theory)」とは呼びがたいものであるが、本書では並列分散処理(parallel distributed processing)やDell(1986)の音声コード化理論(theory of phonological encoding)などを用いてより理論的な提案をしていきたい。
1.4 Executive Control and Automacity
■前節ではスピーキングの構成要素がいくぶん自律的な専門家であることを述べた。しかしスピーキングには自動的なプロセス(automatic processes)と統制されたプロセス(controlled processes)の両方があり、以下はそれらの特徴についてまとめたものである。
<自動的なプロセス>
他のプロセスとprocessing capacityを共有せず、互いに干渉することなく並行して行われる
自動化は遺伝や学習、またはその両方によってなされる
<統制されたプロセス>
注意資源が必要であり、同時に多くのことに注意を向けられない
作動記憶内で保持される
今していることへのある程度の気づきがある
■「概念化(conceptualizing)」と「モニタリング(monitoring)」のプロセスは極めて統制されたプロセスであると言える。会話経験が豊富な大人になるとこのプロセスが自動化される場合もあるが、基本的には意識的になりやすいプロセスで、情報の規格化(informational encapsulation)がされていないと言える。
■一方、「形式化(formulating)」と「調音化(articulating)」のプロセスはたいてい自動的なものである。発話が1秒間に2~3語の速度で、また調音は1秒間に約15音素の速度で行われることからもそれはわかる。これら2つのプロセスに中央統制が及ばないことは、Pylyshyn(1984)でいう「認知的不可入性(impenetrability)」の1種である。
■自動的なプロセスにも中央統制の補足的な機能が働くことがあり、これは発話の全体的な側面を統御する。例えば発話の速度、大きさ、調音の正確さなどである。
1.5 Units of Processing and Incremental Production
1.5.1 Units of Processing
■発話をどのような単位で区切るかという議論はたくさんされてきたが、多くの場合1)単位は1種類である、2)考えられる単位は1つではないがどれかに絞って研究している、のどちらかの立場である(単位の例についてはp.23を参照)。
■どの単位を支持するにしても実証的証拠が乏しいことは後述の章で述べるが、現段階で言えるのは、発話に決まった単位はなく各構成要素が独自の単位で処理をしているようだ、ということである。
1.5.2 Incremental Production
■多段階モデル(multistage models)よりも「多面的単一段階発話生成?(multi-faceted single-stage speech production)」モデルがしばしば好まれるのは、前者のモデルでは発話の流暢さに深刻な影響を与えることになってしまうからである。
■前者では新しい処理は前段階の処理が終わってから始まるとし、後者は処理が未完成のうちにその断片(fragment)が新しい処理にまわされるとする。sixTEEN + DOllars →SIXteen DOllarsというストレス変化の現象などはあるが、基本的にそのような予測を要する処理はごく限られたレベルでしか起こらない。後者のような処理の仕方は、漸次的処理(incremental processing)と呼ばれる(Kempen & Hoenkamp, 1982, 1987)。
■incremental processingでは下のbのように各fragmentの順序が入れ替わることが可能である。
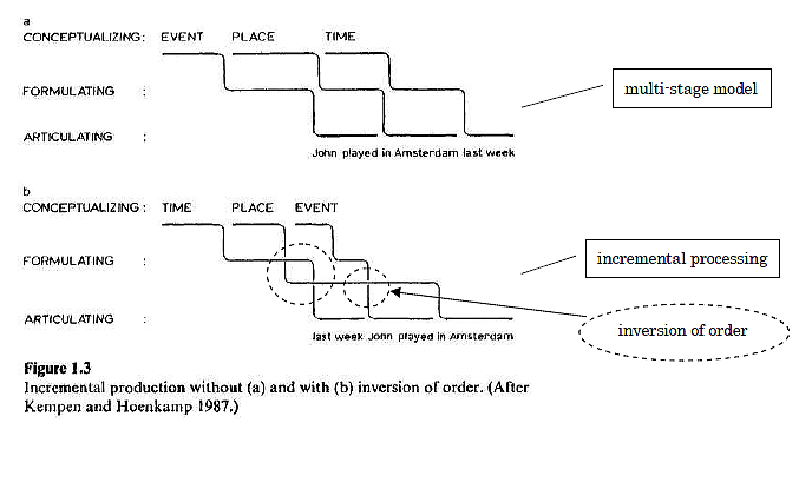
■概念化の段階ではTIME(last week)→PLACE(in Amsterdam)→EVENT(John played)の順で完成しているが、形式化の段階でPLACE(in Amsterdam)→TIME(last week)→EVENT(John played)に完成し、調音化の段階ではさらにTIME(last week) →EVENT(John played)→ PLACE(in Amsterdam)と変化している。
■語の順番は、概念の順番と必ずしも一致しない。調音化でPLACEが最後に来たのは、その前の形式化の段階で英語の統語の制約が働き、Last week in Amsterdam John played.という語順を許さなかったからである。
■他の言語でさらに語順の制約がかかるときがある。ドイツ語ではEVENT→PLACE→TIMEという語順であるため、fragmentの順序変更が必要になった時はそれをどこかで保持しなければならなくなる。これを担当するのは既に述べた作動記憶(Working Memory)・統語バッファ(Syntactic Buffer)・調音バッファ(Articulatory Buffer)の3つである。
■Wundt(1990)は、「語順は総合観念のうち部分の連続的統覚(successive apperception)に付随するものである」と述べている。すなわち「各構成要素はその特有のインプットの最少量により活動へと誘発される」ということで、これを「ブントの原理(Wundt’s principle)」と呼びたい。次からの章では、この最小限のfragment(input)の量についても議論をしていく。
1.6 Summary
■以降の章では、図1.1で示したメッセージの産出からセルフモニタリングに至るプロセスについて、理論的言及や実験的研究の成果に触れつつ述べていく。しかし次章では、まずはじめに話者の会話における(interlocutorとしての)役割について論じてみたい。
Chapter 2 (pp. 29-48)
2.0 Introduction
■話し言葉の根本は会話の自由なインタラクションにある。会話は言語使用が非常に文脈化された形であり、参加者のコミュニカティブな意図があって生ずるものである。つまり「話し言葉の規範的設定(canonical setting for speech)」とは、話し手が何らかの意図を持って、共有された時間-空間的な環境において、相互作用していること、と定義づけられるかもしれない。本章では会話における話し手の役割を考えながら、これら3点について議論したい。各節で扱う内容は以下の通りである。
★2.1 話し言葉の相互作用的な性格について(turn-taking, cooperation)
★2.2 スピーキングが時間-空間的文脈に依存していることについて(deictic character)
2.3 目的を持った行動としてのスピーキングについて(intentional character of speech)
2.1 Interaction
2.1.1 Cooperation
■ある会話を適切とみなすには2つの規則があり、これらは言語学的基準に基づくものではない。次の(1)と(2)がその2つの規則であるが、これらに忠実な場合、その話し手は「協力的(cooperative)」であると言える。
(1) ターンの割り当てについての規則 (i.e. いつ発言すべきか)
(2) 発言内容についての規則 (i.e. 文脈に則しており、発話の意図が明確か)
2.1.2 Turn Taking, Engagement, and Disengagement
■Turn-constructional units:ターンを構成する単位
ターンは予測可能(projectable)な単位により構成されていなければならない。この単位には句・節など様々なものがあり複雑な問題である。この点は後で詳述する(projectivityの問題)。
■Turn-assignment rules:ターン割り当ての規則(1)~(5)
(1) ターンを与えられた話者は上で述べた単位を1つ発話する。この単位の終りは一般に推移-検索点?(transition-relevance place)と呼ばれ、この地点に到達すると(2)の規則が適用される。
(2) 現在の話者は次の話者へと発話の権利または義務を与えることができる。
・次の話者を特定したとき →規則(5)へ
・次の話者を特定しなかったとき →規則(3)へ
(3) どの人もターンを得られる。発話は自己選択(self-selection)により行われ、発話への義務は発生しない。
・誰かがターンを受け継いだ →規則(5)へ
・誰もターンを引き継がなかった →規則(4)へ
(4) さっきまでの話者が続いて発話できる(しなくてもよい。その場合会話は終了)。(1)に戻る。
(5) 次の話者が発話する。(1)へ戻る。
【例】Arnold: (1) 昨晩はよく眠れなかったなぁ。 (2, 3, 4, 1) (Bettyに対して…)
僕が階段を降りる音が聞こえたかい? (2, 5)
Betty: (1) ううん、聞こえなかったわよ。 (2, 3, 5)
Christian: (1) 家に強盗でもいるのかと思った。 (2, 3, 4)
この時点で規則4が働き、会話が終了した。
■原則として一度に話せる話者は1人である(規則(3)で複数の人が「引き分け」になったときは除くが)。1つの発話の長さは、上の規則に従っても、どんな長さにもなりうる。しかしこれは会話に参加している者が誰も発話をしなくて、1人の話者が引き続き話し出す場合にのみ起こる。
■規則(3)に関して、発言権は通例誰にもあることになるが、2者間の会話においてはこの権利はもう1人の話者に保障される形になる。
■会話には沈黙もある。沈黙には3種類あり、1つ目は単位内で起こるpauseで、2つ目は単位間に起こるgapである(p.33具体例を参照)。3つ目はlapseと呼ばれ、単位間の沈黙が特に長くなり、話の終りが来ている場合に現れるものである。
【例1】Arnold: Can we really (pause) afford to do this?
【例2】Arnold: He kept playing all night. (gap)
It is hard to stop an amateur. (gap)
Betty: Do you play an instrument yourself?
■上記のようなターン割り当ての規則に基づいた会話のモデルは理想化されたものである。というのは、すでに述べたように実際の会話では複数の話者が同時に話すこと(overlap)があるからである。これには2つの原因があると見られる。
原因①:multiple self-selection (規則(3)で複数の人が話し始めてしまう場合)
原因②:projection trouble (推移-検索点?を聞き手が誤判断してしまった場合)
※②は発話の最後に付け足しがある場合に起こりやすい(e.g. ~, dear. / ~, isn’t it? / ~, I think.)
■ターン割り当てのシステムの特徴は「ローカルマネジメント(local management)」である。つまり予めターンの割り当てをするようなchairman(=中央権力)は存在せず、ターンの決定は全くの自由であるか(すなわち、規則(3)が適用されている場合)、その時々のターンの間に決定される(すなわち、規則(2)で話者が特定された場合)。
■turn-yielding cuesとはターンの終りを話者が合図するときに用いるものである。
・prosodic cues:ピッチの変化(文末での上昇調や下降調など)
・syntactic & lexical cues
・rhythmic cues:ポーズや母音の長音化など(ex. He is ba:d.)
・nonverbal means:アイコンタクトなど
■推移-検索点(transition-relevance place)とprojectivityの問題について、すでに語・句・節などの様々な文法構造がこれを形成することは述べたが、言い換えればどの文法単位もprojectivityの指標にはなりにくいということである。Marslen-Wilson & Tyler(1980)の研究などにより、発話中の単語は全ての音節を聞くまでに予測可能であることから、単語がprojectivityの指標となりうる最小の単位である。またいわゆるinformation units(Halliday, 1967a)やidea units(Butterworth, 1975; Chafe, 1980)などの意味単位(総称してsemantic units)もprojectivityの指標となりうる。
■人が会話へ参加(engage)するときのわかりやすいきっかけは、規則(2)で次の話者が特定されたときである。“Morning sir - Good morning.”などの会話パターンはadjacency pairsと呼ばれる。一方、会話を継続させるには多くの方法があるが、代表的なのはうなずきなどのbackchannel behaviorである。
■会話からの離脱を合図するにもいくつかの方法がある。長いポーズや、副次的な行動(side activities:歩き回る、鼻をかむ)、儀式的結び展開?(ritual closing moves)である。
■ターン・テイキングの規則で重要なのは文法性ではなく、協力性(cooperativeness)である。この意味で、p.38にあるような規則違反の会話も会話への貢献が見られることから、無標(unmarked=normal ⇔ 有標:marked)であると言える。
2.1.3 Saying and Conveying
■協力性はターン・テイキングだけでなく、会話の内容にも適用される。Grice(1975)のthe cooperative principleでは次の4つの原理(maxims)を掲げている。
①Maxims of quantity:量の原理
1. 必要な情報を含むこと 2. 必要以上に情報を含めないこと
②Maxims of quality:質の原理
1. 「偽(false)」だと思うことは言わない 2. 適切な根拠がないといって偽りを言わない
③Maxim of relation:関連の原理
1. 会話の流れに関連したことを話す
④Maxims of manner:方法の原理
1. 表現の不明瞭さを避ける 2. あいまいさを避ける
3. 単刀直入に 4. 順序立てて
■以上で述べたようなターン・テイキングの規則や協力性の原理は、実際の会話では破られることはよくあるが、その場合にも何らかの意図が反映されている。
①maxim of quantityの違反に見える会話例
Arnold: Did you see Peter and Joan yesterday?
Betty: I saw Peter.
※Joanについては言及せず、Peterに会ったことだけをsingle outしている。Joanに は会わなかったことを含意している(implicature)。
②maxim of relationの違反に見える会話例
Arnold: My cough is getting very bad today.
Betty: There is a doctor across the street.
※医者の場所を述べることで、暗に診察をしてくれる医者の存在を示唆(implicature)
③maxim of qualityの違反に見える会話例
Arnold: (ハープの演奏について) How did you like it?
Betty: It was a nice piano recital.
※皮肉を表すと思われ、原理を私的に利用(exploitation)
2.2 Deixis
2.2.1 Types of Deixis
■deixis(直示)には以下の種類がある。(具体例はp.45)
・person deixis:人称代名詞のyouやIが誰を指すか。
※social deixis(独語のsieとduなど。ともにyouの意味があるが、話者間の関係で使い分け)
・place deixis:代名詞thisや副詞hereがどこを指すか。
・time deixis:時を表す言葉(beforeやyesterday)がいつを指すか。動詞の時制。
・discourse deixis:代名詞thatなどが談話ですでに出た内容のうちどれを指すか。
■直示表現は発話時のコンテクストと深い関わりがあり、Buhler(1934)ではこのコンテクストをindexical fieldと呼んでいる。表現の最終的な判断の根拠となるものはoriginといい、これに当たるのはperson originならば話し手、social originは話者の地位や役割、locative originは発話が行われている場所、temporal originは発話時の時間(今)、origin of discourseは現在の会話である。
■成人はこの話し手利己的な直示システムをうまく使いこなすが、子供にとっては難しい。言語学的分析のおかげで様々な発展の見られる直示システムだが、心理学の分野ではあまり注目されてこなかった。以下では空間-時間的な観点から、話し手が直面する直示表現の困難さについて触れていく。
2.2.2 Place Deixis
■場に関する直示には①identifying、②informing、③acknowledgingの3種類がある。
①identifying:
話し手は場所を指し示すことで空間(space)にある物体を特定できる。同時にthis, that, these, thoseなどの指示代名詞が用いられるが、どれが使われるかは「物体の話し手への距離(proximity to the speaker)」と物体の「数(number)」で決まる。demonstratum(例:花瓶)→referent(例:割れている状態)の2ステップで特定が成されるが、これには話者間の共有された知識が主に作用する。多くの場合demonstratumとreferentは一致するが、一致しない場合はspace deixisの他の2種類にとっては重要で、具体例は後に紹介する。
<コメント>
談話分析に関する知識があると読みやすそうな章である。ターン間に現れる2種類のポーズ、gapとlapseの違いが明確でなかった。
2009/06/11
Chapter 2 (pp. 48-55)
PDF参照
2009/06/11
Chapter 2 (pp. 55-62)
2.2.3 Time Deixis
・ 直示的な時間(話者の「今」を示す時間)はどんな言語でも表すことが出来る。tomorrow, today, yesterday等の副詞、また時制の有無も英語以外の言語にも存在すると思われ、特に英語に関しては時制は活用形で表現される。
・ 本来は直示的な時制(「今」)は話し相手同士で共有されるものだが、出来事が起こった時間(以下e)と発話がなされる時間(以下u)が一致するとは限らない。
過去形:e < u ( < …先行する) Francis was cashing the check.
現在形:u = < e ( = < …同時また(は)先行する) Francis is cashing the check.
⇒一次時制(primary tense: 話者の発話時を直接示す用法)
・ ただし、場所の直示表現で異なる場所の関係項が使われるのと同様に、異なるreference timeを使用することが出来る。完了系によって「過去の中の過去」を作る reference time(以下r)★以下の例においては、Peter が到着した時間がr
過去完了形:e < r < u Francis had been cashing the check (when Peter arrived).
その出来事が重要だった(もしくは重要になった)時間ともいえるので、r はrelevance timeのrともいえる。
また完了形からはrが話者の「今」に先行するものだとわかるので、この場合のeとrとの関係は直示的ではない。
・ なお例の中のPeterが到着した時間については必ずしも述べる必要はなく、ただhad been…とするだけでrの存在を話し相手に提示できる。
・ rの概念が単純な現在形や過去形の場合でも使われることを好む研究者は多い(Reichenbach, 1947ほか)その場合、以下のようになる。
現在: 直示的成分 r = u 内在的成分 e = r
過去: 直示的成分 r < u 内在的成分 e = r
過去完了: 直示的成分 r < u 内在的成分 e < r
・ 他の時制の場合
現在完了形: 直示的成分 r = u 内在的成分 e < r
Francis has been cashing the check (i.e., he has the money now).
⇒ 過去形と比較すると、cashing the checkという出来事が現在重要だということが
過去形では表現されていないことがわかる。
未来: 直示的成分 r = u 内在的成分 r < e
Francis will be cashing the check (by the time Peter arrives).
⇒ Peterの到着がrで、eはそれに先行すると考えられる。
未来完了形: 直示的成分 u < r 内在的成分 e < r
Francis will have been cashing the check.
(もしくは進行形なしに、Francis will have cashed the check. )
⇒ここでは話者はrを特に述べなくとも、聞き手にとってその存在は明らかである。
また未来完了には話者の未来に対する強い期待を表現するという側面がある
epistemic commitment(Lyons, 1981)
・ここまでは出来事(event)に関する場合を扱ったが、状態(state)の場合にも時制は使うことが出来る。状態の場合は多少持続的で、utterance time, relevance timeとオーバーラップする可能性もある。
・ 時制は直示的に時間を表すひとつの方法にすぎず、世界の多くの言語では副詞的用法が使われている(e.g. Today, yesterday…)。また多くの社会ではカレンダー時間が使われている(e.g. June 18, 1832)。しかし、例えば話者がWill you be here in June? と話した場合、聞き手はJuneを「今」から考えて最初のJuneと解釈するなど、カレンダー時間もある程度は直示的に使われている。
・ 時間に関する直示研究:Steedman (1982), Ehrich (1987) ほか
・ 日常会話は本質的に直示的で、話者たちはこれによって空間、時間に関する情報を特定することができる。このようなことが無意識のうちに流暢に行われるような能力については、これまであまり心理言語学的に注目を浴びてはいない。
2.3 Intention
2.3.1 Speech Acts
・発話は、ある特定のコミュニケーションにおける(自分の)意図を具体化するために産出されていると考えられる。全ての場合には適用されなくとも、多くは何らかの目的のために発話がなされる。このような発話の意図をillocutionary force(発語内の力)と呼ぶ(Austin, 1962)。そしてillocutionary forceに基づく発話はspeech actと呼ばれる。
・ それぞれのspeech actは何らかの意図を着想するところから始まる。先行する談話から生まれる場合もあるが、多くは情報が欲しかったり、何かを行う最中の助けを求めたりなど、異なる。全てがコミュニケーションの形になることはない。Speech actは(発話に関しては)意図を表現するただ一つの方法である。
・ Speech actsのもととなる意図(communicative intentions)は特殊なもので、聞き手は話者の発話を理解するだけでなく、この意図をも理解する必要がある。 communicative intentionは、聞き手によるintention recognitionを常にその目的として含んでいる。
・ ある意図がcommunicative intentionになるためには、そうであると他者に気づいてもらえるようでなくてはならない。例えば、話し手が聞き手を感心させるために何かを言う場合、それが自慢だと受け止められないようにするためには、聞き手がその意図を認識しないことが重要である。またさらに、発話の内容は聞き手にその意図を気づかせる上での手段であるべきである。
・ 全てのspeech actsが話者のcommunicative intentionを伝える上で効果的なわけではない。Speech actsの効果は(i) 話者が言う事(ii)その場面(iii)どのように言われているか(iv)聞き手の要因 により異なる。illocutionary force は話し手が発話において意図したことと定義されるため、聞き手の要因という点を考えると、聞き手が受け取った内容であると定義するのは間違いである。
・ Speech actsの例…話者が括弧内のillocutionary force を持って、それを伝える目的で伝達した場合 p.60.
Speech actsの種類は無限だが、いくつか主なillocutionary forceを特定できる。以下はSearle (1979)による分類。
(i) 断定
話者が、「何かがそうである」との自分の考えを明らかにするもの。
断定的なSpeech actであるために必須なSincerity condition(Speech actsの間で、illocutionary force を共有している必要がある):自分が断定した事柄に忠実でなければならない。
・ 断定の形は自慢する・結論付ける・文句を言う など様々で、その意図やillocutionary forceも変わってくるが、何らかの主張が真実であるとする自分の考えを明らかにする点は共通している。
(ii) 命令
聞き手に「何かをさせる」ことを目的とする。命令形のSincerity conditionは、聞き手にそれを命令するような正当な権利が話者にあり、かつ聞き手にそれをしてほしいということである。
(iii) 約束( commissives )
話者が未来における自分の行動を約束するもの。ここでのSincerity conditionは、その行動を話者が行うとする意図があることである。
(iv) 感情表現
話者が、自分と聞き手(もしくは自分または聞き手)についての関心事について、自分の感情を表現するもの。ここでのSincerity conditionは、話者が表現された感情に忠実であることである。
(v) 宣言
宣言されたことを現実に反映することが目的とされる。ほとんどの場合、宣言は話者が持つ何らかの社会的な役割によって効力を発揮するが、「私は…と定義する」というような場合はそうではない。Searleによれば宣言はSincerity conditionを持たないが、宣言は話者の意図によるものなので、話者が宣言によって何かが変わると信じることがsincerity conditionとも言える。
<コメント>
・このあたりから英語学の色が強いが、スピーキングの主要な役割について述べてあるので理解することが必要。
2009/6/25
Chapter 2 (pp. 62-69)
☆Searle (1979)によるSpeech actsの分類:断定・命令・約束・感情表現・宣言
以上のillocutionary forces のsincerity conditionsについては、話者の心理的態度が含まれ、それは以下の2つである(Lyons, 1981)。
① epistemic(認識論的) commitment
自己をなんらかの事実へcommitすること。
⇒断定(ある説を事実だとする)、感情表現(表現された感情が実在するとする)
② deontic(義務論的) commitment
何らかの行動の必要性に基づく、望ましさの度合いへのcommitment
⇒命令(話し手になにかして欲しいと望む)、約束(自身がそのように行動することの必要性に基づく)、宣言(そのような状態を変えることを約束する)
・ このようなcommitmentにはそれぞれ異なる度合いがあり、epistemicについては法助動詞、副詞相当節、イントネーションの違いなどの方略によって表される。deonticについても同様。
・ しかしこのようなspeech actの種類は、話者が行うことが文化によって異なることを考えると、普遍的でも完全でもないといえる。話者が行うことは文化によって異なるため。
2.3.2 Speech-Act Type and Sentential Form
・ 話者がその意図をどのように言語形式に変換するのかについては、スピーチ行動の種類と話者が発話した文との間の体系的な関係を分析することが重要である。
その関係の存在については多くの研究者から支持されてきたが、1つのillocutionary force が1つの文形式に対応するという説には著者は反対している。
以下に、そのような観点から規則的な例とそうでない例が示される。なお、ここでの規則性とはあくまで慣習的なものであることに留意したい。
Sentence types
・ 世界の言語における主な文の種類(type:moodとも呼ばれる)は、宣言文・疑問文・命令文(Sadock & Zwicky, 1985)
⇒動詞の法(mood)に反映されることが多い。
・ 宣言文(動詞:直説法)
断言、宣言に使われる epistemic commitment
・ 命令文(動詞:命令形、または命令を示す特定の語順)
命令、禁止に使われる deontic commitment
・ 疑問文(特定の動詞の法はなくとも、語順・イントネーション・不変化詞などによって指示される)
deontic commitment
・ また未来形についても、話者の行動を未来に置くことによって間接的にそのcommitmentが示唆される。また、話者が断定を行う場合のその正確性についても未来形で表現される。
・ 以上に述べてきたように、いくつかの文の種類は特定のスピーチ行動に関係すると考えられるが、Searleの5つのスピーチ行動にそれが1対1で関係しているとは言えない。その関係はもっと文脈依存的なものであるといえる。
実際上はどんなスピーチ行動でも、それぞれどのような文を使ってでも実行することができる。ただ、少なくともスピーチ行動と文の種類の間の対応には傾向は存在するようである。
Performative verbs
・ 遂行的動詞(e.g. state, believe, conclude…)は、話者が持つ意図のillocutionary forceを表現する上で一番直接的な方法である。
多くのスピーチ行動で遂行的動詞が使われるが、例えば *I boast that… の例からわかるように、遂行的動詞が使われないillocutionary forceもある。
・ 遂行的動詞を「心理的動詞」と呼んだDeese (1984)によれば、遂行的動詞は直接的にillocutionary force を表すために、自然発生的な談話で頻繁に使われる。
2.3.3 Politeness and Indirect Speech Acts
・ ここまで見てきた直接的な言語方略は、会話の協同的な性質からはかなり異なると考えられる。
また、会話で起こりうるような衝突に対処するため、文化によってポライトネス・儀礼的行為の複雑な体系が作られてきた。
・ ポライトネスは特に命令形ではっきりと表される。
(例)(1) Send him a bunch of flowers.
相手がそれを(2)できるか、(3)したいか、または(4) 質問そのものを聞いてくれるかどうか、を聞くことができる。↓
(2) Can you send him a bunch of flowers?
(3) Would you mind sending him a bunch of flowers?
(4) May I ask you to send him a bunch of flowers?
・ このような質問は、①相手の状態に対する話者の心配を表し、②その行為をしてほしいという依頼を行う、という2つの機能を同時に行っている。
・ 疑問文とは、相手に情報を提供してもらうための指示・命令であるといえる。
但し、頼まれたような内容を行う能力や下地が相手にあるとすでに話し手がわかっており、かつ相手がそのことを予測できるような場合は、話し手が間接的な依頼(indirect request)を行ったことなどが考えられる。
この現象が起こる理由については、指示内容に相手が応じないのではないかという話し手の疑念が考えられる(Herrman, 1983)。
・ 相手が協力的な場合は指示内容に応じてはくれるが、質問そのものと暗示された依頼の両方に答えることは珍しくはない(e.g. Yes, I’ll do that.)。Clark (1979)の研究では、疑問文が慣例的でないほど、暗示された依頼にだけではなく質問自体にも答えていた。
・ このような結果から、疑問文が慣例的であればあるほど、話者の意図の曖昧さを減少させることができることがわかる。
・ しかし、Clarkの研究からは、慣例的な形式でなくとも依頼している意図は伝わるという事が分かる。
・ このようなスピーチ行動の暗示はなにも依頼に限ったことではなく、文脈と協調の原理がはたらいて話者の意図が相手に伝わりさえすれば、すべてのスピーチ行動が間接的になりうる。( p.67の例)
・ また、遂行的動詞などについても間接的に使用され得る(p.68の例)
・ このように間接的なスピーチ行動はさまざまな形を取るが、特にプロソディ・パラ言語においてはその数は多い。(e.g. So, you are going to the station)
・ この項のまとめとしては、意図の発話には慣習があるものの、発話をどのようにスピーチ行動に変換するかといった固定的な法則は存在しないということが言える。
Summary
・ 本章では、会話を行う者としての話者について紹介した。会話が行われる際には、話者のターンの規則、会話に貢献する規則などがあり、これらはGrice’s maximsと呼ばれる。
・ 会話の参加者は、非言語的な空間・時間的直示も共有する。
・ 特に時間的直示については、本章では時制について多く述べられた。
・ 会話への参加は話者の意図に基づいており、それは直接的・間接的な方法で伝えられる。
<コメント>
・ illocutionary forceは、発語内の力、または発語内効力と訳されるようである。
・ 遂行的動詞とは、動詞の中でも意図が関わっているものをさすのではないだろうか。
2009/6/25
Chapter 3 (pp. 70-82)
PDF参照
2009/07/09
Chapter 3 (pp. 82-90)
・ MANNERやPROPERTYのような特定の範疇の働き。
・ 完成されたfunction / argument structureは、MANNERやPROPERTYのような修飾語句により一層、特定化(specified)され、限定(qualified)され、定量化(quantified)される。
・ Joe put the key under the doormat. は完全な概念構造(conceptual structure)で、全ての項(arguments)が特定化されている。しかし、EVENTに関しては、Joe quickly put the key under the doormat.のように、より限定することもできる。
・ THINGsも修飾(その赤い家)したり、定量化(2つの家)することができる。ほとんどのその他の範疇に関しても修飾は受け入れられる(修飾することが可能)。
・ しかしmodification(修飾)のひとつの特徴として、範疇は変わらない。修飾されたEVENTはEVENTという範疇のままであり、修飾されたTHINGもTHINGの範疇のまま変わらない。→ この修飾の特性についてはtype theoryの中で簡単に説明が可能(詳しくは3.2.6参照)。
・ modifier / headとfunction / argumentについてのさらに詳しい解釈はHawkins (1984)を参照。
・ 意味グラフ(semantic graph)の中で、修飾は破線(broken line)で表される。以下(p.83)に示すのは、修飾されたTHING、PLACE、EVENT、PROPERTYの例。一見すると修飾の種類が同一のように見えるが、重要な意味的違いが隠れて存在する。
・ (例)a red houseとa big houseの違い。a red houseは家が赤い、という意味のままだが、a big houseは他の建物と比較すると小さい家にもなり得る。PROPERTYの修飾とMANNERの修飾の場合もまた異なる。 ⇒ 修飾は破線で表されるが、意味修飾の種類が必ずしも同じとはならない。
・ 意味グラフの中に示された番号はtoken entitiesについて言及するために著者が加筆したもの。
・ type theoryに入る前に、Jackendoffのtype/token distinctionについて次のセクションから説明する。
3.2.5 Types and Tokens(pp.83-86)
・ JOHN, JOE, CYNTHIA, and HARRY という概念 = (実際の存在するかしないかは重要ではなく)individualsに該当。同様に、TREE17, KEY1, and DOORMAT3もindividualsもしくはtokens。
・ token PLACES (特定の場所, e.g., in the tree)
・ token STATES(特定の状態, e.g., Peter’s being in the tree)
・ token EVENTS(特定の出来事, e.g., John’s coming by plane)
◎ type(異なり語数)か、token(総語数)か?
・ 発話者は排他的にtokenやindividualsについて話すのではなく、typesについても話すことができる(tokens ⇔ individuals)。
・ John came by plane.の文では、planeという語は特定のPLANEを指さない。Jackendoffによれば、これはそもそも移動手段のtypeということしか示していないことになる。
・ Cynthia is a girl.と言った場合Cynthiaは特定のindividual(token)だが、girlはtokenではなくtypeを示す。⇒ CYNTHIAがgirlというtypeの例である。Cynthia is a girl. But the girl behaves like a boy. のように後続する文があった場合、the girlは既に登場しているindividual=CYNTHIAである。
・ 発話者の発話の中で示すのはtokens (individual PERSONs, EVENTs, THINGsなどなど)だが、これらのtokenは暗示的もしくは明示的にtypeの例となる。
・ 発話者がCYNTHIAをCynthiaという言葉で紹介するとき、聞き手(addressee)は、発話されたindividualがFEMAL HUMAN BEINGというtypeであると暗示的に認識する。
・ 発話者はCYNTHIAについて述べる際、 my dog Cynthiaということにより聞き手がCYNTHIA = FEMAL HUMAN BEINGと判断するのを防げる。
・ cooperative discourseのためには、typeに関する知識を共有することが重要となる。
・ 対話者のほとんどは話されたindividualsのtypeに関する相互知識を前提とする。
・ 必要であれば発話者は、聞き手側の(暗黙の)typeに関する推測に期待することもできる。
・ a particular CHAIR is of the type FURNITURE
・ a particular DOG of the type ANIMAL
・ a particular EVENT is of the type THEFT (Peter’s silently picking Robert’s pocket.)
・ type / token distinctionは、推論したり、意図を表現する際に不可欠なものである。
・ typesとtokensの間は柔軟に行き来することができる。
・ 発話内容に関して、tokensのみがtype informationをそれとなく含有するわけではないが、typeはtoken exemplarsにより意識される傾向=個別化される傾向を持つ。
・ BIRDやGAMEと聞いたとき、何か特定の鳥(e.g., a robin)やゲーム(e.g., baseball)について想起しないことの方が難しい。
・ Johnson-Laird (1983) ⇒ tokensの操作。それぞれのtokenからtypeが作成されるのであれば、typeの数に制限はない。
・ CYNTHIAがtoken individualであるならば、GIRL LIKE CYNTHIAというのはtype。PICASSOがindividualであるならば、a Picassoというのは絵の種類というtype(これらに関する詳しい情報はClark & Clark, 1979参照)。
・ それぞれの範疇の中に含まれるメッセージというのはtypeにもtokenにもなり得る(これまで挙げた例では、数で表したもの以外は明らかではない。p.85に示す意味構造はtypeとtokenについて明らかに示したもの。)
3.2.6 Semantic Types (pp.86-88)
・ 特定の種類のメッセージ=意味範疇。
(1) What happened? John fell. EVENT
(2) Who fell? John PERSON
・ (1)の場合、John fellというのは真とも偽ともなり得る完全な命題で、発話者が心の中で思っている、何らかのある状況(事柄)である。これにはtruth value(真偽値)があるので、type theoryの中のtype tに属する表現である(完全な命題のみがtype tとなり得る)。
・ (2)の場合、Johnという答えの真偽は質問によるものであり、それ自体に真偽値はなく、指示表現(referring expression)にすぎない。
・ 表現は個々の構成要素を示すもので、PERSONsやTHINGsというのはtype theoryの中でtype eとして表される。Johnという答えが正しいかどうかを判断するには述部が必要となる。
・ John fellの場合、fellという述部の存在により、答えに真偽値を持たせることができる。
FALL type〈e, t〉 JOHN type〈e〉 FALL (JOHN) type〈t〉 ⇒ type theoryの表現方法。
・ type 〈a, b〉= aに当てはまる、type b の表現(expression)ということになる。
(例)function IN は type〈e, p〉となる。THINGに当てはまり、PLACEを生じるので=type pとなる。
・ その他もa とbがtypesであるならば、〈a, b〉がtypeとなる、という単純な組み合わせの法則により表される。
・ 一項で一次の述部は全てtype〈e, t〉となる(e.g., FALLの場合)。
→ 〈 〉内に含まれるものが、それぞれ個別にtypeを示すのであれば〈 〉はtype ということになる。eがtype なら〈e, e〉もtype。
・ individualsに当てはまるindividualsという場合の例は、MOTHER OF (JOHN)、PRESIDENT OF、
FRIEND OFなど。
・ 同様に〈t, t〉もtype。命題全体を修飾するようなNOTを用いた、NOT(FALL(JOHN))というような場合が挙げられる。 ⇒ この際、時制も重要。過去のことについて述べる場合は、NOTではなく今度は、PASTが用いられ、PAST(FALL(JOHN))となり、この場合Formulatorは正しい動詞の時制(fell)を選択するという複雑な状況となる。
・ 時制の決定には、deicticなものとintrinsicなものの2つが必要。どちらもtype 〈t, t〉
・ 発話者がJohn skated fast.という内容を説明するために、述部SKATEを修飾したいという場合、SKATEはtype〈e, t〉だが、FAST(SKATE)となるので、individualであるJOHNに適用され、真偽値を持つ表現となる。FASTはtype〈〈e, t〉,〈e, t〉〉となる。述部を述部に入れて修飾。
・ 3.2.3で示された修飾に関していえば、全てtype〈a, a〉ということができる。
・ type theoryの中では、修飾語句(modifier)というものは、semantic typeを同じsemantic typeで示すものである(a)。
・ LOVEがJohnの述部で、he loves Maryを示す場合はどうだろうか?LOVE(MARY)がone-place predicate (type〈e, t〉) となる。LOVEはtype eの構成要素となる。LOVEはtype〈e,〈e,t〉〉となる。three-place predicateであるGIVEの場合は、type〈e,〈e,〈e, t〉〉〉となる。この場合、真偽値を持つtype〈e〉の3つの項が必要。⇒ John gave Mary the book. (MARY, BOOK, and JOHNという3つの構成要素)
・ EVENTやSTATEという範疇は、常に同じsemantic typeを表すものとはならない(John skatedとJohn’s skatingの異なり)。根底にあるメッセージはtype〈e〉のSKATE(JOHN) event-proposition
・ BEAUTIFUL(SKATING(JOHN)) type〈e, t〉 John’s skating is beautiful.
・ SKATING(JOHN) type〈e, e〉 MOTHER OFと同じ構造。
・ 発話者が出来事を構成要素として意図する発言(type〈e〉)をした場合、Formulatorはそれを名詞句として表す(John’s skating)。⇒ メッセージ内容はevent-entitiesとなる。同様にstate-entitiesに関しても、John’s becoming a doctor.のように表すことができる。
・ type theoryとは、意味論と統語論を自然言語にできるだけ近づけようとするもの。
・ メッセージのsemantic typesに階層性を与えることにより、Formulatorはどのような統語的な構成要素を全てのメッセージの中でもたせるかを理解する。
・ メッセージがtype〈t〉の場合、Formulatorは文を作ろうとし、その中にtype〈e〉が含まれれば、Formulatorはその箇所に関しては名詞句を作ろうとする、など。
◎ 全て正しく表現されるまでには長い道のりが必要(Williams 1983 and Partee and Rooth 1983参照)。
3.2.7 What Are Possible Messages? The Problem, of Ellipsis (pp.89-90)
・ 意味的構造(semantic composition)の規則に従って構築された概念構造=メッセージ? Yes.
・ これまでの例に出てきたfunction / argumentとhead / modifierの構造すべて=メッセージ? Yes.
・ 指示対象について述部を与えない場合でもメッセージとなり得るか?
・ LIZがメッセージとなり得るか、それともWALK(LIZ)のような何らかの断定を持つか?
・ 単なるPERSONの概念としてのLIZはメッセージとなり得る。⇒ (例)Who did Peter visit? と聞かれた場合の答えとしてLiz.と答える場合。⇒ PAST(VISIT(PETER, LIZ)となるか、LIZか。もし前者で考えた場合、Formulatorはその他の大部分のメッセージを破棄してLIZのみを残す必要がある。
・ 最初に多くの概念構造を生み出さなくてはならない無駄のように見えるこの手順は、実際に行われていることである。
・ 後者のようにLIZという情報を残す場合。発話者はPeterが誰かを訪ねている、そのことについて答えなくてはならないということを考えているが、表現としては考えていたことは反映されなかった。=ellipsis problem(Bühler, 1934)と呼ばれる。
・ Who did Peter visit? という問いに、herというLIZの代名詞を用いて答えることもできる(対格を踏まえて、sheで答えることは不可能)。
・ しかし、LIZとしか答えられなかった場合、Formulatorはどのようにして対格を見つけるのか?⇒ LIZがある行為を受ける対象(patient)だと断定できるのはなぜか?対格が反映されるとは限らない。
・ その判断をするためには、動作を表す動詞、visitが用いられる。 対格に関する判断。
・ しかし、VISITがメッセージ内に含まれない場合、Formulatorはどのように判断するのか? ⇒ 対話者(質問をした相手)の質問内容における表現から判断する。
・ メッセージというものは、命題、構成要素、述部、修正語句、などのその他のsemantic typeによって示され得る。
・ 細かく分析をする必要のない発話というのも存在する(e,g., yes, congulatulations, ow!, and please!?)
(例) Is John asleep? と聞かれたときに、yesと答える場合。
・ ASLEEP(JOHN)という真の命題を表す。⇒ TRUE(ASLEEP(JOHN))を示している。
→ しかし、メッセージは省略され、その概念が真であるということのみ伝えられる。type theoryによれば、このyesというメッセージの根底にあるのは、type〈t,t〉である。
<コメント>
type theoryについて調べないと理解できない点が多かったが、メッセージの内容を発する側と受け取る側で、共通理解が得られないと、談話を進行する上で問題が起こりうるのは当然だと思った。非常に興味深いので、木構造の中身をもう少し詳しく理解したいと思った。
2009/07/30
Chapter 3 (pp. 90-106)
3.3 The Thematic Structure of Messages (p.90)
・ function/argument structureの中のarguments(項)は、概念構造の中の何らかの概念的な役割(roles)を果たす。→ それらの役割はかなり制限された全体集合(universal set)の中から選びだされている、と幾名かの研究者が指摘。メッセージ内の役割分担はthematic structure(意味構造)と呼ばれる。conceptual roleの概念は、主に動き(motion)と場所(location)の概念の枠組みに分類される。
3.3.1 Thematic Roles (意味役割) (pp.90-94)
・ The ball is in the garden.の場合。
・ state-proposition BE (BALL3, (IN (GARDEN7))) THINGとPLACEと関係している。
・ BALL=theme, IN (GARDEN) =location
・ The ball rolled from the chair to the table.の場合。 path functionsと呼ばれる項が存在する。
・ path-functionとは、source goalとなるもの。
・ theme (BALL) CHAIR TABLE ◎CHAIRからTABLEにBALLが横断。
PATH
・ あるPLACEから、起点:source(CHAIR)から別のPLACEである着点:goal(TABLE)へと移動。
・ この場合のpath function FROM /TOはCHAIRとTABLEの2つの項を持つが、それぞれは1つだけ項を持つ(sourceかgoalのどちらか)。
・ このようなfunction/argument structureは、The ball rolled to the table.というような文の場合、goalのみが特定されていることになる。
・ DIRECTIONs は参照物体(reference object)を含まないpath。ある場所から、どこかへ向かっていくか立ち去るかを示す。
・ Frederick pointed toward the sun and Little Red Riding-Hood ran away from the wolf. の文の場合、SUNもWOLFもPATHの一部ではない。
・ このようにpath function (direction functions)はTOWARDとAWAY FROMであり、それぞれ1つの項を持つ。
・ さらにagent (動作主)を追加して考える(動作主は空間的ではない)。 agentはcausative eventsの中で明らかになる。CAUSE (PERSON, EVENT)
・ The witch fed Hansel.の場合、witchがHanselに食べさせたので、witchがagentとなる。この因果関係(causation)は意図的かどうかで意見が分かれる。もしagentivity(動作主性)に必ず意図性が必要であるとすると、THINGsはagent になれない。因果関係が前提であるということだけにすれば、THINGsもagentになることができる。
・ The root made Tom Thumb tumble. という文の場合、EVENTはTUMBLE (TOM THUMB)で、TOM THUMBはtheme。 EVENTはTHING: ROOTによって引き起こされた。 意図性は認められない。 つまり… ★agentivityには因果関係が必要になる。
・ actor(行為者)という意味役割も存在するが、agentと混同してはいけない。ActorはACTIONを必要とする、と定義づけることができる。特定のEVENTsはACTIONsを引き込む。
・ What x did was….を用いての書き換え(paraphrase)。
John put the key under the doormat What John did was put the key under the doormat.
・ この場合actorはJOHN。 EVENTはPERSON (the actor) と人が何をした(ACTION)か,を含む。
・ EVENTとACTIONには因果関係が認められるため、LET (PETER (FALL (MILK))) となり、この場合のPETERはactorにもagentにもなり得る。
・ agentかactorの違いは、因果関係があるかどうか。 actorはagentにもなり得るが、因果性が無いと、agentとなることはできない。
・ 意味役割のその他の(あまり均一に分析されない)4つを説明する。
・ patient (animate entity:有生の構成要素) ACTIONとのみ関わりがある。
(例) Gretel(行為をする) grabbed Hansel(行為を受ける).
・ recipient (animate entity:有生の構成要素) 何らかのACTIONの中で、themeを受ける側。
(例) The witch gave Hansel a hamburger. の文の場合、Hanselがrecipientの役割を担う。
・ experiencer patientとrecipientに似ている。人を主語とするstate(状態)やexperience(経験)。
(例) Hansel was hungry. / I don’t know the play well enough.
・ instruments 道具的概念の含まれるもの。MANNERの概念カテゴリーの中に表れる傾向がある。
(例) John came by plane. / I opened the door with the key. PLANE, KEY
◎theme([移動]対象)とは、身体的また精神的「空間(space)」の中で、集められたり移動させられたりする項(argument)のこと。その空間の中で、sourceとgoalは、位置参照(reference location)である。
◎agentivity(動作主性)は因果構造の中における最初の項の特徴である。
◎actorは何かを「する」項のこと。
◎patient(被行為者)は何らかのACTIONにさらされる有生の構成要素。
◎recipientはthemeを受け取る。
◎experiencer(経験者)は状態や経験の有生の主語。
◎instrument(道具)は何かのACTIONの影響を受けるもの。
・ 意味役割を概念や範疇と混同してはならない。
・ 意味役割を概念や範疇と混同してはならない。
・ themeは様々な範疇によって満たされるものである。
・ location, sourceとgoalの役割も、様々な項によって満たされるものである。
・ 項の意味役割(thematic roles)はもっぱら項の機能(function)によって決定づけられる。
・ その場合、どのようにして、異なる機能が同じ意味役割を引き出すのか?
・ HITやSPILLは最初の項をagentとするか?
・ メッセージ構造の中で明示的に意味役割が示されていない場合分かりにくい。
・ agentの役割は、根底にpredicate CAUSEを必要とする。 最初の項にはagentがくる。
・ actorの役割もこれと同様に、何かを「する」というのがactorだが、そこには根底にpredicate DOが隠されている。
・ sourceとgoalに関しても根底にpredicate FROMとTOが隠れている。
・ あるものが何かをして、何かを生じさせる場合=agent でありactorでもある。
(例) John teaches Peter the alphabet.
Johnは教えている それが、Peterにアルファベットを覚えさせた。=Johnはactorでありagentである。
・ このような場合、メッセージはある程度まで意味的に分岐する。
・ Gretel killed the witch. が predicate KILL (X, Y) を根底にあるメッセージとして含まないとすると、CAUSE (X, DIE (Y)) のようになり、Xは動作主(agent)となる。
・ しかし「殺すこと」が大抵「死」を引き起こすということが言えるが、さらにこの知識(殺すこと=死なせる、への理解)が、動詞の前にある(preverbal)メッセージの明示的な部分となる。
意味的な分岐には終わりが無いという問題が生じる。
・ DIEは「生きない」ということになり、BECOMEは「細かく伝えなくてはいけない時間相(temporal aspect)」、などなど。 このようにカットオフポイントも曖昧であるが…
◎speakingの過程を考えるならば、全か無か(all-or-none)という事態は起こらないということ。
・ むしろ、どのような意図を媒介しているかの方が重要。
・ ある意味部門(semantic components)や述部(predicates)には、より高次の突出(saliency)や活性化(activation)が(他の人と比べて)話者の心の中で起こっている(lemmasにアクセスするときの突出や活性化の重要な役割については第6章を参照)。 あるレベルにおいての意味的な分岐はメッセージの描写の中で維持され、この突出は心の中で保たれるべき。
・ spelled-out message structureは、“ideal cases”であり、話者の心の中で突出するであろう様々な構成要素を引き込む。
3.3.2 Semiotic Extension of Thematic Roles (pp.94-95)
・ 意味役割は身体的な動きや行動に関する意味表象の中だけで暗示的なわけではない。 その他の概念領域(conceptual domain)においてもよく表れている。
◎時間の領域では顕著に表れる。
・ Helen worked from nine to five. という文を例に挙げる。
★EVENT Helen worked, = theme 2つの時間に関する基準点(9 and 5 o’clock)を持つ。
★source TIME = 起点となる9 o’clockからFROM-argument によりPATHが伸び、goal TIME = 着点となる5 o’clock (the TO-argument)へとつながる。
★過去形はEVENTを表現し、一時的なPATHが横断し、話者の“now”を先導する。 時制は話者の時間的展望(time perspective)のDIRECTIONを表現するものである(過去に向かっての“points”)。
・ 三次元空間の中で、EVENTsとTHINGsだけが位置する場合、時間的領域は一次元空間となる。EVENTsは瞬時的にもなり得る(he arrived at five)。THINGs/PERSONsがreference PLACEに位置する場合(he arrived at the airport)。EVENTsは空間におけるPATHを横断して、時間を超えて広がることができる(She worked from nine to five; The road twisted from Zermatt to Saas Fee)。
・ TIMEがactor(行為者)の役割をすることは極めて稀であるが、不可能とは言えない。
・ Tuesday crept by. の文の場合。分岐した意味表象では根底にDOがある。 DO (X, CREEP BY (X))となり、XはTUESDAYもしくはTRAINとなり得る。
the decomposition hypothesisによれば、Xがどちらを取る場合においてもactorshipを説明している、ということになる。
・ McNeill (1979) “semiotic extension”… マトリクス状の“sensory-motor ideas”
・ have, keep, give, そしてtakeに見られるような動詞の所有。
・ 文例 Tanya gave the book to Martin. を分析する。
3.3.3 Some Concluding Remarks (pp.95-96)
・ conceptualizerはメッセージをアウトプットとして産出する:propositions, predicates, entities, そしてmodifiersなどの異なるタイプの表象となり得る。
・ 経験という範疇の中で、EVENTs, STATEs, THINGs, PERSONs, ACTIONs, PLACES, PATHs, そしてMANNERsとして構成要素は表される。
・ function/argument structureとhead/modifier relations、定量化、変数の結合、同じ構成要素に関する繰り返される照合(repeated reference)などが階層的に組織されていると考えられる。
・ 限定されたabstract roles: theme, source, goal, agent, actor, patient, recipient, experiencer, そしてinstrument. これらの役割は、根底にある述部に依存していると考えられる。
・ メッセージ内に、CAUSE (X, Y)があったとする。この場合、Xはagent。もしFROM (X)だったら、Xはsource、などというように分析される。
・ formulatorの行う処理は、メッセージのthematic structureに説明を加える。
・ 意味的分岐に関しては、話者のメッセージを具体的にする、根底に存在する述部はどの程度なのか、について扱ってきた。 all-or-noneではない。様々なsaliencyやactivationがある。
・ 時間の配列がleft-to-rightであることに特別な決まりがあるわけではなく、あくまで表記規約上のことであり、これはset-system (Levelt 1974, volume2を参照せよ) と呼ばれる。
・ 受け取るメッセージに関しては、活性化の順序はさらに様々に異なると考えられる。
・ Wundtの原則によれば、formulatorは最初に可能な箇所から働きはじめ、活性化の順序は文構造に影響を与える。
3.4 Perspective and Information Structure
3.4.1 Nuclear Thematic Structure (pp.96-97)
・ メッセージの中の主題関係(thematic relations)が、話者にとってのimportance, saliency, またはcentralityによって異なる。(目立たせる箇所、そうでない箇所) 話者が概念構造を何らかのperspectiveに持ち込む(Fillmore, 1977; MacWhinney, 1977)。 異なるperspectivesは同じ意味構造の中でも異なるformulationsへと導かれる。
・ 3.3.2の例を参照 Martin received the book from Tanya. とTanya gave the book to martin. という2つの文は同じ意味構造を持つが、perspectivesが異なる。前者はrecipientからのperspectiveである。後者はagentを出発点としている。もし話者がagentの存在を無視するのであれば、表現はMartin received the book. となる。
・ Fillmore (1977) nuclear elements 主要な文法機能の中で符号化される:subject, direct object, おそらくindirect object。
・ 背景にある要素はさほど重要でなく、しばしば随意的な文法機能ともいえる。=oblique functions
・ Fillmore (1977)からの例。
(1) I hit the stick against the fence.
(2) I hit the fence with the stick.
・ (1)は、I (SPEAKER)とSTICKがforegrounded またはnuclear elementsとして、話者のメッセージに含まれている。
・ (2)は、I (SPEAKER)とFENCEがforegroundである。
・ 両方の場合とも、nuclear elementは主語と直接目的語である(nuclear elementでないものは、minor grammatical function)。
・ 話者にとって何が、nuclearなのか?nuclearであるためには、major grammatical functionsでなければならない(Fillmore)。詳しくは第7章で扱う。
・ メッセージのtopicについてより考慮していく必要がある。
3.4.2 The Topic (pp.98-99)
・ 話し手(話者)は聞き手に理解させなくてはならない(どのreferentについて話すかということ)。
・ 例(p.98)はevent-propositionの場合。
・ VISITが2つの項を取る。PERSONi (the agent), PERSONj (the patient)。
・ メッセージの真偽値(truth value)は重要ではなく、どちらがpredicationをもたらすかによって、心理的に違いが生じる。PETERかLIZか?
・ 会話の中のトピックが重要。 sentence topic …formulatorの活躍。
・ TOPIC = X このXはtopic argument
・ 例文ではLIZのこと。 TOPIC = LIZを加える。
・ メッセージ内の全ての構成要素がトピックになり得るわけではない。
《トピックとは…》
・ トピックはメッセージのnuclear elementsであるべき。(会話文の例参照)
・ どの対象について述べているか、指示的でなくてはならない。
・ 会話の中で、トピックは既に与えられた情報(given information)なのか? そうではない。
(例) Constantine wrote more than sic hundred compositions.
・ 4.2.2ではトピック使用の制限について扱い、より広い概念となる、discourse topicについて扱う。
3.4.3 Givenness and Inferability (pp.99-100)
・ 代名詞化
(例) I saw John. He was at the meeting. The pope was here today.
・ 推測が可能であるかどうか。
3.4.4 Focus (p.100)
・ 話者はメッセージの中で何が、新しい情報なのかを示す。
・ focused informationについて述べるときに、話者が使う方法。
① to give it pitch accent
② to put it an the end of the sentence
・ focus shiftの例
(例) Peter saw much of Mary recently. But yesterday he visited LIZ.
・ 会話の中のinformation structure(情報構造)
・ 話者は何らかの注意を引くようにしてメッセージを創り出す。 聞き手は話者が意図した推測を行うことができる。
・ message-levelの中でのgrammatical encodingについては次の節から扱う。
3.5 Mood, Aspect, and Deixis (pp. 100)
・ Formulatorの手続きは(とりわけ語順と動詞形態に関わるが)、メッセージ中のmood(法), aspect(態) そしてdeixis(直示)に依存している。
3.5.1 Mood and Modality (pp. 100-102)
・ メッセージが平叙文(declarative)か命令法(imperative)か、疑問文(interrogative)の発話が意図としてあるか、特定されなくてはならない。
・ interrogative moodのときは、polar interrogativeなのかcontent interrogativeなのかを区別する。
・ マークされていないmoodは平叙文である。平叙文のmoodは、はっきりしない方法(neutral way)、または特権化された方法(privileged way)で、(何かを主張したり宣言したりする)epistemic commitmentを作り出す。⇒ DECL
◎時制のように、proposition-modifying functionと扱うことができる。発話者は動詞の前にあるメッセージを伝えることができる。(例) John fell → DECL(PAST(FALL(JOHN)))
・ mperative moodのとき(Let us goやGo away)は、deontic commitmentを示す。
(例) I want you/us to do something.
⇒ ある事柄に関する望ましい状態(that we goやthat you goのように)を表現する(Wilson & Sperber, 1988)。(その望ましい状態に)聞き手は含まれなくても良い。(例) Get well soonは、望ましい状態。
・ imperative markerを使って表現する場合。⇒ IMP (例) Let us go IMP(GO(WE))
・ 話し手が何らかの情報を知りたいとき(なんらかの情報や考えにおける望ましさを表現したいとき)、interrogative moodのメッセージを構成する。
★polar interrogative (極性疑問文:Yes-No 疑問文)
★content interrogative (不十分な情報について答えさせる:WH-疑問文)
・ 疑問文がどちらに当てはまるか(polarかcontent1か)は分かりきったことなので、記号は“?”を用いる。
(例) Did John fall? ?(PAST(FALL(JOHN)))
・ ある情報に関するdeclarative moodには曖昧性が見られないので、DECL markerは除外する。
・ よって、PAST(FALL(JOHN))は、declarativeと解釈される。
・ ModalitiesはFormulatorに、modal(法性の)verb(can, may)もしくは“future” modals (will, shall)を選ばせる。
・ 態度の表現は考えている以上に複雑である。質問をするときに、上がり調子のイントネーションを用いることがある。(例) John came? 疑問文のDid John come? とは微妙に異なる。
・ declarative formであれば「驚き」またはJohnがこないであろうという「前提」を示す。
・ (憤り・皮肉・従順さ・興奮などの)感情的態度(emotional attitude)は(sentence melodyなどのように)韻律的な意味を持つ。
・ formulatingに関わる全てのものはメッセージレベルで符号化される。
・ 声色(high-pitchedであるかshrieky voiceであるか)は、別のルートを通って、音韻符号化(phonological encoding)や発音/調音(articulation)に作用すると考えられる。⇒ Phonological EncoderとArticulatorは発話者の態度にそれぞれ独立して敏感である可能性は捨てられない(第8章で扱う)。
3.5.2 Aspect (p. 102)
・ Formulatorは時間的な特徴に関しても特徴づける。durative(継続相)かpunctual(非継続相)か
(例) reading vs. hitting
・ 始まりだけなのか、反復の活動なのか。 aspectual
・ 英語のおけるaspectはsimple durationとprogressive durationのような文法的区分といえる。
(例) John read the bookとJohn was reading the book
3.5.3 Deixis (pp. 102-103)
・ 発話の中のdeictic anchoringはメッセージ内に含まれていなければならない。
・ 言語(英語・スペイン語・ドイツ語など)には時制のシステムがあり、時間についての言及は必須事項である。
・ 2つの時間関係(temporal relations):deictic(「今」と関連のある瞬間)とintrinsic(関連のある瞬間と出来事) ⇒ これらをPAST, PRESENT またはFUTUREと表現する。
・ 人と空間における直示的側面に関しても、メッセージ中で扱われなくてはならない。
・ 会話の中で、どちらの指示対象が発話者でどちらが聞き手かが符号化されている。
(例) Fritz is talking to Heida.
【発話内容の比較】
I want to ask you something.
Fritz wants to ask Heida something. (別のFritzと別のHeidaがいる?)
・ 発話の状況における存在と発話者自身との空間的関係に言及する必要がある場合も考えられる。
→ spatial deixisに関する正しい文法表現(2.2.2参照)
3.6 Language-Specific Requirements (pp. 103-105)
・ 指示対象語の近接性に関しては、言語による特性が見られる。
・ 英語(オランダ語)は2段階:PROXIMALとDISTAL
・ スペイン語・日本語は3段階:PROXIMAL, MEDIAL, そしてDISTAL。(ここ、そこ、あそこ)
・ 人間の空間の捉え方が、言語によって異なるということではなく、それぞれの言語にある表現の中で、空間の説明をしようとする。⇒ メッセージレベルにおける言語特性。
・ 時制のシステムを持たない言語も存在する。定形動詞の屈折としてのPASTやPRESENTなどの時制の特徴が必要とされないマレー語などの言語。
・ マレー語話者は、時間関係を別の方法で示すことができるが、英語の時制のように義務づけられているわけではない。⇒話し手が、時間関係を意図して話しているかどうかは定かではない。一方で、情報価値(communication value)が無いとしても、英語話者は時間関係を明らかにしなくてはならない。
・ オーストロネシアの言葉(Kilivila)は、分類の不変化詞の例。指示詞(demonstratives)・数詞(numerals)・形容詞(adjectives)は、修飾する対象の集合(class)に応じて接辞を用いる。(例)概念的な範疇。⇒ 形態論が成り立たない。
・ 言語は経験と共に獲得されていく。
・ 言語の情報処理システムが自律し、ConceptualizerがいちいちFormulatorにアクセスしなくてもよくなる。
<コメント>
メッセージの発信、受け取り、に関して非常に細かく説明があり、難しかったが、日常の会話の中に少し当てはめて考えてみたいと思った。
また、これまでメッセージを細かく分類してきた。おそらく会話が進行する上で人間は無意識にこれまで挙げられていたような分析をし、解釈をしているのだと思った。それが母語の場合は自動化された処理であろうが、第二言語や外国語となると自然になるまでには意識的な努力が必要なのだと思う。
Chapter 4 (pp. 107-123)
PDF参照
2009/09/17
Chapter 4 (pp. 123-144)
4.3 Macroplanning 1: Deciding on Information to Be Expressed
■ある意図を伝えるためには複数のspeech actsが必要な時もあるように、発話の意図とは階層的なものである。話し手が意図を伝えるということは聞き手の談話モデルを変化させることであり、あえて推測させることが情報の伝達に役立つ場合も多い。
4.3.1 The Format of Macroprocedural Knowledge
■macroplanningの理論的枠組み:IF-THEN型
例) SimonがHannaにWubboが宇宙飛行士だと伝えたい場合
IF = KNOW (H, INTEND (S, BELIEVE (H, P)))
「聞き手(H)がある命題(P: proposition)を信じる(BELIEVE)ことを、話し手(S)が意図 (INTEND)していると、聞き手(H)に知ってもらうこと(KNOW)」が目的なら、
THEN = DECL (P)
「宣言的知識(P)」を符号化して発信せよ
4.3.2 Macroplanning and Attentional Resources
■macroplanningは話し手の注意資源を必要とする記憶の探索(memory search)や推測(inference)などの様々な心理活動を伴うが、このmacroplanningがモノローグの中では定期的に現れるということを示した研究(Henderson et al., 1966)がある。
■この結果が全ての会話に一般化できるわけではないが、認知的負荷と流暢さの関連性について研究した例のほとんどが(e.g., Goldman-Eisler, 1968; Clark & Clark, 1977; Good & Butterworth, 1980)、認知負荷が低いほど(i.e., すでに発話内容が決められているor計画されている場合ほど)流暢さが高まるという結果を示している。
4.3.3 Selecting Information for Making Reference to Objects
■物体を示す表現は、Griceのquantity maximによれば情報量が多すぎても少なすぎてもいけないが、実際の会話では余剰的(redundant)になる傾向にある(Deutsch & Pechmann, 1982を参照)。Pechman(1984)の研究の例を示したFigure 4.4では、A~DのうちCとDで答えに含まれる情報が余剰的であった。
■理由は2つ。1つ目は情報が余剰的あるほうが聞き手は理解しやすいから。2つ目は旧情報との対比が行われているから(談話モデルにおけるfocal centerの移動)。その証拠にCとDではAとの対比で、余剰的な語であるcUpやwhIteに強勢が置かれている。このように文脈情報により同一指示物の呼び方が余剰的になることを内部照応的余剰性(endophoric redundancy)と言う(⇔外部照応的余剰性:exophoric redundancy)。
■ある物体について言及するとき、話し手がどのような情報を選ぶかは聞き手との相互作用のなかで決められる場合も多い(p. 133の会話を参照)。
4.3.4 Selecting Information for Construction of Requests
■要求をする(making a request)場合の情報選択は要求の正当性(legitimacy of a request)により決定される。要求の正当性とはつまり話し手の立場が聞き手より高いか低いか、どれくらいその要求を通す必要があるのか、聞き手がその要求を実行する力がどれくらいあるかなどを指す。
例) 一般兵が大佐にズボンのアイロンがけを要求するのは難しい(正当性の確保が困難)
例) Give me the pistol. (聞き手の意思は無関係=話し手が正当性を確信)
例) Could you give me the pistol. (拒否権が聞き手にある=話し手が正当性はないと判断)
4.3.5 Selecting Main-Structure and Side-Structure Information
■話し手は情報を次の2つに分類して発話する。
①main-structure/foreground information:最も重要で必要な情報
②side-structure/background information:追加コメント、文飾等 (p.136の例で斜字体の部分)
■この区別は文法構造にも影響を与えることがある。Story-retellingで犯人がA)ナイフor B)アイスピックで人を刺したという話を再話させる場合、ナイフ(ナイフで刺すのは一般的なので付加情報の扱い)とアイスピック(目立たせたい情報)の出現位置は異なる傾向にある(p.137の例文参照)。
4.4 Macroplanning 2: Ordering Information for Expression
■話し手は何をはじめに言い、後に言うべきか計画しなければならない(linearization problem)。この情報の順序を決める要素(determinants)はcontent-relatedとprocess-relatedの2種類がある。
4.4.1 Content-Related Determinants
■情報の順序は自然でなければならない(principle of natural order)。
・event structureの場合:古い → 新しい
(6)の例:She married and became pregnant. (自然な順序)
(9)の例:She became pregnant after she married. (afterが子供にとっては難しい)
・spatial structures(route direction)の場合:現在地 → 目的地
<感想等>
Macroplanningをしている段階(hesitant phase)と流暢に発話している段階(fluent phase)が規則的に現れる傾向にあることを示したHenderson graphはストーリー・リテリングをしている学習者の発話にもあてはまると思った。流暢さを高めるためには心理的負荷を低くする必要があると述べられているので、リテリングにおいてもどのように心理的負荷を低くするかかが学習者の流暢さを高めるカギとなるだろう。
2009/10/29
(pp. 139-144)
2009/11/12a
(pp. 144-160)
2009/11/12b
Chapter 5 (pp. 160-181)
5.0 Introduction
■Formulatorの2つの処理(①grammatical encoding, ②phonological encoding)の橋渡しとなるのはsurface structure (表層構造)である。つまりsurface structureは①のoutputであり、②へのinputでもある。
5.1 Syntactic Aspects
■同じ意味構造でも、各言語によりそのsurface structureは異なる(p. 164 Figure 5.1にEnglish とMalayalamの例)。
■正確なphonological encoding (segmental・suprasegmental)を行うために必要な情報
・lexical pointers:機能語or内容語の情報。
・diacritic features:
・phrasal information:句の情報。韻律構造の付与に貢献。下の2文は異なる韻律構造になる。
(1) (The widow) (discussed (the trouble)) / (with her son) /…休止が入る
(2) (The widow) (discussed (the trouble with her son)) (p. 166)
■surface structureの特徴
(i ) 句構造を成し、ツリーで表すことができる
(ii) ツリー内の各nodeはカテゴリー的である。NP・VP・PPなど。
(iii) 句の2つの機能(head-of-phrase functionとgrammatical function)を示す。
head-of-phrase function:どの語がその句の主要語になっているか(VPならV)
grammatical functions:どの句が主語や述語になっているか
5.2 Prosodic Aspects
■surface structureには韻律構造がないが、それを後に生みだすのに必要なmoodとfocusを含んでいなければならない。
・mood/modality:平叙文、疑問文、命令文のどれか ⇒ 上昇調or下降調が決まる
・focus:プロミネンスとなるのはどこか(ツリーでは「f」で表される)
■話し手はfocusをpitch accentにより表現する。以下はその際の規則。(詳細はpp. 174-179)
・Phrasal-Focus Rule
・Pitch-Accent Rule
・Focus-Interpretation Rule:focusは原則強調したい語に。但し主要語はその限りではない。
2009/11/26
Chapter 6 (pp. 181-222)
6.0 Introduction
■lexical hypothesis: レキシコンが概念化と文法・音韻符号化の仲介を成すと仮定する考え
6.1 The Structure and Organization of Entries in the Mental Lexicon (pp. 181-188)
■心内辞書で各語彙が有する情報は主に5種類 (p. 182 Figure 6.1参照)。
(1) 意味 (2) 統語属性(eatはVなど) (3) 形態素情報(tense formなど)
(4) 音韻情報 (5) 語用論的特徴 (フォーマルな文ではcopよりpoliceが好ましい)
■語彙は相互に結びついている(e.g., man-men, dog-animal, war-death)。
■話者は語彙を心内辞書から検索するだけでなく自身で生み出すこともあるが、その程度は言語により異なるようだ。英語は少ないほう。反対はトルコ語など。
■文法符号化の段階で検索されるのは(1)意味と(2)統語属性、いっぽう音韻符号化の段階では(3)形態素情報と(4)音韻情報のみが検索されると考えられる(p. 188 Figure 6.2参照)。
6.2 The Structure of Lemmas (pp. 188-198)
■レマ(特に動詞)は以下のような様々な情報を有する。(p.191 Figure 6.3のgiveの例を参照)
Conceptual specification:どのような意味構造を形成するか
Conceptual arguments:どのような項を必要とするのか
Syntactic category:Vなどの統語範疇は何か
Grammatical functions:必要とする文の要素(SUBJ, DO, IO)は何か
Relations to COMP:節を導くthatなどの補文標識?をとれるか
Lexical pointer:同じレマ(give, gives, gave…)が格納されている番地名
Diacritic parameters:時制・相・態・人称・数・ピッチアクセントなどの情報
■grammatical functions(e.g., SUBJ)とconceptual functions(e.g., agent)は必ずしも一致しない (例:passive formでSUBJポジションにOBJが来る場合など)。
■動詞以外の品詞も特有のレマ構造を持つ。前置詞ならばtowardのようにgoalを表す前置詞目的語をとる場合もあれば、wait forのようなidiomatic prepositionもある。
■完了形を表す助動詞haveも上のforと同じように具体的なconceptual specificationは行わないが、grammatical encoderに完了形を生成せよというtime indexを与える。
6.3 Theories of Lemma Access (pp. 198-214)
■Parallel Processing and Convergence:
言語産出において複数のレマが並行処理(parallel processing)されるという考え。その実験的証拠としてよく挙げ られるのがspeech errors(blends)である(例: stummyとtummyを言い間違える、The text fits the page.をThe page fits the text.と言ってしまうなど)。複数の候補は最終的に1つの レマに収束(converge)する。上位語の問題(例:dogが検索されるとその上位語であるanimal も候補になってしまう)。
■Logogen Theory (Morton, 1969, 1979):
ロゴジェンとは認知システムにあるレマ情報の収納媒体のことで、各ロゴジェンは意味・文 法などの情報が集まって閾値を超えると発火(fire)して使用可能になる。閾値を決めるのは主 に、過去にそのレマがどれくらい用いられたかという頻度情報である。
■Discrimination Nets (Goldman, 1975):
真(true, +)・偽(false, -)の2値データから成るツリーでレマを決定する(p. 205のFigure 6.5を参照)。異論(例:30,000以上もあるレマについていちいちこの手順で検索するのか、な ど)についてはpp. 206-207を参照。
■Decision Tables (Miller & Johnson-Laird, 1976):
Discrimination Netsと同じようにいくつかの条件(t1~t4)に対し真・偽の判断をしてレマの 特定をする。Discrimination Netsとの違いは、複数の条件(t1~t4)との照合が逐次的ではな く、並列的に行なわれるという点(p. 208のTable 6.1参照)。
■Activation Spreading (Anderson, 1983; Rumelhart et al., 1986; Dell, 1986, 1988):
モデルはp. 19のFigure 1.2を参照。「ある記憶情報が検索されると、その情報が活性化され ると同時に、活性化がニューラルネットワークを通じてその他の情報にも拡散するという考 え方 (中略…) insectからの意味の連想でbug (昆虫)が活性化され、次に、音韻からの連想で 別のbug (隠しマイク)まで活性化が拡散される」(『応用言語学辞典』p.547)。上のParallel Processingをよく説明できる考え方。
■Toward a Solution of the Hypernym Problem:
上位語の問題はレマが次の「3つの原則」に基づいて検索されると考えれば解決できる。
原則① 同じcore meaningを持つ語は2つとない (the uniqueness principle)
原則② 語彙は、表現したい概念によって、そのcore conditionが 満たされたときのみ 検索される (the core principle)
原則③ core conditionが満たされた全ての語彙のうち、最も具体的な(specificな)意味 を持つものが検索される(the principle of specificity)。
6.4 Failures of Lemma Access (pp. 214-222)
■レマアクセスの誤りの原因は次の2つ(p. 215のFigure 6.6参照)。
・conceptual intrusion:2つ以上の概念が同時に存在し、混乱が起きる場合
・associative intrusion:2つ以上のレマ間に関連があり、混乱が起きる場合
■誤りの種類
①Blends (混合)
意味的に関連のある2語を混ぜて用いてしまう(例:lecture + lesson ⇒ lection)。
②Substitutions (置換)
意味的に関連のある別の語に置き換えてしまう(例:Don’t burn your toes. [←fingers])。
③Exchange of Words (語の交換)
近接した意味的には関連のない2語を入れ替えてしまうこと(例:This spring has a seat in it. [spring ⇔ seat])。Figure 6.6ではbの例にあたり、レマの並列処理(parallel processing)の証拠と考えられる。
<コメント>
ここで扱っている単語検索モデル及び理論は、認知にも関わる重要な概念である。私の修士論文とも関わるので勉強になった。
2009/12/10
Chapter 6 pp. 222-234
6.5 The Time Course of Lexical Access
6.5.1 Stages of Access
■namingタスクにおいて話者は①visual processing、②conceptual categorization、③lexical accessという3つの処理を行っている。これらの処理に影響を与えるのは①visual effects、②conceptual effects、③word-frequency effectsなどである。
6.5.2 Visual Processing and Categorization
■namingで潜時が最も短くなるのは、basic levelの語を使って答えた時である。このcategorizationのプロセスを調べるのに、よくプライミングを用いた実験が行なわれる。
basic level of categories (apple, shoe, chair, etc)
superordinate level of categories (fruits, clothing, furniture, etc)
subordinate level of categories (cooking apple, pump, Ottoman, etc)
■プライミングの種類と効果(Figure 6.7およびFigure 6.8参照)
a. ( )位 知覚(視覚)的に関連がある(perceptually related):ラケット
Priming Route:Pi ⇒ C1 ⇒ l1
b. ( )位 機能的に関連がある(functionally related):アコーディオン
Priming Route:Pm ⇒ C2 ⇒ Fj ⇒ C1 ⇒ l1
c. ( )位 知覚・機能的に関連がある(perceptually + functionally related):バイオリン
Priming Route:Pi ⇒ C1 ⇒ l1
d. ( )位 関連がない(unrelated):イス
■プライミングに単語を用いた(visual priming routeがなくなった)場合はFigure 6.9のようになる。つまり、ターゲットの絵と完全に一致した語(●)でなければ、概念的に関連があろうと(○)、なかろうと(×)、正のプライミング効果は生まれない。これはFigure 6.7の例でアコーディオンがプライミング効果を生まなかったのと一致する(アコーディオン≠ギター)。
※SOA(Stimulus-Onset Asynchrony)とはプライミングとターゲット提示の時間の差のこと。 -はプライミングがターゲット提示より前、+ならばプライミングがターゲット提示の後。
■Congruency Effect:
Figure 6.10 aの絵:小さい三角形が2つ ⇒ 小さい三角形を答えるときのほうが早い
bの絵:大きい三角形が2つ ⇒ 大きい三角形を答えるときのほうが早い
cの絵:短めの棒が2本 ⇒ 短い棒を答えるときのほうが早い
dの絵:長めの棒が2本 ⇒ 長い棒を答えるときのほうが早い
6.5.3 Lexical Access
■Semantic-markedness Effect:
marked / unmarked access time
big / tall unmarked 早い
small / short marked 遅い
※unmarked:How big is your dog?は犬が大きいことを必ずしも前提としない。How small is your dog?はその逆に、犬が小さいことを前提とした言い方。
■Word-frequency Effect:頻度の高い語ほど早くアクセスされる。
6.5.4 Accessing Lemmas and Word Forms: Two Stages?
■lexical accessは2段階なのか?つまり、lemmaへのアクセスが行なわれるのと(grammatical encodingにて)、そのform(音韻形態)の検索が行なわれるのは(phonological encodingにて)、同時なのか、それとも別の段階なのか?
■tip-of-the-tongue現象は、lemmaはアクセスされているがformは検索されていない状態を示すので、2段階であることの1つの証拠となる。しかしそれ以外の十分な証拠は示されていない。
6.5.5 Are Categorization and Lexical Access Nonoverlapping Stages?
■conceptual categorizationとlexical access(formの検索まで含む)は別の段階なのか?close + near = clearと言い誤ってしまうblend現象は2つの段階に重なりがある可能性を示している(概念的に類似しているcloseとnearを音韻的に混ぜて発話している)。
<コメント>
How big is your dog?とHow small is your dog?の前提の違いについて今まで考えたこともなかったが、なるほどと思った。本章の主旨とは関係ないところで小さな感動があった。
2009/12/17
Chapter 6
2010/1/21
Chapter 9(pp. 318-343)
・本章では、単語の音韻符号化を扱う。音声は元々が完全な状態で貯蔵されているのではなく、いくつかの段階を経て音節化されるということを見ていく。
9.1 The Tip-of-the Tongue Phenomenon (p.320)
・レマから音の形式への移行が阻害された状態:tip-of-the-tongue(TOT) phenomenon
Brown & McNeill (1966)の実験:辞書の定義を使った実験で、TOTの状態では語彙形式の情報が存在していることが分かった。
・このBrown-Mcneillの実験と後続の反復実験により、韻律や語頭・語末の音など、語彙形式の部分的な活性化が起こっていることがわかった。
・Jones & Langford (1987)は、辞書の定義を与えられた直後に、音韻的に似ている”blocking word”(e.g. sextantに対するsecant)が与えられることで、TOT状態に陥る可能性が増大するとした。また反対に、意味的な阻害は関係がなかったことから、TOT状態ではレマの検索は既に終わっており、失敗しているのは形式的情報へのアクセスであるということがわかる。
・これら実験から、語彙形式の表象が「全か無か」ではなく部分的であり得ると言える。⇒Jones & Langfordは、このような表象をword sketchと呼んでいる。→次節
9.2 Frames, Slots, Fillers, and Levels of Processing (p.321)
・スピーチ・エラーからword sketchesやフレーム、そしてそれらを埋める要素の存在が明らかになる。
(例)音素の間違い [I sould be sheeing him soon ]:候補となった/∫/ と/s/ がそれぞれ入るフレームが入れ替わった形。
・以下は、語生成における主な3つの段階のそれぞれにおける例である。ここで、音声プランニングに寄与するシステムのおおまかな見取り図が示される。
9.2.1 Morphological/Metrical Spellout
・レマや弁別的パラメータ・特性から、形態素・韻律的な語の構成要素を作り出す段階。
(例)ある動詞の正しい屈折系を選ぶ場合:弁別的パラメータはどのようにして、一つの語彙記載項(lexical entry)の中の複数の語彙項目(lexical items)から正しいものを選択するのか?
・以下の図において、一つのフレームは表層構造のレマ、その他のフレームは弁別的パラメータに使用されている。
lemma
segment number
any person
any tense
past
⇒ segmented
→これらのフレームがすべて適切に埋められると、形態素・韻律的要素が現れる。
形態:語幹(segment), 接尾辞(ed) / 韻律:音節の山がsegmentに2つ、edに1つ
これらの手順により、形態・韻律的要素が明らかとなる。つまり、非常に早い段階で語の韻律的情報が存在しているということである。
・この段階ですべての韻律情報が明らかになると仮定することも可能である。
・この段階では貯蔵された韻律情報のみが存在しており、ピッチ・アクセントや文脈的に決定される韻律はProsody Generatorによる(10章参照)。
・また、分節の情報はこの段階では存在しない。(例にあったsegment、edなどは便宜的に使用したもの)
・上記のフレーム内に間違った情報で埋められると、不適切な書き出しが行われる。
(例)that I’d hear one if I knew it [ intended: that I’d know one if I heard it ]
⇒1つ目の動詞に間違ったレマ情報が使用されているが、時制は正しいことがわかる。
9.2.2 Segmental Spellout
・分節情報の書き出し(segmental spellout)は形態・韻律情報をインプットとして、語の分節構造を作り上げる。これにより、分節の音節的構成としての分類も行われることになる。
・分節情報の書き出しのためのフレームは語幹・接辞などの形態素からなる。(p.324参照)
・この段階は以前までの段階の上に成っている。
(例)segmented … 頭子音(onset), 韻( rime), 核(nucleus), 尾子音( coda)
この場合は尾子音以外がすべて短音素なので、子音連結である尾子音だけが書き出しを必要とする ⇒ /nts/ /n/, /t/, /s/ <cluster spellout procedure>
・スピーチ・エラーにおいては、頭子音同士, 韻同士,尾子音同士で誤りが起きることがほとんどである。
・インプットである形態素の境界(e.g. segment / ed)は、分節の音節分類の中には保管されていない。(接尾辞-edは音節/t∂d/の一部分として生成される)
また、韻律情報はこの段階では核の音素となっている。
・この段階においても、不適切な項目がフレーム内に入れられるとエラーが生じる。
(例)take the freezes out of the steaker [take the steaks out of the freezer ]
⇒steaksの語幹とfreezerの接尾辞によって分節の書き出しがなされたsteaker
※このように文脈に依存して現れる異なる形態をallomorph(異形態)と呼ぶ。
・強勢エラー(stress error):abstract(名詞)のような間違い…このようなエラーは、同じ形態素を持った関連語のものである(Cutler, 1980a)。この関連語がどのように生成過程で活性化されるかが重要(9.5.2)
・フレームが適切な項目で埋められても、話者は貯蔵されていない新語を作り出してしまうことがある(例:steaker)。これは類推によるものだと考えられるが、心理学・言語学ではあまりよく理解されていない。
9.2.3 Phonetic Spellout
・分節情報を使って音韻符号化が行われるが、このような音節におけるphonetic plansでの音は常に異音(allophones;文脈に依存した音節や音素;8.1.5, p.296)である。
・音声的書き出し(phonetic spellout)とは、話者の持っているsyllable programsを検索することが主である。ただし、貯蔵されたprogramsは完全には固定されておらず、多少の範囲で可変的である。また、ある言語のうちすべての音節が話者の中に存在するとは考えにくい、ということが言える。
・音節の計画段階におけるフレームは3つある:onset, nucleus, coda…これらが、分節的書き出しから出じる適切な音節によって埋められる必要がある。
・(例)segmentedの最初の音:seg
onset
/s/ nucl
/ε/ coda
/g/
音声的書き出しの3つのフレームは韻律的書き出しの段階で明らかとなるが、核が強勢音となっているものとなっていないものの2種類に分かれる。今回は強勢のない場合。
・以上のようにフレームが埋められると音節のphonetic planの検索が行われる。
音声的書き出し ⇒ [sεg]
・エラーの例:heft lemisphere [left hemisphere]
⇒/h/のほうが活性化されていたと考えられる。/h/ 、/l/の両方が正しいフレーム(onset)に属していた。
・英語の音節の種類は6,600程度と言われるがこれは比較的少ない数であり、話者のレキシコン内に収まる。未知の音節については類推によって発音可能であることが多いが、このような新しい音節の生成については明らかとなっていない。
・音節や音素の発音の多くは、周囲の音節に左右されるが、音節を超えた文脈に発音が影響されることもある。また、音節の強勢やピッチも文脈によって決定されるところが大きい10章(connected speech)
9.2.4 The Unit-Similarity Constraint
・以上3つの例すべてにおいて、フレームの中にtarget(適切な項目)ではないintrusion(適切ではない項目)が入ることがあるが、では、どのようなintrusionが考えられるだろうか。
・書き出しの3段階においては、いずれもそれぞれのフレームに決まった分類のものしか入れることはできなかった(onsetはonset、など)。
結論として、Targetやintrusionは、Unit-Similarity Constraintの原則(intruder項目はtarget項目と同じ分類である)に従う(Shattuck-Hufnagel, 1979)と言える。
・レマ、語幹、接尾辞など、交換可能な単位を決めることで、フレームに何が入るかを明らかにすることができる次項から、さらに他のスピーチ・エラーに見られるtarget-intrusionのケースを見ていく。
9.3 Substitutable Sublexical Units (p.330)
・Fromkin(1971)はほとんどすべての言語単位や言語特徴が置換可能であるとしたが、のちの研究からは、特定の種類のスピーチ・エラーには極めて稀であるものがあることがわかった。以下はその例。
9.3.1 Morphemes
・語、語幹は類似したカテゴリーに入っており互いに交換可能だが、それらの形態素は、接尾辞と交換されることはほとんどない。接尾辞同士の交換は可能である。
・形態素のエラーは、形態的書き出しか分節的書き出しのいずれかの段階で発生する。
9.3.2 Syllables
・単音節の形態素における交換は、すべて音節の交換といえる。では、複数の音節を持つ形態素の単音節は、移動・交換可能か? cassy put [pussy cat]のような例は極めて例外的 (Shattuck-Hufnagel, 1979)。
・音節は、比較的不変である構音ユニットの中でも最も小さなものである。しかし、フレームの中に音節そのものが入るということはない。
9.3.3 Syllable Constituents
・頭子音、脚韻はそれぞれ別にスピーチ・エラーに含まれ得る。混成語においては、音節の母音の前に語の切れ目が来ることが多い(MacKay, 1972)
(例)gr-astly [grizzly/ghastly] > mai-stly [mainly / mostly]
また、音節の頭子音そのものが移動することはある。(例)face spood [space food]
・脚韻もまた移動可能である。脚韻を構成する核と尾子音も、それぞれ移動可能な単位としてあるものの、互いに離れない傾向にある。(核の移動の例)cleap pick [clip peak]
・Shattuck-Hufnagel(1986)の研究:300個のスピーチ・エラーを分析エラーの79%が強勢音節の母音の間に起こっていた。強勢のある母音には、ないものより遥かにエラーの傾向がある。
・Treiman(1983,1984)の研究:音節構成の可動性、核と尾子音の統合について、
/r/や/l/…liquid segment:高音域のピークを持つ音節核・尾子音のいずれに属するのか?⇒核
・null-element(orthにおける頭子音や、spaにおける尾子音など)は、存在するのか?常に存在するわけではないが、スピーチ・エラーを見る場合には考慮する必要がある。
・結論としては、音節構成もすべてUnit-Similarity Constraintに従っていると言える。
9.3.4 Segments
・分節に関するスピーチ・エラーのほとんどは、音節の頭子音・核・尾子音だが、それらの中の個別の音素(例:playingの/pl/ではなく/p/のみ)だけが移動する場合がある。
・⇒特に音韻的書き出しの段階(頭子音・核・尾子音それぞれにフレームが割り当てられている)で、子音群を構成する要素が存在している必要がある。
・話者は頭子音・核・尾子音それぞれについて、あらかじめ子音配列のセットを持っている。
・そのセットに対応しないような移動が起こると、flay the pictor [play the victor]のような例が生じる。このように特定されていない音素はarchiphonemes(原音素)と呼ばれることがある。(例)/P/, /F/, /T/, /K/.
・これら原音素は、子音群を書き出す段階で生じる。
・結論として、頭子音における個別の音素はすべて、スピーチ・エラーで間違った場所に置かれる可能性があると言える。
・頭子音のうち、1番目にあるものより2番目にあるものほうが脆弱で、交換されてしまいやすい(例:pace [place] , prace [place])。また、不正に追加されやすい(例:bruy [buy])
・尾子音に関しても似たような仕組みが考えられる。
・複雑な核に関しても、それだけのための特殊な仕組みがあると仮定できるだけの研究はない。
・全ての音声的分節(phonetic segment)に誤配置の傾向があるのか?大部分がその通りだと言えるが、研究によっては音素の脆弱さに違いがみられる。その理由は明らかにはなっていない。その強弱は、音素の位置にも左右される可能性はある。
9.3.5 Distinctive Features
・有声化、鼻音化などの弁別素性が単独で移動することはあるか?可能とされている。(例:glear plue sky [clear blue sky])
・したがって、子音の移動に見えるものが実は弁別素性の移動であることも考えられるものの、実際にはほとんどが子音の移動である。
・ここまでで、音節そのものが交換されることはほとんどなく、異音に関しては全くないということがわかった。また、弁別素性同士の交換も例外的である。したがって交換され得るのは、前述の3段階でフレームに入るもの(形態素、音節の構成要素、音素の分節)と言える。但し、その他にもエラーを起こす傾向のある語の部分が存在するとされる次項
9.3.6 Word Onsets and Word Ends
・スピーチ・エラーが頻繁に起こりやすい頭子音:音節の頭子音か、語の頭子音か?語の頭子音は、他の音節の頭子音と比べると遥かに脆弱である。
・しかしそれには、語の頭子音が強勢音節である傾向にあるためという可能性もある。
・強勢音節はエラーを起こす傾向が強い。また、語の頭子音が脆弱なのは結合した句の場合であるとされる(Shattuck-Hufnagel, 1987)
・語末に関しては、1音節より大きい場合にスピーチ・エラーが起こるが、ごくまれである。
・これまでのまとめ:
(1)これまでの3段階において、フレームが割り当てられていた単位が影響を受けやすい。
(2)子音群は、構成素の分節へと書き出しが行われるが、複雑な音節核については行われない。
(3)語の頭子音は、結合した句の場合にエラーを起こしやすい。
<コメント>
ここまでの説明は音韻符号化段階の話であり、実際の発音段階のことではない点に注意したい。
2010/01/21
Chapter 9 (pp. 343-363)
9.4 The Slots-and-Fillers Theory and the Causation of Errors
9.5 Activation-Spreading Theory
■レマの発話上の誤りは2つの考え方によって説明できる。
(1) Slots-and-Fillers Theoryによる説明 (p.345 Figure 9.1参照)
Phonetic spellout levelにおいて、onset/nucleus/codaのスロットに誤った音節(filler)をあて はめてしまう。通常check-off段階で誤りは訂正されるが機能しない場合がある。それにより 起こる誤りは以下の5種類に分けられる。
a. Exchanges :×a but-gusting meal [○ a gut-busting meal ] 前⇔後
b. Substitutions :×the pirst part [○ the first part ] 前←後
:×a phonological fool [○ a phonological rule ] 前→後
c. Omissions :×Doctor –inclair [○ Doctor Sinclair ] -emphasizedのnull filler
d. Additions :×has slides sloping in [○ has sides sloping in ] b.に似てる
e. Shifts :×Frish Gotto [○ Fish Grotto ] /r/が前へシフト
※上記のような誤りは、2音間のphonemic similarityがあればあるほど起こりやすくなる (例:paid mossible > two-sen pet)
(2) Activation Spreading Theoryによる説明 (p.352 Figure 9.2参照)
レマのネットワークは次の3つのレベルで構成されている。(1)統語(syntactic)、(2)形態素 (morphological)、(3)音韻(phonological)。各レベルにおいて活性化されるノードは1つ。
a. Malapropisms:形式上関連のある語との入れ替え (例:reset→resell)
b. Lexical bias:spoonerism(頭音転換)が起こりやすいのは転換後の2語が存在する語の場合
(例:darn bore→barn door > dart board→bart doard*)
c. The repeated-phoneme effect:同じ音素が続くために起こる (例:heft lemisphere /ɛ/)
d. Checkoff failure:checkoff時に再活性(reactivate)されることでその後のレマに影響
(例:boot coat→boot boot/boot boat)
e. Phonemic similarity:音韻的に関連のある(有声か無声かなど)音素は全て同時に活性化
(例:無声音の/s/は/t/を活性、前方の/i/は/e/を活性するなど)
9.6 Serial Order in Phonological Encoding
■onset/nucleus/codaのスロットに音素を当てはめて音韻符号化するプロセスは原則逐次的であるのでpit-fallをfit-pall/pif-tallと言い間違えるようなことはないと言えるのだが、前者のfit-pallに関してはUnit-Similarity Constraintの制限内なので(入れ替わった音節がともにonset)十分起こりうることである。
<コメント>
Sくんの「帰無仮説を棄却する」と言おうとして「帰無キャ説を…」と言ってしまった話には爆笑した。これは上のSlots-and-Fillers
TheoryではSubsitutionにあたるだろうか。
2010/02/04
Chapter 10
■多数の連続発音は、単なる記憶から検索された語形の連続というだけでなく、さらに多くのことが関与している。
① 形態学的また分節的適応(morphological and segmental accomodations)
◎助動詞縮約(auxiliary reduction)
・I have bought it よりもI’ve bought it、he will go よりもhe’ll goという表現を好む。
◎隣接する語と接語化(cliticize)する toやofなどの語は縮約され接語化される。
・I wanna goまたはa bottle’o milkのような表現
◎語と語の境界において、文節は消失、変更、付加などが行われる。
・just fineはjus fineとなり、got youはgot [tʃ]ouとなる
再音節化(resyllabification)と共起
★音韻符号化の主な機能は、流暢で連結した調音をすることである。
長々と書きだされた引用(citation)形式は流暢で発音可能な音節の連続へと翻訳される
② 発話者の韻律的なプランニング(prosodic planning)
・発話の韻律的構造は大小のrhythmic phrasesに分類される(phrasal togetherness)。
・この分類は、発話内の連続する音節における大きさ(loudness)、時間(duration)、高低(pitch)の操作、またポーズの挿入によって実現される。
・またメロディーライン(melodic line)により態度や感情を表現する。
10.1 A Sketch of the Planning Architecture
10.1.1 Processing Components
・音韻符号化の主なインプットは、展開された表層構造である。
■図1.1の“phonological encoding”と名付けられたボックスは連続発音のためにphonetic planを生成する場所であると考えられる。
① 発音の区切れのパラメーター(diacritical parameters)に付随する終端接点(terminal node)はword-form addressesへのポインターとなる。これらのword-formsがどのようにphonetic plansへ翻訳されていくかをこれまでの章で扱ってきた(図1.1の左端のボックスを参照)。
② 表層の句構造(surface phrase structure)=Prosody Generatorへのインプット、は連続発音のためのphonetic planにおいて重要な役割を担う。
◎Prosody Generatorへの付加的なインプット tune, tone, key, registerを選択させる
・“intonational meaning”=rhetorical intentions, emotions, attitudes
・ポーズや発話の速さを変えるなどによっても、調整されるが、このような音韻符号化における幾つかの側面はexecutive controlのもとに行われる。
■韻律生成(prosody generator)が文節的な書き出しに作用する、と仮定できる。
・フランス語のliaisonの例(通常最後の子音が発音されないフランス語の単語はたくさんあるが、次に来る語は母音から始まる場合は、消失しないことがある。)
・英語の例(単語の最後が発音されない /n/ で終わる場合、その次に来る単語が母音から始まる場合は、/n/ も発音される。)
・語の最後の音節における文節的な書き出しは、次に来る語のonsetに左右される。
・liaisonには文脈依存性もあり、句境界(phrase boundary)が影響している。
10.1.2 Casual Speech
■早さではなく、casualな表現の使用に注目する。
・同義のcasualな表現を用いる場合(policeman の代わりにcop)や、特定の異形態を用いる場合(I have の代わりにI’ve)。
・casual speechの種類によっては代替えする語を用いるのではない場合(発音の便宜上、leave me をlea’meのように言う)もある。
★casual-speech phenomenonはword-form planningの時点で生じる。
10.1.3 Fast Speech
■早い発話にはreduction(弱化)とassimilation(同化)が起こる。
・音韻符号化のレベルでプランされる。
■弱化はある程度の規則に乗っ取って行われるが、その後に隣接する語により使用されるかどうかは異なる(Think o’money とは言えてもWhat are you thinking o’? Money? とは言わない)。
・文節を削減することによりスピードが上がる。 語の始めにある強勢の置かれない母音を(p’tatoやt’matoのように)省略する(これは、隣接する語や句構造の影響を受けない)。
・英語における音節のonsetとして不適格なものは使用できない(/pt/ や/tm/)。
■同化は速い速度の発話において起こりやすい。同化はsegmental spellout levelで起こりやすい。
・同化には依存構造が見られる。
・Who do you want to (wanna) succeedとは言えてもWho do you want to succeed you? では言えない。
・同化は同時調音(coarticulation)とは区別されなくてはならない(同時調音の場合は、生理学的にまた調音の仕組みから起こるもの)。◎弱化と同化は接語化(cliticization)として結合されることもある。segmental spelloutとは音韻語(phonological word )のことで、聞き取った語をそのまま書き出す(I’veはI have ではなく/aɪv/と書き出される)。
10.1.4 Shifts
・発話の中で、語が誤った位置に移動(shift)してしまうことが起こる。
(1)Did you stay up late vEry last night?
音韻符号化におけるエラー。異なる統語範疇の語同士が置き換えられてしまう。
(2)We tried it mAking…mAking it with gravy.
open-class wordが移動してしまう。
(3)I had forgot abouten that
接辞が移動してしまう。
10.2 The Generation of Rhythm
■連続発音のリズムは強勢音節(stressed syllables)とポーズの挿入(insertion of pauses)の中で起こる。
・音節に強勢を置く方法は幾つかあるが、他の隣接する節よりも強く発音する方法などがある。
◎どのような種類の拍節構造(metrical structure)が発話者によって構築されるか。
① 内在の強勢パターン(stress patterns)。基本的な強勢パターンはmetrical spelloutを行う間に記憶から検索される。prosody generatorは接語化によって作り出された音韻語も扱わなければならない。
② phonological phrasesの構築。
③ intonational phrasesの構築。
■リズムにおける処理理論の主な原則は、産出されるものは徐々に起こるということ=韻律パターンは表層的な句構造として作り出され、それからmorphological/metrical spelloutが適用される。 prosody generatorは大量のインプットをバッファーするべきではなく、徐々に処理する。
・(音韻)語、音韻句、音調句の韻律的プランニングについて考察し、その後、タイミング(i.e., 語、句、文やさらに大きい単位、における文節と音節の長さ)、同時発生(isocrony)(i.e., 推定される通常の強勢音節の時間的間隔)について、強勢拍リズムの言語(“stress-timed” languages)における連続発音の中で考察する。
10.2.1 Phonological Words
■ほとんどの語に関する韻律パターンはメンタルレキシコンの中に保存されており、そこから検索される。単語ひとつでも、高さに変化(e.g., Ca li for nia)が加わったり、個々の単語の拍(e.g., six teen dol lars)が変化したり、ということが起こる。
◎接語化の特徴
・前接語(enclitics)(その語自体には強勢がなく、前の語に続けて発音される語)
(i)接語化されるのは、小さな語で音節のない語(nonsyllabic)であることが必要である。しかし、中には接語化してしまうと不適格な形になるものもある。異形態の使用に関する選択は、後続する内容によると考えられる。
(ii)小さな語が音節主音(syllabic)でひとつの音韻語として存在する場合、prosody generatorはそれでも前述の大きな語と接語化させようとする。しかしこれにも接語化できない場合がある。
・特定の訛りのある英語に関して、ひとつの単語の中で、例えばwinterの /t/ の発音が落ちることがある。また、不定冠詞が後続する名詞と接語化する場合もある(e.g., an apple anapple) procliticization
・この場合も、不適格な形である場合は、接語化は起こらない。
10.2.2 Phonological Phrases, the Grid, and Incremental Production
■発話者は左から右へ音韻語を構築する。 これをphonological phrasesとintonational phrasesのグループにすることができていると考えられる。
Main Procedure
・lexical headやlexical phrase(i.e., NP, VPまたはAPの主要部)などが現れるまで、音韻語を連結させる。音韻語の後には連結を終了させる(Coda Procedureが起こらない限り)。
Coda Procedure
・音韻語を形成した後に続くのが主要部を含まないものである場合(VP, PP, AP, NPの境界にならないとき)、後続の音韻語を前に出てきている音韻句を加える(主要部が現れるまで)。
・隣接する語の強勢がくずれるのは、拍が無い、または少数の拍によって分けられるときのみである。連結の大きさが、pitch movement, pauses, glottal stops, syllable lengtheningなどの境界マーカー(boundary markers)の使用を決定する。
Q1) 語と語の間の正しいsilent beatの数をProsody Generatorに入力するためには、どの程度の先読みが必要だろうか? silent beatの分布は徐々に計算される。
Q2) 新しい語のstress levelをどの程度予測しておくべきだろうか? text-to-grid-alignmentと呼ばれる前処理の段階で、stress-assignment rulesが関与している(①Pitch-Accent Prominence Ruleと②Nuclear-Stress ruleを除いて)。①はpitch-accentが置かれた音節がもっとも際立っているべきである、というルール。②は大範疇や文の中の最後にある、非前方照応的な語(nonanaphoric word)に第一強勢を置く、というルール。
・前処理は先読みが要求されておらず、記憶に頼った処理といえる。
10.2.3 Intonational Phrases
■“Break options”の使用。 発話者がbreak optionを使うかどうかは、何によって決定されるのか?
① 発話者によるexecutive control
聞き手が理解しやすいようにゆっくり話す。発話者の意図的なコントロールによる。
② 発話速度による一般的関係
③ 文の切れ目に到達したときに、大抵の発話者はbreakさせる。 統語論的
④ 非常に目立ったpitch accentの後は短めにbreakさせる。
⑤ operational 表層構造の断片を利用。処理時間を長めに取ることなどができる。
10.2.4 Metrical Structure and Phonic Durations
■拍節構造(metrical structure)は文節、音節、語、句、ポーズなどの様々な持続のさせ方に現れる。これらの関係性はシンプルなものではなく、様々に組み合わさっている。
・metrical stressとsilenceは音節の長さに現れ、これをThe Prosody Generatorが統制する。
10.2.5 Isochrony
・英語…a stress-timed language (強勢拍リズムの言語)
発話者は、通常のまた大まかな等時性の間隔において強勢音節(stressed-syllables)を出す。
・フランス語やスペイン語など…syllable-timed(音節拍リズムの言語)
それぞれの音節に均等に感覚が振り分けられる。
・強勢の置かれた目立つ音節から始まり、次の強勢音節が始まる前で終わる箇所をfootと呼ぶ。
・発話者は①音節の範囲を伸ばしたり縮めたり、②付加したり、削除したり、強勢位置を移動させたりする。
2010/02/18a
Chapter 10
10.3 The Generation of Intonation
■Prosody Generatorのもう一つの役割。 連続する音調句(intonational phrases)のためのピッチ輪郭(pitch contours)を算出すること。
・新しいトピックについて述べるときに音の高さを変えたり、会話を継続するか否かを表現したり強調したい情報のときに、発話者の感情を表す。
10.3.1 Declination
■音調句の中で、音が下がる現象をdecinationとCohen & ‘t Hart (1965) により名付けられた(Figure 10.3参照)。※declination line
◎declinationの後には、発話者は息を吸い込み、また高い位置から発話が始まる。生理的な現象ともいえる。
◎declinationのプランニングは可能なこともある。
10.3.2 Setting Key and Register
・news valueのある位置で音が高くなる。
10.3.3 Planning the Nuclear Tone
■核調子(nuclear tone)のプランニング
①nuclear pitch movement 核に向かって、または核から高くなったり低くなったりする。
③ boundary tone 音調句の最後の音節で高さの変動(pitch movement)が起こる。
・nuclear pitch movementを行うために、prosodic generatorがnuclear syllableを選択しなくてはならない。 発話者の中で常に決断が下されている。
10.3.4 Planning the Prenuclear Tune
■音調句の中の強勢の置かれた音節がnucleusとなる。
default-toneはmid-level pitchになっている。
・inclination nucleusに向かって徐々にpitchが上がっていく。
・(a) individual realization (b) “hat pattern”
10.4 The Generation of Word Forms in Connected Speech
■segmental spelloutとphonetic spellputはprodocic generationによって決められる。
10.4.1 Segmental Spellout in Context
■同化、接語化、弱化、の中で起こる、context-dependent segmental spelloutに関しては2段階ある。①syllabicまたsegmentalな構成が書き出される。②Prosody Generatorの利用。(obligatoryな接語化とoptionalな接語化)
10.4.2 Phonetic Spellout in Contex
■①onset②nucleus③codaの3つの各スロットが、韻律情報によって“enriched”される。音節のduration, loudness, pitch movementを含む。Articulatorは全てのphonetic word planを受け取ってからでないと語の最初の音節を発音できない。Articulator phonetic spellout
<コメント>
発話内容を分析すると、感情の変化や発話の状況などはもちろんのこと、特定の語がshiftしてエラーを引き起こす、といった大変興味深い内容であった。日本語でも語の位置が正しくない位置にshiftしてしまうことはあり得るので、どのような語がどのような頻度でエラーを引き起こすかを調べると面白いのでは、と思った。
2010/02/18b
Chapter 12 (pp. 458-478)
Introduction
★12.1 自己モニター(self-monitoring)のプロセスについて。またそれに関わる2つの理論(the editor theoriesとthe connectionist models)について。
12.2 自己修正(self-repair)について(editing expressionsとself-interruption)。
12.1 Self-Monitoring
12.1.1 What Do Speakers Monitor for?
■話者は次のような点についてモニターを行う。
「これは今私が表現したいメッセージ?」
「言い方は大丈夫?」
「私の言っていることは社会規準に適っている?」(=registerの選択; policeman/cop)
「語彙の誤りは犯していないか?」(write it back → write it down)
「統語と形態素は大丈夫?」
「音形式の誤りは犯していないか?」
「調音のスピード・大きさ・正確さ・流暢さは適切か?」
12.1.2 Selective Attention in Self-Monitoring
■話者は上記のすべての点に同時に注意を払うわけではない。通例話者は、(i)多くの発話上の誤りには気付かず、(ii)モニターは文脈に影響を受けやすく(=聞き手の理解を妨げるような誤りを修復しやすい)、(iii)発話の中で話者の注意の程度は変動する(=発話or統語構造の終わりに近ければ近いほど修正を行いやすい、Figure 12.2参照)。
※斜字体の語が修正を必要とする箇所
(14) And then you come to blue ø/ - I mean green. (0音節)
(15) There is a yellow node / to the right of the red one. (1音節)
(16) To the right is a black cross-ing / from which you can go up or down. (2音節)
(17) You enter at a green nod-al point. / (3音節)
■発話前に修正が行われる場合を調音前修正(prearticulatory editing)と呼ぶ。
12.1.3 Editor Theories of Monitoring
■editor(=monitor)と呼ばれる機構は産出システムの外部(external)にあり、internal speechとovert speechの両方に対し機能する(Figure 12.3参照)。前者は調音前修正(prearticulatory editing)、後者は調音後修正(postarticulatory editing)と呼ばれる。
■全ての発話がこの認知ループを経由するわけではなく、概念化段階で修正される場合もある。
12.1.4 Connectionist Theories of Monitoring
■コネクショニストのモデルだと独立したモニター機構は存在せず、言語産出時、活性拡散(p.352 Figure 9.2参照)に本来備わっているフィードバック機能によりエラー検知が行われるとする。しかしこの考え方では、既に産出された言語に対してモニターを行うこと(=調音後修正)については説明されていない。
■コネクショニストモデルを使って調音後修正の現象を説明しようとしたのが、MacKay(1987)のノード構造理論(node structure theory; p. 475 Figure 12.4参照)である。この理論では、命題ノード・概念ノード・語彙ノード・音節ノードなどの心的ノード(mental nodes)が、(A)知覚分析(sensory analysis)(=聴取)と、(B)筋肉運動(muscle movement)(=調音)の両方で共有され、「(A)→心的ノード①②③」のボトムアップ処理と、「心的ノード①②③→(B)」のトップダウン処理のなかで修正が行われるとする。
<コメント>
一見当たり前のようだが、overt speechだけでなく、internal speechに対してもモニターを行なうというのは説得力があったと思う。私的な感想だが、思わず言ってしまって後悔することもあるが、言い留まっても結局後悔するのは自分の悲しい性格だと思った。
2010/03/18
Chapter 12 (pp. 478-499)
12.2 Interrupting and the Use of Editing Expressions
12.2.1 Interrupting the Utterance
■Main Interruption Rule:「問題(trouble)を検出するとすぐ話者は発話の流れを止める」
■covert repairは発話から何を修正したのか断定できないもの。
(19) Here is a –er a vertical line (horizontalと言おうとしたかどうか定かでない)
■その逆はovert repair。いつ修正が行なわれたかで以下の種類がある(Figure 12.5参照)。
・誤った語の途中で中断→修正
(20) We can begin straight on to the ye-, to the orange node
・誤った語の直後で中断→修正
(21) Straight on to green – to red
・1~3語遅れてから中断→修正
(22) And from green left to pink –er from blue left to pink
(23) And over the gray ball a pur-, or er right of the gray ball a purple ball
□Main Interruption Ruleの例外
(25) To the left of it a blanc, or a white crossing point.
※ここで行われているのはerror repairというよりappropriateness repairである。
12.2.2 The Use of Editing Expressions
■自己中断(self-interruption)は通常、短いポーズやediting expressionと呼ばれるもの(e.g., -er, that is, I mean, etc)を伴うが、これが聞き手に問題があること、またそれがどんな問題なのかを知らせる役割を果たす。
(30) He hit Mary – that is, Bill did. (指示対象の明確化)
(31) I am trying to lease, or rather, sublease my apartment. (“nuance editing”)
(32) I really like to – I mean – hate to get up in the morning. (完全な誤りの訂正)
12.3 Making the Repair
12.3.1 The Syntactic Structure of Repairs
■constituent ruleによれば、話し手は構成要素の境界において修正を行なうとされるが、(37)のように89%の語は何らかの句の最初もしくは最後にあり、いつ修正が行なわれてもよいということになってしまう。
(37) to the red node → PP[ to NP[ the NP[ red NP[ node]]]
■Well-Formedness Ruleによれば、修正がwell-formedである場合というのは、OC or Rが統語的に正しい等位関係を成している(coordinate)場合である。O・C・RはそれぞれO(=original utterance; もとの発話)、C(=completion; Oの最後の構成要素を完成させる語句)、R(=repair; 修正された語句)のことを表している。
(38) ×Is the doctor [seeing … ]– er the doctor interviewing patients?
(40) ×Is the doctor [seeing (the surgeon)] or the doctor interviewing patients?
(39) ○Is [the nurse] –er the doctor interviewing the patients?
(41) ○Is [the nurse] or the doctor interviewing the patients?
12.3.2 Ways of Restarting
■どのような修正を行なわなければいけないかによって、R(=repair)とO(=original utterance)の表現は重複することもあればしないこともある。以下の3パターンがある。
①即時修正(instant repairing):修正の必要な1語をただ入れ替えて修正
(48) Again left to the same blanc crossing point – white crossing point
②先行追跡(anticipatory retracing):修正の必要な語より先にある数語も用いて修正
(49) And left to the purple crossing point – to the red crossing point
③新規開始(fresh start):Oにはない、まったく異なる統語構造を用いて修正
(50) From yellow down to brown – no – that’s red
■error repairで多いのは①と②、appropriateness repairで多いのは③である。
12.3.3 Restarting and the Listener’s Continuation Problem
■話し手により修正が行なわれると、聞き手はその修正がO(=original utterance)のどの部分に続くものなのかを以下の方法で判断する。
・The Word-Identity Convention:Rの最初の単語がOのある単語と同じ
(54) Right to yellow – er – to white
(55) *And at the bottom of the ø line a red dot – a (→the○) vertical line
・The Category-Identity Convention:Rの最初の語の統語範疇がOのある語のそれと同じ
(56) Down from white is a red node and from – pink node (ともに形容詞)
(57) *And then again a stretch to a red patch – stripe ※最後に名詞のpatchがある
12.3.4 Prosodic Marking in Self-Repair
■話し手は修正するときにprosodic markingを行なう場合がある。通常、発音の単なる誤りに対してmarkingはされない(e.g., unsigned⇒unsiledと発音してしまった)。markingが行なわれやすいのは意味的な修正が行なわれたときである。
12.3.5 Repairing on the Fly
■実際には修正なのか、そうじゃないのか微妙なのもある。
(61) That’s the only thing he does is fight.
(63) Who did you think else would come?
<コメント>
ついに1冊が終わった(実際は11章を飛ばしているけれど…)。内容の濃い1冊だったので、かなり詳細を端折りながら発表してきました。発表に協力していただいた高波さんと伊藤さん、本当にお疲れさまでした。

ご意見やコメントがあればこちらまでお寄せください。