2007�N�x ������g�b�v�ɖ߂�
11/30�@�@1/11�@�@1/25�@�@2/8�@�@2/29�@�@3/14�@�@2008�N�x�̔��\���������͂�����
���T�E�O�Y���q (2002). �w�O���t�B�J�����ϗʉ�́x�i����Łj. ���㐔�w��.
2007/11/30
��1�́@��A����
1.1 ���É��i�̗v�����́F�f�[�^
����g���^�}�[�NII2000��̒��Îԉ��i(�]���ϐ�)�̌���v�����A���i(���~)�A���s����(10000KM)�A��ԔN��(�N���̌Â�)�A�Ԍ��̎c�����(����)�Ƃ����Ɨ��ϐ�����T��B
1.2 �P��A����
���P��A���́F2�����f�[�^�ɂ��܂����Ă͂܂钼���ɂ���ĕ��͂�������@
���}1.1�̉�A�����F���i��142.25�|13.23�~�N���G1�N�Ŗ�13���~�̉���
����ԔN���ɂO�������Ă��V�ԉ��i�͗\���ł��Ȃ��B�N���̒l�ɂ�2�`10�܂ł��܂܂�Ă��邩��ł���B
�˂��̂悤�Ȣ�O�}��͂��Ȃ������ǂ��B
�� �܂��A��ԔN���݂̂ŐV�ԉ��i�����m�Ɍ��肳��Ȃ�
���i�����{���~�N���{e1
��e1; �N���ȊO�̏��v��(�f�[�^�����A�����܂ł̏c���̒���)- �덷
�˃�; (��)��A�W��
�� ������p�X�}�ŕ\���Ɛ}1.2�̂悤�ɂȂ�B
�� ����W��(�d���W����2��Gsquad multiple correlation(SMC))
�@�@�@R^2��0.83
��1�ɋ߂��Ȃ�قǓƗ��ϐ��ɂ��\�������m�ɂȂ�B
�� �P��A�W���̏ꍇ�A����W���͑��W����2��Ɠ������B
�@�@�@r=�|��0.830=�|0.911
1.3 �d��A����
�����s�����ƎԌ��Ƃ����Ɨ��ϐ����܂߂ďd��A���͂��s���ꍇ�A���̂悤�Ȏ��ɂȂ�B
�@�@�@���i�����{��1�~���s�����{��2�~��ԔN���{��3�~�Ԍ��{e1�@(�}1.3)
���d��A���͂ł͓Ɨ��ϐ��Ԃɑ���(�����U)���F�߂���@�ˑo�����̖��
�� ��ԔN���̕Ή�A�W����2���|12.67�͐}1.2�̉�A�W�������������B
�ˑ��̗v��(�����E�Ԍ�)�����ł���ꍇ�A1�N��12.67�����l��������Ƃ����Ӗ�
�� �e�v���̕Ή�A�W��(��Βl)�̑傫����P����r���邱�Ƃ͂ł��Ȃ��B
�ˑS�Ă̕ϐ��̕��U��1�ɌŒ肵�A�W��������K�v������B�Ή�A�W���͒P�ʂɈˑ����邽�߁A�P�ʂ��قȂ�Ɨ��ϐ��Ԃ̃��ڔ�r���ł��Ȃ����߂ł���B(�}1.4)
�� �W�������s���ƁA�����U�͑��W���ƂȂ�B
�˓Ɨ��ϐ��Ԃ̑��ւ��傫���ƓK�ȕ��͂��s���Ȃ��\������������(���d������)�A�p�X�}�ɂ͑��W���̐���l���܂߂�K�v������B
�� �덷�̐���le1 (0.32)���玟�̂悤�Ȍv�Z�ɂ���čŏI�I�Ȍ���W�������߂���B
�@�@�@R^2=1�|0.32^2=0.90
1.4 �����U�\�����͂�
���{�߂ł̒���_�F
(i)��ԔN�����牿�i�ւ̉e���̑傫�����P��A���͂Əd��A���͂ňقȂ�B
(ii)�Ԍ���2�N���Ƃɍs���邽�߁A��ԔN���E���s�����Ƃ͖��W�ł���B
�|���s�����ƎԌ��̎c�肪���ł���Βl������12.67���~�����A��ʓI��1�N�Â��Ȃ邲�Ƃɑ��s�����������邽�߁A13.23���~�l��������ƍl���邱�Ƃ��ł���B
��
����1�F�����ԏ��Ƒ��s�����������Ȃ�A���̌��ʒ��É��i����������B
����2�F�Ԍ��̎c��́A���s�����E��ԔN���Ɩ����ւȂ̂ŁA�Ɨ����ĉ��i�ɉe������B
�� �d��A���f����(1)�]���ϐ���1�A(2)�Ɨ��ϐ��Ԃɂ͎����I�ɑ��ւ��ݒ肳��邽�߁A�}1.5�̂悤�ȋ����U�\�����͂ɂ��p�X��̓��f�����K�v�ƂȂ�B
�� ���s���������Ȃ�Ώ�ԔN���͉��i�ɉe�����Ȃ��Ƃ����z��͏d��A���f���Ɩ������邽�߁A���̃��f���͊��p�����\��������B�ˎ��͂Ō���
1.5 �����U�Ƒ��W��
�� n�l�̔팱�҂��獀��X, Y�ɂ��Ẵf�[�^���̂����Ɖ��肵�AX�̕��Usxx, Y�̕��Usyy, X��Y�̋����Usxy���v�Z����B
�� ���W��: �����U��X��Y�̕W�����Ŋ���������
�@�@�@rxy = sxy/��sxxsyy�@�� rxy = 0 ���� sxy = 0
�� �܂�A�f�[�^�̕��U��sxx��syy���P�ƕW��������Ă���Ƃ��A�����U�Ƒ��֊W�͈�v����Ƃ�����B���W�������ꂽ���A�����U�����W���ɂȂ闝�R
�� ���U�����U�s��(�\1.2)�̉E��͏ȗ������B
�� �{���ł͕�W�c�ƕW�{�̋�ʂ͍s��Ȃ��B
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�i����j
�E ���W���́A�f�[�^�̕��U��1�ŕW��������Ă�����̂��Ƃ������Ƃ��͂��߂Ēm�����B�]���āA�W����A�W���ɑΉ�������̂����W���Ƃ������ƂɂȂ�̂ł��낤�B
�E ���U�����U�s��́A�Ίp���̕��������U�ł���ȊO�̕����������U�������Ă���BAPA�ł̑��֍s��͉E����c���悤�ɂȂ��Ă��邪�ASEM�ł͍����̍s����c���悤�ɂȂ��Ă���̂��낤���B
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�i�X�{�j
�y�[�W�g�b�v�ɖ߂�
2008/01/11
��2�́@AMOS, EQS, CALIS���̌��F�p�X��͂Ƒ��d�w�W����
2.1�@�ϐ��ƃp�X�}
����A���͂ł͓Ɨ��ϐ�(�����n�ϐ�)�Ə]���ϐ�(���ʌn�ϐ�)�̋�ʂ͖��m�ł��邪�A�����U�\�����͂ɂ����Ă͈قȂ�B
��1�����̖���1���Ă��Ȃ��ϐ����Ɨ��ϐ��ŁA1�ł��Ă�����]���ϐ�
�� �܂��A�ϐ��͈ȉ��̂悤�ɋ�ʂ����B
���ݕϐ��F��m�\����肪�����L�\������̒��ڊϑ��ł��Ȃ��ϐ����w���B�ۂ�~���ň͂܂��B
�ϑ��ϐ��F�u���s�����v����i����̒��ڊϑ��\�ȕϐ��B�ʏ�l�p�ň͂܂��B
�ˌ덷�ϐ��͐��ݕϐ��̈ꕔ�ł��邪�A�ۂň͂ނ��ǂ����ɂ��Ă͈ӌ����������B
2.2�@�p�X��́F���Îԉ��i
�� �p�X��͂̕��͂͑��֍s��̌�������n�܂�(�\2.1�Ap.14)�B
�E ����i��Ƣ��ԔN����̊Ԃɋ������̑���(r = -.911)�B
�E ��Ԍ���Ƣ���i��ɕ��̑���(r = -.085)�c�H
�� ��������ɂ����p�X��̓��f��(�}2.1�Ap. 15)�́A�ȉ��̗��R�Ŋ��p�����B
1.����s������Ƣ�Ԍ�����碉��i���\������d��A���̌���W��(R^2 = .26)�́A�P��A����(R^2 = .83)��d��A����(R^2 = .90)�Ɣ�ׂđ啝�ɒႢ�B
2.��\�I�ȓK���x�w�W�ł���J�C���l(�J�C���l��23.03�Adf = 3�Ap = .000)�ɖ�肠��B
�˃f�[�^�ƃ��f���̋����ƃJ�C��敪�z�̔�r�ł���A�L�Ӑ���5�����傫���ƃ��f�������p
�� ����s����������ł����Ă��Â��Ȃ����i���������Ƃ����d��A���͂̌��ʂ��l�����A���ԔN������碉��i��ւ̃p�X�����������f�����ēx��������(�}2.2, p.16)�B
�� ����W��(R^2 = .90)�A�K���x�w�W(�J�C���l= 1.03, df = 2, p = .5972
)����A���f���̓��Ă͂܂�͗ǂ����Ƃ�������B
�� �p�X��͂͏d��A���͂̌J��Ԃ��ŁA�]���ϐ����ƂɎ��̂悤�ȉ�A���͂��s���Ă���B
���i���@��0�{��1���s�����{��2��ԔN���{��3�Ԍ��{�덷
���s�������@��'0�{��'1��ԔN���{�덷'
�� �P��A���͂̌��ʂƔ�r���Ă݂�Ɓc
�|13.23 =(nearly equal) �|12.67�{.26�~(�|3.61)=13.61
�� ���ԔN�����1������ƁA���i��12.67���~������B�X�ɁA���s������.26�����A.26�~(�|3.61)�������i��������B
���ԔN����ˢ���i��c���ڌ���
���ԔN����ˢ���s������ˢ���i��c�Ԑڌ���
���ڌ��ʁ{�Ԑڌ��ʁ��������ʁ@�ˁ@�P��A���͂ł͂��̑������ʂ����߂��Ă���B
2.2.1�@AMOS
AMOS Basic
�� �e�L�X�g�`���̃��f���t�@�C�����쐬���ĕ��͂��s���B�p�X�}�͂Ȃ��B�������A�ϐ���p�X�̐�����������A�ϑ��ϐ��Ԃ̕��U�E�����U�A���W�����v�Z����ꍇ�ɂ͕֗�(�}2.5, p21)
�� �e�L�X�g�t�@�C����Excel, SPSS�̃t�@�C����ǂݎ��\�B���͂̍ۂɂ�1�s�ڂɂ͕ϐ����A�e�L�X�g�t�@�C���̏ꍇ�̓J���}�ŋ��K�v������(�}2.4, p20)�BExcel�̏ꍇ�͂���ɉ����ăo�[�W���������K�v�ƂȂ�B�v�Z���ʂ͐}2.5�D
AMOS Graphic
�@����
�� �܂��͍ŏ��̉�ʂŁA�f�[�^�t�@�C�����w�肷��BFile��Data Files��File Name��I�����A�ۑ����Ă���t�@�C����I������B�c�[���o�[����͈ȉ��̃A�C�R�����N���b�N����B

�A�p�X�}��`��
�� View/Set��Interface Properties��Page Layout��Rotation��Landscape�̏��ɑI�����Ă����ƁA�`��̈悪�������ɕς��B
�� 4�̕ϐ�(i.e.,��ԔN���A���i�A�Ԍ��A���s����)���������߂Ɉȉ��̃A�C�R�����N���b�N����B

�� �h���b�O&�h���b�v(�ȉ��AD&D)�Œ����`��`���B�傫�����C�ɓ���Ȃ��ꍇ�͒����`���E�N���b�N���@Shape of Object��I�����AD&D�ő傫����ύX����B
�� �X�ɉE�N���b�N��Copy��I�����A�I�u�W�F�N�g���ړ�������ƃR�s�[�������B4�����`��p�ӂ���(�}2.10�Ap25���Q��)�B�ȉ��̃A�C�R�����N���b�N�ł��B

�� �ȉ��̌덷�ϐ��̃A�C�R�����N���b�N���A�E2�̒����`��ł�����x�N���b�N�B�N���b�N���ɒ����`��ł̌덷�ϐ��̈ʒu���ω����Ă����B

�� ���̂Ƃ��A�덷�ϐ��̃T�C�Y���傫���Ȃ�̂ŁA  ��I�����A�덷�ϐ��́��Ɩ���1���N���b�N���A�I������B������
��I�����A�덷�ϐ��́��Ɩ���1���N���b�N���A�I������B������  ���N���b�N���āA���݂̂��h���b�O&�h���b�v�ňړ�������Ɩ�Z���Ȃ�B
���N���b�N���āA���݂̂��h���b�O&�h���b�v�ňړ�������Ɩ�Z���Ȃ�B
�� ���ʂ�\���p�X�����邽�߁A�ȉ��̃A�C�R�����N���b�N���AD&D�Œ����`�̉����牏�փp�X��`���B���s������Erase�ŏ����B�������͏�L�̎菇��move.
�B�f�[�^�̓���
�� �܂��͕ϐ�������͂���BView/Set��Variables in Data Set��I������ƁA�}2.9(p.24)�̂悤�ȃE�B���h�E���\�������B�e�ϐ�����D&D�Ŋe�����`�Ɉڂ��B�܂��A�ȉ��̃A�C�R�����N���b�N���Ă��B

�� �덷�ϐ����́A�덷�ϐ����_�u���N���b�N��Object Properties�AVariable Name��"e1"�Ɠ��́B�덷�ϐ��������ꍇ�́ATool��Macro��Name Unobserved Variables��I������ƁA�S�Ă̌덷�ϐ��ɏ��ɓ��͂����B
�� �ϐ��̕\����View/Set��Variables in Model(�}2.9)�A�������� 
�� �����܂łň�x�ۑ������܂��傤�B
�C�v�Z
�� �܂��AView/Set��Analysis Properties��Output�A��������  �ŏo�͂̏�����ݒ肷��B�}2.11(p.26)�̂悤�ȃE�B���h�E���o�Ă���̂ŁA"Minimization history," "Standardized estimates," "Squared multiple correlation," "Indirect, direct & total effects"�Ƀ`�F�b�N�}�[�N������B
�ŏo�͂̏�����ݒ肷��B�}2.11(p.26)�̂悤�ȃE�B���h�E���o�Ă���̂ŁA"Minimization history," "Standardized estimates," "Squared multiple correlation," "Indirect, direct & total effects"�Ƀ`�F�b�N�}�[�N������B
�� ������  ���N���b�N���ă��f���̌v�Z���s���B
���N���b�N���ă��f���̌v�Z���s���B
�� �ȉ��̂悤�Ȍx�����o��B����͓Ɨ��ϐ��Ԃɂ͑��ւ�����̂����ʂȂ��߂Ɍx�����o�邪�A����͈Ӑ}�I�ɓ���Ă��Ȃ��̂�"Proceed"
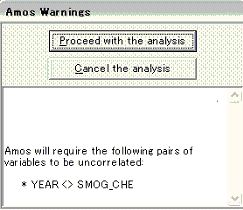
��  ���N���b�N����ƁA��W�����W�������ꂼ��\�������B�X�Ƀp�X�}�ׂ̗ɂ���"Standardized estimates"���N���b�N����ƁA�W�������ꂽ�p�X�W���̐���l�ɐ�ւ��B�Mileage��ƢPrice��̉E��̐��l���d���W����2��A�܂茈��W���ƂȂ�B
���N���b�N����ƁA��W�����W�������ꂼ��\�������B�X�Ƀp�X�}�ׂ̗ɂ���"Standardized estimates"���N���b�N����ƁA�W�������ꂽ�p�X�W���̐���l�ɐ�ւ��B�Mileage��ƢPrice��̉E��̐��l���d���W����2��A�܂茈��W���ƂȂ�B
�� ���茋�ʂ̏o�͂́AView/Set��Text Output�A��������  ���N���b�N���ANotes for Model��I���B
���N���b�N���ANotes for Model��I���B
�� p = .000�̂��߁A���̃��f���͊��p�����B
�D���f���̏C��
��  ���N���b�N���āA�Mileage�����Price��փp�X������(�}2.4, p.29)�B�����ĕʖ��ŕۑ��B����܂łƓ��l�̎菇�ŕ��͂�i�߂�B
���N���b�N���āA�Mileage�����Price��փp�X������(�}2.4, p.29)�B�����ĕʖ��ŕۑ��B����܂łƓ��l�̎菇�ŕ��͂�i�߂�B
��
�� ���N���b�N���ăe�L�X�g�o�͂��m�F�B���x�͍̑����\�ƂȂ�B
�f�B�X�J�b�V�������R�����g
�E�]���̑��ւ��A���͂Ƃ̓X�P�[����l������傫����ւ���K�v����B�����A���K�ɂ͊w���]���ł�����A�g���₷����̌�����̂��悢�B�������A�g����p�X�ƕϗʂ̐��������Ă���i���ꂼ��T�O�A�W�i���m�F�j�j�̂Œ��ӁB
�E���f���̂��Ă͂܂�����肷��J�C���挟��̋A�������́A�u���f���ƃf�[�^�́A�K�����Ă���v�Ƃ������Ƃ��납�B�L�ӊm�����K��l�i�T���^�P���j�������ƁA���f�����f�[�^�̗\���ɖ𗧂��Ȃ����Ƃ�������B
�y�[�W�g�b�v�ɖ߂�
2008/01/25
2.3�@���d�w�W���́F���R�H�i�̍w���s���̃f�[�^�ipp. 50-56�j
2.3.1�@�͂��߂�
�� �w�H���ӎ��̍����l�͎��R�H�i�X�ł̍w���ӗ~�������x�Ƃ������ۓI�ȕ\���ɂ����āA�u�H���ӎ��v�Ƃ͉����w���̂��낤���B
�� �L�@���_�����l���A���܂����H���̎��Ԃ╠�����ڂ����l���u�H���ӎ��v�������ƌ�����B
�� �u�H���ӎ��v�Ƃ����\���ɓ��B����܂łɁA�����̑��ʂ��P�����⎟���k�������Ƃ����v���Z�X���o�邪�A���̃v���Z�X�������ϗʉ�͂̒��ł���B
�� �{�͂ł͑����̑��ʂ�������T�O��P�����⎟���k�����ĕ��͂����邽�߂́A�u���ʕϓ��̔w��ɐ��ݕϐ���z�肷��v�Ƃ������@����舵���B
2.3.2�@�f�[�^
�� �����ł́u�H�i�Y�������C�ɂ�����h�{�̃o�����X���C�ɂ���l�͎��R�H�i�X�ł悭������������v�Ƃ��������������A�u�悭�v�Ƃ͂ǂ̒��x�Ȃ̂���������B
�� �f�[�^�͕\2.9(p51)�̑��֍s��\�Ɏ����Ă���B
�� �h�{�̃o�����X(X1)���l����l�͐H�i�Y����(X2)�ɂ��C���g���Ă���ƍl�����邽�߁A���҂ɂ͐��̑��ւ��l������(r = .30)�B
�� ���̑��ւɉe������v���Ƃ��ĐH���ӎ�(F1)�Ƃ������ݕϐ������肷��(�}2.27��, p51)�B
�ˁ@�H���ӎ���������o�����X�ɂ��Y�����ɂ��C���g��
�� ���R�H�i�ւ̍w���ӗ~(F2)��������w���z(X3)�Ɖ�(X4)�Ƃ������Ȃ�ƍl������B
2.3.3�@���ݕϐ��Ԃ̊W
�� �H���ӎ���������Ύ��R�H�i(F1)�̍w���ӗ~(F2)�������ƍl����͎̂��R�ł��邽�߁A�}2.28(p52)�̂悤�ȃ��f�������肵�AF1��F2���ǂ̒��x��������̂��ׂ�B
�� d2(Disturbance; �h���ϐ�)��F2���K�肷��F1�ȊO�̉e���v���̏W���̂ł���B
�� ���f���̕W����(�}2.29, p52)�̌��ʂ̓�2��l��.43�Adf=1, p=.51�ƂȂ�A�K���x�͗ǍD�ł���B
2.3.4�@�W�����̉���
�� �}2.29�ł͐H���ӎ�(F1)�ƍw���ӗ~(F2)�̗����ݕϐ��̕��U��1�ɕW��������Ă���B
�� F1����F2�ւ̃p�X�W��(���W��).56�͑傫���ƌ����邾�낤���B
�� ��܂��ɁA�Y����(X1)�ƃo�����X(X2)���w���z(X3)�ƍw����(X4)��������Ă���ƌ����邪�AX1, X2��X3, X4�̑��W��(�\2.11, p53)������ƁA.56�ɂ͉����y�Ȃ��B
�� �����́A�Ⴆ��X1����X3�����ԃp�X��̑S�Ă̌W���̐ςɂ���ĎZ�o�����B
�� �������Ȃ�̂́A.56��2�̑��W���������Ă��邩��ł���B�܂葊�W�����P�Ȃ�A.56�ƂȂ�B
�� X(�ϑ�)��F(����)�̊Ԃɂ́AX=F+e�Ƃ����W�����藧���߁A����X��F�̑��W�����P�Ȃ�Ό덷(e)�͂O�ł���B
�� �ϑ��ϐ��Ԃ̑��ւ�.56�����Ⴍ�Ȃ�̂́A�덷�̉e���ł���B�܂�A�ϑ��ϐ��Ԃ̑��W���͌덷���܂߂Čv�Z����Ă��邽�߁A�{���̑��W�������߂���(��;attenuation)����Ƃ�����B
���ӓ_�F
�� ���ݕϐ��̕��ς╪�U�͔C�ӂɐݒ�ł��邽�߁A�l�Ƃ��ā|1����{1��0�`100�Ƃ����͈͂ł���肪�Ȃ��B����������̍ۂɖ�肪�N���邽�߁A���U���Œ肷��K�v������B
�� �Ɨ����ݕϐ�(F1)�̕��U��1�ɌŒ肳��邪�A�]�����ݕϐ�(F2)���Œ肷��͖̂��ł���B
�� F2����ϑ��ϐ��܂ł̃p�X�W���̂���1��1�ɌŒ肷�邱�ƂɂȂ邪�A���̐���̉��ł͐���l�͐}2.30(p54)�̂悤�ɂȂ�B
�� ���̂��߁AF2�̕��U��1�ɂȂ�悤�ɌŒ肳�ꂽ���̂��}2.29�ł���B
2.3.4�@�u�v�l��P��������v
�� ��P������Ƃ́A�����̑����̑��ʂׂ̍������قɂƂ��ꂸ�A��ǓI�Ɍ��邱�ƁB
�� ���ۓI�ȊT�O(e.g., �H���ӎ�)�ɂ͗l�X�ȗv�f���֘A���Ă���A���ꂼ�ꂪ���̊T�O�Ɋւ��鋤�ʍ��������Ă���B���̋��ʍ��ŕ��������邱�Ƃ��u��ǓI�v�Ȃ̂ł���B
e.g., �Y�����A�o�����X�@�ˁ@�H���ӎ��Ƃ������ʍ�
�� ����2�̊ϑ��ϐ���H���ӎ��̎w�W(indicator)�Ƃ����B�ړI�ɉ������w�W�̑I�����K�v�B
2.3.5�@���ݕϐ��̈Ӌ`
�� ���ݕϐ���p�����A�ʏ�̉�A����p������ǂ��Ȃ邩�B�}2.31(p55)�̃��f���̐���l����A���Ă͂܂�͈����Ƃ�����B��2��l=233.32, df=1, p=.000
�� �����X3, X4�̌덷���U���r�����(�\2.12)�A���̒l�́A���d�w�W���f�������傫�����Ƃ��킩��(�����͂�����)�B
�� ��ɐ��ݕϐ���p�������͂��ǂ��Ƃ͌���Ȃ����Ƃɗ��ӂ���K�v������B�ϑ��ϐ��̑��ւ����ݕϐ��ɂ���Đ��������Ƃ��̂ݗL���ƂȂ�B
�y�[�W�g�b�v�ɖ߂�
2008/02/08
pp. 56-61: ���ݕϐ��̕`����
1. �g�p�f�[�^
�� �{���Ɋ�Â��G�N�Z���ɂđ��֍s��\���쐬�����̂ł�����f�[�^�Ƃ��Ďg�p����B(�t�@�C����: AMOS 20080208)
�� ����f�[�^���Z�b�g����B
2. �p�X�}��`��
�� �܂��}2.29�̍�������`���B �Ŋϑ��ϐ���2�A �Ō덷�ϐ���2�A  �Ő��ݕϐ���`���A �Ńp�X������B
�Ő��ݕϐ���`���A �Ńp�X������B
�� �܂��A  ���g���ƁA��C�Ɋϑ��ϐ��{���ݕϐ��{�덷�ϐ���`�����Ƃ��ł���B�}�̏���N���b�N�����ɉ����Ċϑ��ϐ��{�덷�ϐ��̐���������B
���g���ƁA��C�Ɋϑ��ϐ��{���ݕϐ��{�덷�ϐ���`�����Ƃ��ł���B�}�̏���N���b�N�����ɉ����Ċϑ��ϐ��{�덷�ϐ��̐���������B
��  ���g�p�����ݕϐ��̏���N���b�N����ƁA�ϑ��ϐ��̈ʒu��ς��邱�Ƃ��ł���B
���g�p�����ݕϐ��̏���N���b�N����ƁA�ϑ��ϐ��̈ʒu��ς��邱�Ƃ��ł���B
�� ����ƍ��킹�āA (�I��)�A  (�S�̑I��)�A
(�S�̑I��)�A  (�I������)�A (�ړ�)�A (�R�s�[)�A
(�I������)�A (�ړ�)�A (�R�s�[)�A  (�傫���̕ύX)��K���g�p���āA�`�𐮂���B
(�傫���̕ύX)��K���g�p���āA�`�𐮂���B
�� �`�𐮂�����A�S�̂��R�s�[���A����1�Z�b�g���쐬����B�X�Ɍ`�𐮂��A���ݕϐ��ԂɃp�X�������A��ڂ̐��ݕϐ���Ɍ덷�ϐ���lj�����B
3. �ϐ��ɖ��O������
�� ����Ή�����ϑ��ϐ��Ƀh���b�O&�h���b�v�Ńf�[�^�Ă͂߂Ă����B
�� Tool �� Macro �� Name unobserved variables �����s���A�c��̕ϐ��ɖ��O������B
�� F1����"balance"�ւ̃p�X���1���\������Ă���ꍇ�A�p�X���E�N���b�N �� Object parameters �� parameters �ŁAregression weight�ɕ\������Ă���P���폜�B
�� ���ݕϐ�F1�EF2���_�u���N���b�N���AText ����Variable names�Ɂu�H���ӎ��v�Ɠ��́BF2�ɂ́u�w���ӗ~�v�B�����e5 �� d2�ɕύX�B
�� �u�H���ӎ��v��ʼnE�N���b�N�� Object parameters �� parameters�ŁAVariance�Ɂu1�v�Ɠ��́B����ŕ��U��1�ɌŒ肳�ꂽ�B
4. �}�Ƀ^�C�g��������B
��  ���N���b�N���A�}2.35�ip.59�j�̂悤�Ƀ^�C�g������́B�u���f�����艻�v�̕����ɂ�\format�Ɠ��́B
���N���b�N���A�}2.35�ip.59�j�̂悤�Ƀ^�C�g������́B�u���f�����艻�v�̕����ɂ�\format�Ɠ��́B
5. �v�Z
�� ���番�͂̃v���p�e�B���J���āA"Minimization history," "Standardized estimates," "Squared multiple correlation," "Indirect, direct & total effects"�Ƀ`�F�b�N�}�[�N������B
�� ������ �������Čv�Z���J�n����B
�� �������ĕ��͌��ʂ�}��ɕ\��������B�X�ɁA���̂������ɂ���"Standardized estimation"���N���b�N���A�W�����W����\��������B
�� �}2.36(p. 60)�̂悤�ɂȂ�ΐ����B
�y�[�W�g�b�v�ɖ߂�
2008/02/29
��3�́@���q����
���q���͂̎��
�T���I���q���́F�f�[�^����\����T��
���ؓI���q���́F���炩�̉�������Ƀf�[�^�ƏƂ炵���킹�č\����T��
�� �����U�\�����͂ł͌��ؓI���q���͂��ł��ǂ��g����B
�� �T���I���q���͂͌��ؓI���q���͂��s�����߂̎��O���͂Ƃ��Ĉʒu�t������Ă���B
�� �T���I�E���ؓI�Ɋւ�炸���q���͂ɂ����鋤�ʂ��������͈ȉ���2�_�ł���B
(1) ���ݕϐ��̉e���ɂ��ϑ��ϐ��Ԃ̑��֊W��������B�ϑ��ϐ��Ԃɂ͈��ʊW�͉��肳��Ȃ��B
(2) ���ݕϐ��͑S�ēƗ��ϐ��ł���B���ꂼ��̊Ԃɂ͈��ʊW���z�肳��Ȃ����A���֊W�͋��e����邱�Ƃ�����B
���ݕϐ��F���ʈ��q�A�܂��͈��q
�덷�ϐ��F�덷���q(error factor)�Ɗe�ϑ��ϐ��̕ϓ���\��������q(specific factor)�̑��a
���q����(��)�F���q����ϑ��ϐ��ւ̃p�X�W��
3.1�@���ؓI���q���͂ƒT���I���q���́F�l����
�� Lawley-Maxwell (1963)��6�Ȗڂ̃e�X�g����(n=220)���f�[�^�Ƃ��Ďg�p����(p.74�\3.1 )�B�@
�� �S�Đ��̑��ւƂȂ��Ă��邪�A�u����Ȗڂŗǂ��_�����鐶�k�͑��̉Ȗڂł�����Ȃ�ɗǂ��_�����X���ɂ���v�Ƃ������Ƃ������B
�� �����̑��ւ́u��ʒm�\�v�Ƃ����\���T�O�ɂ���Đ��������B�c��̕ϓ��͑��ւ����肳��Ȃ��e�ȖړƎ��̕ϐ��{�덷�ɂ���Đ��������B���u�X�s�A�}���̓���q���v
�� �u��ʒm�\�v�͒��ڊϑ��ł��Ȃ����ߐ��ݕϐ�(F1)�ː}3.1�̃��f�������肳���(p.75)�B
�� ���̃��f���ł́AX1��X2�̑��ւ̓�1�~��2�ƂȂ�A���w�I�ɏ�L�̉���(1)���������B
�� �܂��A���̃��f����������ł���킷��p.76�̂悤�ɂȂ�B
�� ��ʒm�\(F1)���������Xi�͑S�đ傫�Ȓl�����X���ɂ���ƌ�����B
�� �������A�ϑ��ϐ��ɌŗL�̃����_����ei�̉e��������̂ŁA�K��Xi�̒l���傫���Ȃ�Ƃ͌���Ȃ����Ƃɗ��ӂ���K�v������B
�����̐��ݕϐ��̉\���F���ؓI���q����
�� �e�X�g�Ȗڂ����n(X1, 2, 3)�Ɨ��n(X4, 5, 6)�ɕ��މ\�ł��邽�߁A�O�҂͕��ȓI�\�́A��҂͗��ȓI�\�͂ɂ���Ă��ꂼ��̑��ւ������Ă���ƍl���邱�Ƃ��\�ł���(p.76, �}3.2)�B
�� ���ݕϐ��Ԃɑ��ւ��z�肳��邪�A���ʂ�z�肷��ƈ��q���͂ł͂Ȃ��Ȃ�B
�� ���ȓI�\�͂͗��n�ȖڂɁA���ȓI�\�͕͂��n�Ȗڂɉe�����Ȃ��Ƃ������������Ɋ�Â��Ă��邽�߁A����͌��ؓI���q���͂Ƃ�����B�ˁ@���O�ɉ��炩�̉������K�v�B
�T���I���q����
�� �S�Ă̈��q���S�Ă̊ϑ��ϐ��ɉe����^����Ƃ������f��(p.77, �}3.3)�͒T���I���q���͂�\���B
�� ���̃��f���̓��Ă͂܂�������A�����Ċe���q����̉e���̓x����(�召)��T��������ŏ��߂ď�L�̌��ؓI���q���͂ŗp�������������藧�B�܂��A��ʂɂ͈��q�̐����T������B
�� �܂�A������������̂����ؓI���q���́A�������\�z����̂��T���I���q���͂ƌ�����B(���ꂼ��̗����p.78, �}3.4�A3.5)
�y�[�W�g�b�v�ɖ߂�
2008/03/14
AMOS�ɂ����q���͂̍s����
1�}3.9(p. 80)�̐}��`��
�� AMOS�̐}��ۑ�����ƁA�������̃t�@�C�����o���Ă��܂��̂ŁA���炩���ߕۑ��p�̃t�H���_���쐬���Ă����ƕ֗��ł��B
�� AMOS graphics�𗧂��グ�A ���N���b�N����Excel�̃t�@�C��(AMOS 2008-3-14)��Sheet 1����荞�ށB
�� �}3.9�̂悤�Ɋϑ��ϐ� �A���ݕϐ� �A�덷�ϐ� �A�p�X ��`���B
�� �`���I������ ���N���b�N���āA�}3.9�̂悤�ɂ��ꂼ��̕ϐ����h���b�O���h���b�v�Ŋe�ϑ��ϐ��ɓ��͂��Ă����B���ɕ`���ꂽ���ݕϐ����_�u���N���b�N��ATEXT�̃^�u��I�����Avariable names�Ɂu��ʒm�\�v�Ɠ��͂���B�܂��A���̂Ƃ���Parameter�̃^�u���N���b�N���AVariance�ɂP�Ɠ��͂���B
�� �Ō��Tool �� Macro �� Name unobserved variables��I�����A�덷�ϐ��ɖ��O������B
�� ���N���b�N���āAp. 81�̂悤�ɓ��͂���B
�J�C2��l (���R�x) = \cmin (\df) p�l = \p
GFI = \gfi CFI = .854 RMSEA = \rmsea |
�� �Ō�� ���番�͂̃v���p�e�B���J���āA"Minimization history," "Standardized estimates," "Squared multiple correlation," "Indirect, direct & total effects"�Ƀ`�F�b�N�}�[�N������B
�� �v�Z ���s���B
�� �������ĕ��͌��ʂ�}��ɕ\��������B�X�ɁA���̂������ɂ���"Standardized estimation"���N���b�N���A�W�����W����\��������B
�� �}3.9�̂悤�ɂȂ�ΐ����B�������A���f���̓K���x���������߁A�C�����s���B
2.���f���̏C��(�}3.11, p. 83)
�� ���N���b�N���ăp�X�}��`�����[�h�ɖ߂�B
�� ���ʒm�\�����L�тĂ���p�X�������A �Ţ��ʒm�\����E�Ɉړ�������(p. 82, �}3.1�Q��)�B
�� ���ʒm�\��������ɃR�s�[���A�ϐ����������炻�ꂼ�ꢕ��ȓI�\�ͣ�Ƣ���w�I�\�ͣ�ɕύX����B
�� ����ȓI�\�ͣ���碃Q�[���ꣁA��p�ꣁA����j��ɁA����w�I�\�ͣ���碌v�Z��A��㐔��A���ɂ��ꂼ��p�X��`���B�܂��A�����ݕϐ��ԂɈ��q�ԑ��� ������B
������B
�� �f�[�^�ɓK���������f���ƂȂ�B

�y�[�W�g�b�v�ɖ߂�
���ӌ���R�����g�������������܂������������B