研究会トップに戻る
4/20 5/11 5/18 6/1 7/13 7/26 8/24 9/14 9/28 10/13 10/26
Linacre, J. M. (2006). A user's guide to FACETS. Chicago: MESA Press.
第2回 4/20発表分
5. Introduction(仕様)(p.3)
Facetsは色々な場面でのラッシュモデル適用に、Windows上(本マニュアルのver. 3.xxの場合)で援用可能なソフトである。特にパフォーマンス評価や対データの比較に適している。より単純なところからラッシュモデル解析の概念や操作に慣れるには先行プログラムのWINSTEPSがある。また、www.winsteps.comのサイトでもトレーニングセミナー情報がみられる。
(p.4)
このマニュアルの内容
①Facetsの操作方法
②多相ラッシュモデル(MFRM)解析を使って、質的かつ順序化された数値を線形的に解釈可能にする方法。
→MINIFAC(学生評価版)からも観測の一部制限を除いてMFRMの利用が可能
観測値Xについて影響する要因がnmijと定義するとき、期待値は以下のMFRM基本公式で説明可能
log ( Pnmijk / Pnmij(k-1) ) = Bn - Am - Di - Cj - Fk
この場合、
Bn は受験者の能力
Am はタスクの困難度
Di は項目の困難度
Cj 評価者判断の厳しさ
Fk 評価の分かれ目
Pnmijk は観測値がkの値に分類される確率.
Pnmij(k-1) 観測値でkより1低い値に分類される確率.
facet(相)とは受験者、タスク、項目、評価者などを表しており、4ページの例で説明するなら、「メアリー(n)が『動物園での一日』(m)という作文を書いて、スミス氏(j)が句読(i)に気をつけて読んだ場合に下す判断(k)」に関わる全てを線形得点、標準誤差、フィット統計値(統計的妥当性を表わす値)。フィット統計値は観測値が予測と逸脱してないか診断するものである。また、たとえば信頼できる項目、段階、ランク付け等をテストの採点尺度から探し出せる。なお、結果報告は図表であらわされ、特に「ルーラー」による表示は専門技術がないユーザーにも扱いやすい。
異なる要素同士で矛盾した相互作用があった場合にも数値化できる。データセットの中に組み込んでしまえば、たとえば項目のはたらきに違いや誤差があった場合でも、それを自動的に分析してくれる。特定項目で起こる評価者の誤差(もしくは受験者に対する項目の測定誤差)に関しても、その規模と統計的有意である見込みを推計できる。
(p.5)
Facetsはエッセイの採点やポートフォリオからの評価など、パフォーマンスを人が判断するテストの分析にふさわしい。また、教育や心理テストに限らず、多彩な研究や実践から出た質的な観測結果を線形的な値に換算するのに使える。
6. The theory behind Facets(Facets の理論背景)
Facets は「多相ラッシュモデル」(Linacre, 1989)の実践を可能にし、要素で相互に作用している結果を概念化する。その要素には、受験者、テスト項目、評価者が考えられるが、独立した作用または互いに混ざり合って影響している状況をモデル化する。例えば、各評価者を単なる機械採点と同じに扱うことなく、それぞれが独立した専門的行為として判断の厳しさ/緩さを特定できる。
こうした観測による順序尺度での値を線形に変換する手段は、デンマークの数学者ラッシュによって考案され、このモデルは、各受験者・各項目を変数化しないが、ロジスティック回帰モデルの形式を持っている。実際のところ、このモデルは1/0で組み合わせたダミー変数を応用して、項目や受験者の変数処理させた回帰モデルに近い。こうした処理は標準的な統計ソフトでも、原理的に推計ができそうであるが、ラッシュ分析で扱うような数百から数千のパラメータに耐えうるソフトはほとんどない。
7. References
ラッシュモデルの理論背景、実践についてもっと詳しく知りたい場合は、6ページ下の文献を参照するとよい。
また7~16ページにかけてMFRMを用いた研究論文の紹介があり、これ以降もwww.winstep.comで主な文献、リサーチ報告が検索可能となる見込み。(現在、最新のもので2005年の論文名までが参照できる)
8. Launching Facets under Windows
To Run Facets: 起動の仕方
アイコンをWクリック、スタートボタンのメニューからはじめる他、コマンドが書かれたtxtファイル (control file) をデスクトップ上のFacetsのアイコンまでドラッグする。
Super-Fast-Track:
Specification file name: 分析したいファイルを開く(Facets を起動したとき、左上のコマンドからもみつかる)
Other specifications?
ファイルを特定すると、小窓が開いて優先事項を聞いてくる
Output file name: 分析準備が終わると、出力ファイルの置き場所、名前を聞いてくる
9. Launching at the DOS prompt (p.17)
Facets は Windows 由来のプログラムなので、DOSモードで運用できない。ただし、Windows上にあるDOSプロンプトからも起動は可能。(DOS上の起動に、どんなメリットがあるのかは不明なので詳細は省略)
10. Opening screen (Windows画面で8についておさらい ―実際に動かした方がよい)
11. File Box - Right-click
Facetsに関連するファイルの中身を見たい場合、右クリックから「送る」→「WordPad」を選ぶのが便利
(WordPadが「送る」メニューにない場合は、追加しておく必要がある ― p.20参照)
12. Other Specifications (p. 20) → 8のおさらい(優先事項)
ほとんどの分析において、何も打ち込まず「OK」で先に進んでよい
13. Report Output File
Facets では常に 少なくとも8つの Table を含んだ Report Output File を出力して分析結果の報告をする。
14. Estimation Progress (p.22)
(Output File の名前が決定し、)必要な情報がファイルの特定によって与えられると計算に移る。
Table 1 特定された情報の重要事項を要約して表示
― 相の数(観測値に関わってクループ化されている変数)
― 成分の数(相の中での異なる値)
→ 開いたファイルが正しいか、上記2つの数を確認するとよい
Table 2 全ての観測値が Total lines in data file で明らかになる(入力ミスはないか?)
Table 3 標準的な方法といわれるPROX法で計算中であることを示す。注目は max. = _ の値が0に近づくこと
23ページ下(Iteration 24)
くりかえし JMLE(結合 最尤推定、または無条件最尤度推定)で計算が続く。
Figure右下から
左の max. = 1.3 → 観測された素点から最大1.3点外れる場合がある
右の max. = -.006 → logit で最大 .006 の変動があることを示唆
ただし、少数第2位までしか表示されない logit でこの誤差は極めて小さい)
この分析からconvergence criteria (基準の集約化) がみられ、必要以上に変動が少ないことを示す
(high-stakes のテストにはよくある)
はやく終わらせたいときは、Ctrl + Fキー または File コマンドから Finish Iterating を選ぶ
15. Report Output
質的統制フィット統計の計算。Table 4 は表の長さの都合で、順番が入れ替わる。
観測された相に定義がされていれば、最後に誤差と成分ごとの相互作用の分析結果の報告が出力される。
16. Output Tables
Table は NotePad または WordPad で直接書き込まれて出力される。
アプリケーションがデフォルトにしているフォントによって、Table が崩れていることがある。
→ Courier New を推奨
17. To stop Facets
ウィンドウ右上の×マーク、またはFileコマンド―Exit を選ぶ
作業中の出力ファイルがある場合、保存をするか確認してくるので必要に応じて Yes / No 選ぶ
(p.26)
Facets は以下のような状況になると、強制的に終了する
1)開いているファイルにエラーがあったとき
2)データに対応がないとき
3)Ctrl + C を押したとき
Facets に iteration までで計算を終了させるには
4)概算自体が収束した場合
5)最大数の iteration をおこなった場合
6)iteration の途中で Ctrl + F を押した場合
計算がどこまで収束しているかは、その値による。最後の iteration table から、全ての値が小さくなっているか確認するとよい。収束値基準 convergence = は、計算のくりかえしに応じ 速く―遅く/正確に―粗く 調整することができる。
(p.26) 18~24 コマンドバー & プルダウンメニュー
18. Edit pull-down menu
Edit = filename テキスト編集ソフトで特定化しているファイルを開く
Edit new file テクスト編集ソフトを新規のファイルとして開始する
Edit from template テキスト編集ソフトへ一般的なスクリプトのパーツを送って開く
Edit initial settings テキスト編集ソフトとして開くアプリケーションを指定、ほか初期設定変更
Copy from screen (Ctrl+C keys) 出力ファイルが出ている場合のコピー
Paste to screen (Ctrl+V keys) コピーした出力ファイルの貼り付け
19. Estimation pull-down menu
計算フェイズの中で操作可能なメニュー
Facets が計算中、最大残余が iteration の割に減少していかない場合、Bigger changes (Ctrl + B)を選ぶ
最大残余の幅が正と負の値で大きい場合、Smaller change (Ctrl + S) (?: Reduce change / Ctrl + R では?) を選ぶ
計算がうまく収束しない、目的に応じた収束結果が得られなかった場合、Finish iterating を選ぶ
(?) Query = Yes, Query = N → よくわからない(実際に試したが反応せず、iteration process で受け付けるのか?)
20. Files pull-down menu
Exit 終了
Finish iteration (Ctrl+F keys) 現在おこなっているiteration で終わらせ、フィット計算、結果報告に移す
Save progress report スクリーンでの出力をファイルに書き込む
Restart Facets 分析中のFacets から離れて、Facets ウィンドウをもう1つ起動させる
Facform Facform の起動(データファイル作成の支援ソフト)
Restart: facets (filename) specification file(データファイルを開くところ)からやり直す
Exit, then Restart: facets (filename) 分析中のFacetsを破棄してやり直す
21. Graphs pull-down menu(出力結果を曲線のグラフで描画して見たい時使える)
Category Probability Curves それぞれのロジットに対して特定のカテゴリ(パフォーマンステストでの段階分けされた得点など)それぞれが与えられる確率(複数の釣鐘状の曲線)
Expected Score ICC それぞれのロジットに対して予測されるスコア(1つのS字曲線)
Empirical ICC 各ロジット/カテゴリで与えた観測得点の平均
Cumulative Probabilities 特定のロジットで与えられるカテゴリの確率を総計(複数の逆S字曲線)
Empirical Randomness (?) plots the average observed standardized residual variance in each interval,
logarithmically scaled. Its expectation is 1.0
Information Function 項目(Person?)に関するFisher統計情報
(?)This is also the model variance of the responses, see RSA p. 100.
Category Information 観測されたカテゴリとその確率に従って、ある項目(Person?)がそのカテゴリに位置する確率情報
Conditional Probabilities 隣接したカテゴリ同士で期待されるロジット以上である確率
Smoothing 曲線効果
(長橋)
FACETマニュアル & 実習の記録
・大体29ページまで、実習を交えながら説明を行った。
・misfitやmissingに対して頑健性があることが重要であるという記述はポイント。
・メモリ容量が少なかったり、電源につないでいないと、スピードがかなり遅くなってしまうので注意。
・グラフをキレイに出す場合には、自動的に出るoutputではなく、グラフコマンドから出力する。
【今後に向けて】
・dummy facetの外し方を確認する必要がある。
・outputされる[Estim.Discrm]とは何を示すか?
・Edit from Templateについても確認したい
・次回は30ページから読む
(中川)
ページトップに戻る
第3回 5/11発表分
■section 22-28 (pp. 30-34) の操作については、マニュアルを読むより使ってみて体得するのが早い。前回の実習以降、疑問点はないものとして省略
■サンプルスクリプトの解読、書き方について
29. Two-facet dichotomy: The Knox Cube Test (p.35)
TITLE='Knox Cube Test (Best Test Design p.31)'セミコロン以下はコメントアウトの説明
Facets = 2 ; 2相Rモデル: children(P) and items(I)
Positive = 1 ; 1番目の相 children は得点(値)が高ければ能力も応じて高い値で表示
Noncenter = 1 ; 1番目の相 children について、必ずしも0を基準としない
Point-biserial = Yes ; 結果報告に点双列相関係数を使うかどうかのオプション
Vertical=1*,1A,2N,2A ; タテの仕切りで示しているもの。
children の能力値*, 男女別の配分, 項目(taps)の名義番号,とその説明
Yard=112,4 ; Rulers は 112 文字列の幅で出力, 1ロジットあたり 4 行(0.25幅で1行移動)
Model = ?,?,D ; 2値的応答として2相の相互作用からなる要素を分析する
Labels = ;ここから下はラベル付与(名義)
1,Children ; Children are facet 1 (Facet番号の定義:1番は子供たち(受験者))
1-17=Boy,,1 ; 下位カテゴリーとして、1番Facetの1~17番にはBoyのグループ名を
18-35=Girl,,2 ; 1番Facetの18~35番にはGirlのグループ名を付与する
* ; ここの*は1番Facetの終わりを示す
2,Tapping items ; 2番Facetとして項目名は Tapping item と定義する
1=1-4 ; イコールの左は項目番号、右は項目の名義
2=2-3
3=1-2-4
4=1-3-4
5=2-1-4
6=3-4-1
7=1-4-3-2
8=1-4-2-3
9=1-3-2-4
10=2-4-3-1
11=1-3-1-2-4
12=1-3-2-4-3
13=1-4-3-2-4
14=1-4-2-3-4-1
15=1-3-2-4-1-3
16=1-4-2-3-1-4
17=1-4-3-1-2-4
18=4-1-3-4-2-1-4
* ; 項目Facetの終わり
Data = ; データファイルには名前がなく、そのまま後の行で入力されてある
1 ,1 ,1 ; サンプル用に受験者1番の項目1番の応答だけ抜いて表示
1 ,2-18,1,1,1,1,1,1,0,0,0,0,0,0,0,0,0,0,0 ;受験者1番の応答残り(項目2~18)
2 ,1-18,1,1,1,1,1,1,0,0,1,1,1,0,0,1,0,0,0,0
3 ,1-18,1,1,1,1,1,1,1,1,1,0,1,0,0,0,0,0,0,0
4 ,1-18,1,1,1,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0
5 ,1-18,1,1,1,1,1,1,1,1,1,1,0,0,1,1,0,0,0,0
6 ,1-18,1,1,1,1,1,1,1,1,1,1,1,1,0,0,0,0,0,0
7 ,1-18,1,1,1,1,0,0,1,0,1,0,0,0,0,0,0,0,0,0
8 ,1-18,1,1,1,1,1,0,1,0,1,1,0,0,0,0,0,0,0,0
9 ,1-18,1,1,1,1,1,1,1,1,1,1,0,0,1,0,0,0,0,0
10,1-18,1,1,1,1,1,1,1,1,1,1,1,0,0,0,0,0,0,0
11,1-18,1,1,1,1,1,1,1,1,1,1,0,0,1,0,0,0,0,0
12,1-18,1,1,1,0,1,1,0,0,0,0,0,0,0,0,0,0,0,0
13,1-18,1,1,1,1,1,1,1,1,1,0,1,0,0,0,0,0,0,0
14,1-18,1,1,1,1,1,1,1,1,1,1,0,1,0,1,0,0,0,0
15,1-18,1,1,1,1,1,1,1,1,1,1,1,1,1,0,0,0,0,0
16,1-18,1,1,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
17,1-18,1,1,1,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0
18,1-18,1,1,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0,0
19,1-18,1,1,1,1,1,1,1,1,1,1,1,0,0,0,0,0,0,0
20,1-18,1,1,1,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0
21,1-18,1,1,1,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0
22,1-18,1,1,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0,0
23,1-18,1,1,1,1,0,0,1,0,0,1,0,0,0,0,0,0,0,0
24,1-18,1,1,1,1,1,0,0,1,1,1,1,1,0,0,0,0,0,0
25,1-18,1,1,1,0,1,1,1,1,1,0,0,0,0,0,0,0,0,0
26,1-18,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0,0,0,0
27,1-18,1,1,1,1,1,1,1,1,1,1,1,0,1,0,0,1,1,0
28,1-18,1,1,1,1,0,1,1,1,1,1,0,0,0,0,0,0,0,0
29,1-18,1,1,1,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0
30,1-18,1,1,1,1,1,1,1,1,1,1,1,1,1,0,1,0,0,0
31,1-18,1,1,1,1,1,1,1,1,1,1,1,0,1,0,0,0,0,0
32,1-18,1,1,1,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0
33,1-18,1,1,1,1,1,1,1,1,1,0,0,1,0,0,0,0,0,0
34,1-18,1,1,1,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0
35,1-18,1,1,1,1,1,1,1,1,1,1,1,0,0,0,0,0,0,0
; 受験者35番については項目1~11でスコア1を獲得し、12~18でスコアは0
・ ; データの終了

30. Two-facets with interactions: Knox Cube Test (p.37)
; kctinter.txt
TITLE='Knox Cube Test with interactions'
Facets = 4 ; 4相: 受験者, 項目, 受験者性別, 項目長さ を考慮する
Positive = 1 ; サンプル29と同じ(measure 高= 受験者能力 高)
Noncenter = 1 ; サンプル29と同じ(受験者能力は0を基準としない)
Model =
?,?,? ,? ,D ; 2値的応答として4相の相互作用からなる要素を分析する
?,?,?B,?B,D ; 3番(gender),4番(item length) Facetからの相互作用を誤差比較する
*
Labels =
1, Children ; サンプル29と同じ
1-17 = 1 Boy,,1
18-35 = 2 Girl,,2
*
2,Tapping items ; サンプル29と同じ
1 = 2 1-4
2 = 2 2-3
3 = 3 1-2-4
4 = 3 1-3-4
5 = 3 2-1-4
6 = 3 3-4-1
7 = 4 1-4-3-2
8 = 4 1-4-2-3
9 = 4 1-3-2-4
10 = 4 2-4-3-1
11 = 5 1-3-1-2-4
12 = 5 1-3-2-4-3
13 = 5 1-4-3-2-4
14 = 6 1-4-2-3-4-1
15 = 6 1-3-2-4-1-3
16 = 6 1-4-2-3-1-4
17 = 6 1-4-3-1-2-4
18 = 7-1-3-4-2-1-4
*
3 = Gender, A ; 性別はダミーFacetとして、相互作用でのみ用いる
1 = Boy, 0 ; サンプル29と同じだが、要素は0同士でリンクしている(anchored)と考える
2 = Girl, 0
*
4 = Number of Taps, A ; 3番Facetと同じくダミーFacet。項目のパターンを示す。
2 = 2 taps, 0 ;(?)Tap 数 (item length) の後に , 0 と入力するのはなぜか
3 = 3 taps, 0
4 = 4 taps, 0
5 = 5 taps, 0
6 = 6 taps, 0
7 = 7 taps, 0
* ; 3番、4番Facets の終わり
; (?)ダミーFacetsとは、Model でBias Pairwise Report を求めつつ、
Facet 内部の下位グループでリンクさせた相のことをいうのか?
Dvalues = ; 性別とTap 数は名義の中に示してあるので、データから省略可
4, 2, 1, 1 ; 項目長さを示す4番Facetは、2番Facet の中で1列目に1桁で
3, 1, 1, 1 ; 性別を示す3番Facetは、1番Facetの中で1列目に1桁で
*
; 今回のデータ
; 1番Facetsは要素の数
; 2番Facetは要素(範囲)
; 3番Facetはデータに含まないDvaluesから得られた値/名義
; 4番Facetはデータに含まないDvaluesから得られた値/名義
; 観測 (当てはまる範囲内で)
Data =
1 ,1 ,1 ; child 1 on item 1 scored 1: Facet elements for facets 3 and 4 provided in Dvalues=
1 ,2-18,1,1,1,1,1,1,0,0,0,0,0,0,0,0,0,0,0
: : :
(サンプル29と同じなので、途中省略)
: : :
35,1-18,1,1,1,1,1,1,1,1,1,1,1,0,0,0,0,0,0,0
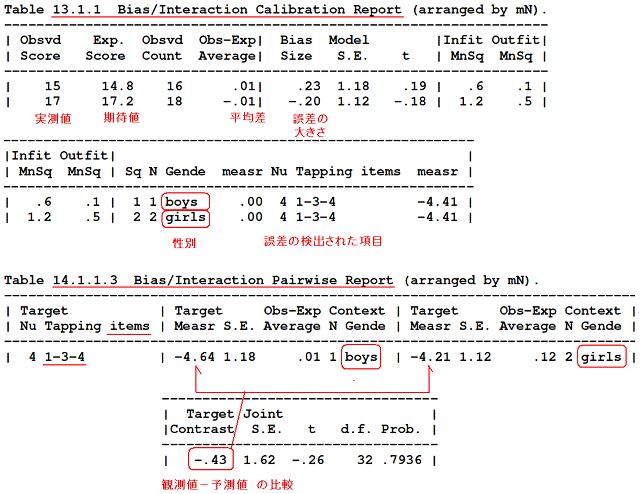
■このようにすれば、interaction Tableが作れて、「性別」と「項目の長さ」による相対的なパフォーマンスの差を調べられる。
(長橋)
FACETマニュアル&実習の記録
・ Modelのところで「?」になっている部分をFACETで算出するのではないかという議論を行った。
・ セクション29の
1 ,1 ,1 ; サンプル用に受験者1番の項目1番の応答だけ抜いて表示
1 ,2-18,1,1,1,1,1,1,0,0,0,0,0,0,0,0,0,0,0 ;受験者1番の応答残り(項目2~18)
では、データが説明のために1番だけサンプルとなっていて、他のデータと異なる表記だったため、かえってわかりにくかったが、その範囲をきちんと指定さえすれば、このように2行に分けてデータを表記しても読み取ってくれるようだ。通常であれば、この2行を1行で以下のように表記するのだろう。
1 ,1-18,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0,0,0,0 ;受験者1番の応答(項目1~18)
・ セクション30で、Dvaluesの部分において、「1列目に1桁で」と書かれているが、2桁使用したい場合は、「何列目」と定義すればよいのだろうか。また、この場合の1列目、というのはスペースで区切ることで1列としているのか、今後のサンプルデータで探ることにする。
・ また、第2ファセットである 2,Tapping items の部分で、項目18のラベル付けが間違っているようだったため、そのままのラベルのものと、ラベル付けを直したり、tappingを6つと定義したデータで実際に分析を行ってみたが、分析結果は変わらず、名前だけが変更した表示となった。従って、ここはあくまでもラベル付け(名前)であって、まちがったラベルにするとそのままoutputファイルに表示される。分析結果は、Dvaluesのデータ部分で分析定義しているようだ。
【今後に向けて】
・ Tap数の後に0と入力するのは何故なのかを知る必要がある。
・ Dvaluesの部分の定義がどのようになっているのかを知りたい。
・ 次回はセクション31から行う。
(森本、平井)
ページトップに戻る
第4回 5/18発表分
31. Three-facet dichotomy: The Knox Cube Test with Item Bias analysis (p.38)
■標準的な2相分析では、性別ごとの応答が表示されたが DIF (differential item functioning = 差異項目機能) は計算されなかった。ここでは性別に関してダミーFacetを設け、DIFの発見をしてみる。
; kcta.txt
Title = Knox Cube Test (Best Test Design p.31) ; the report heading line
Facets = 3 ; 相の数は3つ: 受験者、項目、性別
Positive = 1 ; サンプル29、30と同じ
Noncenter = 1 ; サンプル29、30と同じ
Point-biserial = Yes ; report the point-biserial correlation
Vertical = 1*,1A,2N,2A ;受験者は能力と性別で、タスクは番号と名前でタテのRulerに表示
Yard = 112,4 ; Rulerの幅(文字列数, Logitの目盛り幅
Model = ?,?B,?B,D ;2番、3番Facetによる誤差/相互作用がないか調べる
1,Children ; Children are facet 1
1-17 = Boy,,1 ; Pretend boys, in group 1, are numbered 1 through 17.
18-35 = Girl,,2 ; Pretend girls, in group 2, are numbered 18 through 35.
* ; end of child labels for facet 1
2,Tapping items ; Items are facet 2
1 = 1-4 ; Items labelled by the order in which the four blocks are tapped
2 = 2-3
3 = 1-2-4
4 = 1-3-4
5 = 2-1-4
6 = 3-4-1
7 = 1-4-3-2
8 = 1-4-2-3
9 = 1-3-2-4
10= 2-4-3-1
11= 1-3-1-2-4
12= 1-3-2-4-3
13= 1-4-3-2-4
14= 1-4-2-3-4-1
15= 1-3-2-4-1-3
16= 1-4-2-3-1-4
17= 1-4-3-1-2-4
18= 4-1-3-4-2-1-4
*
3,Gender,A ; Dummy gender facet is anchored(サンプル30と同じ)
1=boys,0 ; anchor at 0 so do not affect analysis
2=girls,0 ; anchor at 0 so do not affect analysis
*
Data = ; no data file name, so data follows immediately in this file
1,1,1,1 ; child 1 on item 1 a boy scored 1
1 ,2-18,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0,0,0,0
2 ,1-18,1,1,1,1,1,1,1,0,0,1,1,1,0,0,1,0,0,0,0
3 ,1-18,1,1,1,1,1,1,1,1,1,1,0,1,0,0,0,0,0,0,0
4 ,1-18,1,1,1,1,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0
5 ,1-18,1,1,1,1,1,1,1,1,1,1,1,0,0,1,1,0,0,0,0
6 ,1-18,1,1,1,1,1,1,1,1,1,1,1,1,1,0,0,0,0,0,0
7 ,1-18,1,1,1,1,1,0,0,1,0,1,0,0,0,0,0,0,0,0,0
8 ,1-18,1,1,1,1,1,1,0,1,0,1,1,0,0,0,0,0,0,0,0
9 ,1-18,1,1,1,1,1,1,1,1,1,1,1,0,0,1,0,0,0,0,0
10,1-18,1,1,1,1,1,1,1,1,1,1,1,1,0,0,0,0,0,0,0
11,1-18,1,1,1,1,1,1,1,1,1,1,1,0,0,1,0,0,0,0,0
12,1-18,1,1,1,1,0,1,1,0,0,0,0,0,0,0,0,0,0,0,0
13,1-18,1,1,1,1,1,1,1,1,1,1,0,1,0,0,0,0,0,0,0
14,1-18,1,1,1,1,1,1,1,1,1,1,1,0,1,0,1,0,0,0,0
15,1-18,1,1,1,1,1,1,1,1,1,1,1,1,1,1,0,0,0,0,0
16,1-18,1,1,1,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
17,1-18,1,1,1,1,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0
18,1-18,2,1,1,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0,0
19,1-18,2,1,1,1,1,1,1,1,1,1,1,1,0,0,0,0,0,0,0
20,1-18,2,1,1,1,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0
21,1-18,2,1,1,1,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0
22,1-18,2,1,1,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0,0
23,1-18,2,1,1,1,1,0,0,1,0,0,1,0,0,0,0,0,0,0,0
24,1-18,2,1,1,1,1,1,0,0,1,1,1,1,1,0,0,0,0,0,0
25,1-18,2,1,1,1,0,1,1,1,1,1,0,0,0,0,0,0,0,0,0
26,1-18,2,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0,0,0,0
27,1-18,2,1,1,1,1,1,1,1,1,1,1,1,0,1,0,0,1,1,0
28,1-18,2,1,1,1,1,0,1,1,1,1,1,0,0,0,0,0,0,0,0
29,1-18,2,1,1,1,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0
30,1-18,2,1,1,1,1,1,1,1,1,1,1,1,1,1,0,1,0,0,0
31,1-18,2,1,1,1,1,1,1,1,1,1,1,1,0,1,0,0,0,0,0
32,1-18,2,1,1,1,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0
33,1-18,2,1,1,1,1,1,1,1,1,1,0,0,1,0,0,0,0,0,0
34,1-18,2,1,1,1,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0
35,1-18,2,1,1,1,1,1,1,1,1,1,1,1,0,0,0,0,0,0,0
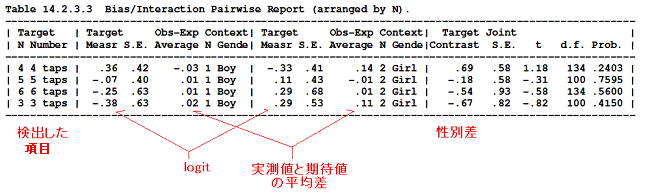
■DIFレポートが以下のとおり
■DIFレポートからは、全体の項目困難度から反する結果が、性別により項目4で見られる。
t 検定で平均比較を見ることができ t (32) = -.26, p = .794 で、統計的有意差はない。
32. Two-facet rating scale: Liking for Science (p.40)
■子供たちの科学に関する活動態度について、0=嫌い、1=わからない、2=好き のリカート法使用
Title = Liking For Science (Rating Scale Analysis p.18) ; the report heading line
Arrange = F,m ; table の出力はFit値を昇順、Logit を降順に並べて表示
Facets = 2 ; 相の数は2つ: 回答者 (children)と アンケート項目 (science items)
Pt-biserial = Y
Positive = 1 ; 高いLogit の回答者ほど得点は高い
Noncenter = 1 ; 回答者の基準値は流れるが、2番facetの項目が0を基準に固定されている
Usort=U ; 予想外の残差を昇順で並べて表示
Vertical=2A,1* ; Rulerは2番Facetの名前, 1番facetを得点に応じ*で表示
Yardstick=0,5 ; タテ表示のRulers: 0 は横幅をFacetsが必要なだけとれる
; 1Logitあたり5行(0.2 logitで1行)
Model = ?,?,faces ; 回答者は faces(顔マークで表したスケール?)から項目採点。その相互作用を調べる
Rating scale = faces,R2 ; faces の定義。R2 は0~2点の rating scale を示す
0 = dislike ; 得点カテゴリーの名義付け。0は「嫌い」、1は「わからない」、2は「好き」
1 = don't know
2 = like
* ; end of scale definition for "faces"
Labels =
2,Activity ; 2番facetは便宜上、はじめに知らせておく
1 =Watch birds ; ここからが、各項目の名義
2 =Read about animals
3 =Read about plants
4 =Watch grass change
5 =Find cans
6 =Encyclopedia
7 =Watch same animal
8 =Look in cracks
9 =Name weeds
10=Listen bird sing
11=Animal lives where
12=Go museum
13=Grow garden
14=Pictures of plants
15=Animal stories
16=Make map
17=Watch animals eat
18=Go picnic
19=Go zoo
20=Watch bugs
21=Watch bird nest
22=Animals eat what ?
23=Watch rat
24=Flowers live on ?
25=Talk about plants
* ; end of items
1,Child
1-75 = ; 回答者の children は75名(名義など、その他の情報なし)
* ; end of child labels
data= ;回答状況(回答者番号, 項目1~25番までを指定, 回答者の付けた得点25個分)
1,1-25,1,2,1,1,1,0,2,0,1,2,2,2,2,0,2,1,1,2,2,0,2,1,0,2,0
2,1-25,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2
3,1-25,2,2,1,1,0,1,1,0,1,2,2,2,2,1,2,2,1,2,2,1,2,1,1,1,1
: : :
(長いので最初と最後の3人だけ)
: : :
73,1-25,2,0,1,2,0,1,0,1,2,2,2,1,0,2,0,1,1,0,2,2,0,2,0,2,2
74,1-25,2,2,2,0,0,2,2,0,0,2,2,2,2,2,2,2,2,2,2,0,2,2,0,1,2
75,1-25,1,2,0,0,1,1,0,1,1,2,1,2,2,2,2,1,0,2,2,0,2,0,0,1,0
・
■マニュアルで data = 以降の記述法を、もうひとつ。
Dvalues = 2, 1-25 ; ここから各行2番目以降は項目1-25 のdata facet
1, 1,2,1,1,1,0,2,0,1,2,2,2,2,0,2,1,1,2,2,0,2,1,0,2,0
; 回答者1番は項目1を1点、項目2を2点と採点…
|
75, 1,2,0,0,1,1,0,1,1,2,1,2,2,2,2,1,0,2,2,0,2,0,0,1,0
33. Three-facet rating scale: Creativity (with Excel input data file) (p.40)
■Guilford (1954)は、先輩の科学者3人が7人の後輩について独創力を5つの特性で採点させ、その評価の実態を研究した。採点は1~9点の幅で、9点が最も独創的とした。
Title = Ratings of Scientists (Psychometric Methods p.282 Guilford 1954)
Score file = GUILFSC ; score files GUILFSC.1.txt, SC.2.txt and SC.3.txt produced
採点データを別ファイルに格納したケースのサンプル
Facets = 3 ; Facetの数は3つ: 評価者、受験者、項目
Inter-rater = 1 ;1番Facetが評価者
Arrange = m,2N,0f ; Logit を降順に全ての相を整列
; 2N = 2番Facetを番号で降順で並べる
; 0f = Biasレポート(Facet 0)はZ-scoreを降順に並べる
Positive = 2 ;スコア高 = 受験者の独創力が高い
Non-centered = 1 ;受験者と項目は0を中心とするが、評価者の基準値はない
Unexpected = 2 ;絶対値2以上の標準残差は報告する
Usort = (1,2,3),(3,1,2),(Z,3)
;予想外の採点結果は、複数場面(評価者、受験者、基準)で分けて報告(後の出力結果で確認)
Vertical = 2N,3A,2*,1L,1A ;Rulerの定義
(受験者番号,評価基準-名義,受験者位置*,評価者(名義と左の1Lはなに?)
Zscore = 1,2 ;1Logit より大きな誤差、2以上のZ-scoreは報告
Model = ?B,?B,?,Creativity ;評価者、受験者、項目が関わる「独創力」の採点
;誤差/相互作用の分析は、1番Facetの評価者,2番Facetの受験者より調べる
; log(Pnijk/Pnijk-1) Bn - Di - Cj - Fk
; Bn = ability n, Di = difficulty i, Cj = Severity j, Fk = Challenge k,
; Pnijk = probability that child n on item i is rated by judge j with score of k.
Rating scale = Creativity,R9 ;0 to 9独創力の採点幅は0~9点
1 = lowest ;観測得点では最低値であることを名義付け
5 = middle ; no need to list unnamed categories(?)
9 = highest ; 最高値
*
Labels= ;要因の名義
1,Senior scientists ;1番Facetの名前(評価者)
1=Avogadro ;評価者の名前(必須)。名義がないとmissing 扱いとなる
2=Brahe
3=Cavendish
*
2,Junior Scientists ;2番Facetの名前(評価される側の後輩)
2=Betty
5=Edward
7=George
1=Anne
3=Chris
4=David
6=Fred
*
3,Traits ;3番Facetの名前(「独創力」について分析的評価項目)
1=Attack
2=Basis
3=Clarity
4=Daring
5=Enthusiasm
*
Data= creativity.xls ; Facets can read in an Excel data file
; 今回は本txtファイル外のExcelファイルからDataを呼び出せる
; or ;従来どおり data = の直接貼り付けや、別ファイルから dvalue = を呼び出すことも可
; dvalues = 3, 1-5
; data = guilford.xls
操作実習の出力結果(一部)
Ruler

Usort (以下の4パターンの組み合わせは、予想外と報告されたことを意味する)

<議事録>
※初回で討議されたdummy facetの設定について、具体的に示されている例があった。
3,Gender,A ; Dummy gender facet is anchored (サンプル30と同じ)
1=boys,0 ; anchor at 0 so do not affect analysis
2=girls,0 ; anchor at 0 so do not affect analysis
上記のようにカンマのあとにゼロを記入する事によってdummyとして認識され、分析対象とならない。
※31において男女の差の検定に使用されている t 検定は、一般的な t 検定(平均比較)と異なり、SE (standard error) の値を使用している。実際にDIFレポートにあるModel S.E.の値を用い計算したところ、同様の結果が得られた。
※コマンドの Non-centered = 1 としても、Noncenter = 1 としても同じになった。
(中川)
ページトップに戻る
第5回 6/1発表分
34. Three facet the judge pairs: Language test
■この言語テストでは、受験者はランダムに与えられた文章を読み上げる。2回のテストで移動をはさみ、それぞれ評価者がひとりづつ全体評価(1-5点)で採点する。
以下の青文字は、以前にもよく書かれたコメントアウトの復習、及び誤訳/誤解防止のためマニュアルの原文から
Title = Paired-judge Reading Test ; the report heading line
Facets = 4 ; 受験者,テキスト,評価者,時間
Converge = .5, .1 ; 得点残差は最大 .5 まで,変動は最大で .1 ロジットまでの収束条件で計算
Positive = 1, 3 ; 能力の高い受験者,評価の緩い採点者ほどロジットは高い
Noncenter = 1 ; 受験者分布は0を基準にせず、テキスト・採点者によって相対的に流れる
Umean = 50, 5 ; ユーザーに分かりやすい値に目盛り幅を変更する: 50 + 5 x logit
Arrange = F,m ; table出力は Fit値を昇順,logit(Measure)を降順に整列
Usort = U ; unexpectedness で残差の分類をする
Vertical = 1A, 3A, 2A ; Ruler表示は、1~3番Facetを名前で表示
Model =
?,?,?,?,reading ; basic model: raters share the 5-point rating scale
; 基本モデル:評価者は5点法で採点(ここには書いてない→ Rating scale 参照)
?,?B,?,?B,reading ; 2番Facet(テキスト)と4番Facet(時間)の相互作用を誤差分析
*
Rating scale = reading,R9,K ; 5 category scale, keep intermediate unobserved categories
;つまり5点幅で採点,中間の得点は設定しない
1 = incoherent ; sounding out the words, or worse
5 = fluent ; as a native speaker
*
Labels= ; 受験者,テキスト,評価者名
1, Examinees
12, Stan
14, Amanda ; 途中は省略
:
*
2, Passages
1, Buchan
2, Sapper ; 途中は省略
:
*
3, Judges
1, Glass
2, Draper ; 途中は省略
:
*
4, Order, A ; 相互作用をみる場合でだけ使用するため。平均は共に50で固定(?)ディスカッション&コメント参照
these are anchored at umean=50 because for interactions only
1, First, 50
2, Second, 50
*
data=
12,1,1,1, 2 ; Stan reads Buchan to Glass first, and is rated 2
12,3,5,2, 3 ; Stan reads Fleming to Chase second, and is rated 3
14,6,4,1, 1
:
99,2,1,2, 5
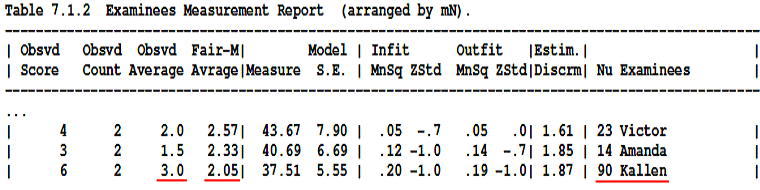
■Table 7でのレポートは標準化される。
Kallenは実測の得点が高いが、簡単な文章、緩い採点者のために、期待される得点は低くなる
Obsvd Scoreは評価者(2人)が採点した合計点、Obsvd Averageは評価者2人の平均点
35. Four facet rating scale with bias analysis: Essays
■Advanced Placement Program で実際にBraun (1988) がおこなったエッセイ採点についての研究データ。
4相は ①受験者,②トピック,③読み手,④採点セッション で、トピックと読み手による相互作用、
及び採点セッションをダミーFacet(0でエレメントを固定)で投入して誤差分析する。
; this is file essays.txt
title = AP English Essays (College Board/ETS)
convergence = 0.1 ; 収束の際、周縁得点残差は最大でも 0.1 まで計算を続ける
unexpected = 3.0 ; 標準残差が最少でも左記の値なら報告
arrange = M ; Table はLogit の昇順で整列
facets = 4 ; there are 4 facets in this analysis
noncenter = 1 ; examinee facet floats
positive = 1 ; for examinees, greater score greater measure
Inter-rater = 3 ; 3番Facetは評価者
usort = 2,3,1 ; 残差を 2,3,1番Facetの順に分けて出力
Model=
?,?B,?B,?,R9 ; 観測値は1-9までの採点結果
; 評価者とエッセイタイプ間での相互作用/誤差がないか検索
?,?,?B,?B,R9 ; 評価者と採点セッションとの相互作用がないか検索
*
Labels=
1,examinee
1-32 ; 匿名の受験者32名
*
2,Essay
1,A
2,B
3,C
*
3,Reader
1-12 ; 匿名の採点者12 名
*
4,Session,A ; this is a dummy facet, used only for investigating interactions
11,day 1 time 1 ,0 ; 8 sessions - all anchored at 0(8セッションは全て0で固定)
12,day 1 time 2 ,0
21,day 2 time 1 ,0
22,day 2 time 2 ,0
31,day 3 time 1 ,0
32,day 3 time 2 ,0
41,day 4 time 1 ,0
42,day 4 time 2 ,0
*
data =
05,1,1,11,4 ; ①受験者 5番, ②作文タイプ 1, ③採点者 1,(D)セッション 11, ④採点結果 4点
| ; 長いので省略(サンプルファイル参照)
09,1,1,11,3 ; rating最後列
(長橋)
ディスカッション&コメント
・ 34の部分で、5件法で評価するとは明記されていないが、おそらくRating Scaleのところに1と5の定義が書いてあるため、その部分で指定していることになるのではないか。
・ 34の部分で、第4FACETであるorderはdummy FACET。今までは、dummy FACETは0と表記することでdummyということを表していたが、今回はUMEANを50と指定しているために、50と表記しているのだと考えられる。
(森本)
ページトップに戻る
第6回 6/22発表分
36. Five-facet rating scale
with bias analysis: Essays+Days
■section 35に続いてETSのEssay Dataセットを用い、採点日時との相互作用がないか調べる。4番Facetで既に定義されているので、Dvalues によって実行可能。(対象のファイルはessayday.txt)
title = AP English Essays (College Board/ETS)
facets = 5 ;今回の分析では相が5つ
Model=
?,?B,?B,?,?, R9 ;定義された5相による相互作用の分析(?マーク)と、
; エッセイ課題(2番Facet)と評価者(3番Facet)における誤差分析を目的としたモデル(マニュアルの誤植に注意!)
*
Dvalues= ;5番Facetがどこにあるか定義
5, 4, 5, 1 ;日時:観測された5番Facetは、4番Facetの中で文字列の5番目に1桁で表記してある
(?)下の4番Facetで赤字の値らしいのだが、どう数えれば5番目なのだろう
*
noncenter = 1 ; examinee facet floats
; 常に受験者が0を基準としないのは、テストや評価者は繰り返し採用されることがあっても、
; 参加者は入れ替わることが多いためと思われる
→ 後々、複数のテスト・実験を通じて前者(テスト・評価者)を固定した比較が可能
positive = 1 ; for examinees, greater score greater measure
inter-rater = 3 ; facet 3 is the rater facet
usort = 2,3,1 ; sort residuals by 2=Essay, 3=Reader, 1=Examinee
; 残差をUnexpected Responses のTable で報告。その場合、相は左から上記の順に整列 (cf. sec 33)
convergence = 0.1 ; size of largest remaining marginal score residual at convergence
; (?)多くても周縁得点残差が0.1までは収束を繰り返して計算
unexpected = 3.0 ; 標準残差が3.0以上の場合は報告する
arrange = M ; 出力結果の Table はlogit(M) を昇順に整列して表示
→ 大文字は昇順,小文字は降順らしい
Labels=
1,examinee
1-32 ; 32 otherwise anonymous examinees
*
2,Essay
1,A ; 3 essays
2,B
3,C
*
3,Reader
1-12 ; 12 otherwise anonymous readers
*
4,Session,A ; section 35と同様にダミーFacetなので、右端の文字列は値=0で固定してある
11,day 1 time 1 ,0 ; 採点セッションの数は8つ all anchored at 0
12,day 1 time 2 ,0
21,day 2 time 1 ,0
22,day 2 time 2 ,0
31,day 3 time 1 ,0
32,day 3 time 2 ,0
41,day 4 time 1 ,0
42,day 4 time 2 ,0
*
5, Day, A ; 5番Facet:相互作用がないか調べるために設定したダミーFacet
1, Day one, 0 ; Dvalues= obtains these from Facet 4.
2, Day two, 0
3, Day three, 0
4, Day four, 0
*
data =
05,1,1,11,4 ; 先頭の観測された採点結果:受験者番号5は作文課題1が与えられ、
評価者1が1日目の1時限目に採点した。結果、評点は4。
01,1,1,11,5
13,1,1,11,4
09,1,1,11,3 ; マニュアルではlast ratingだが、実は4行目の観測
: :: :: (以下1152行までのあらゆる組み合わせが続く:32x3x12)
13,3,12,42,9
19,3,12,42,8
24,3,12,42,3
11,3,12,42,4 ; example\essayday.txt内のlast rating4つ
■分析の観点となる主な出力結果
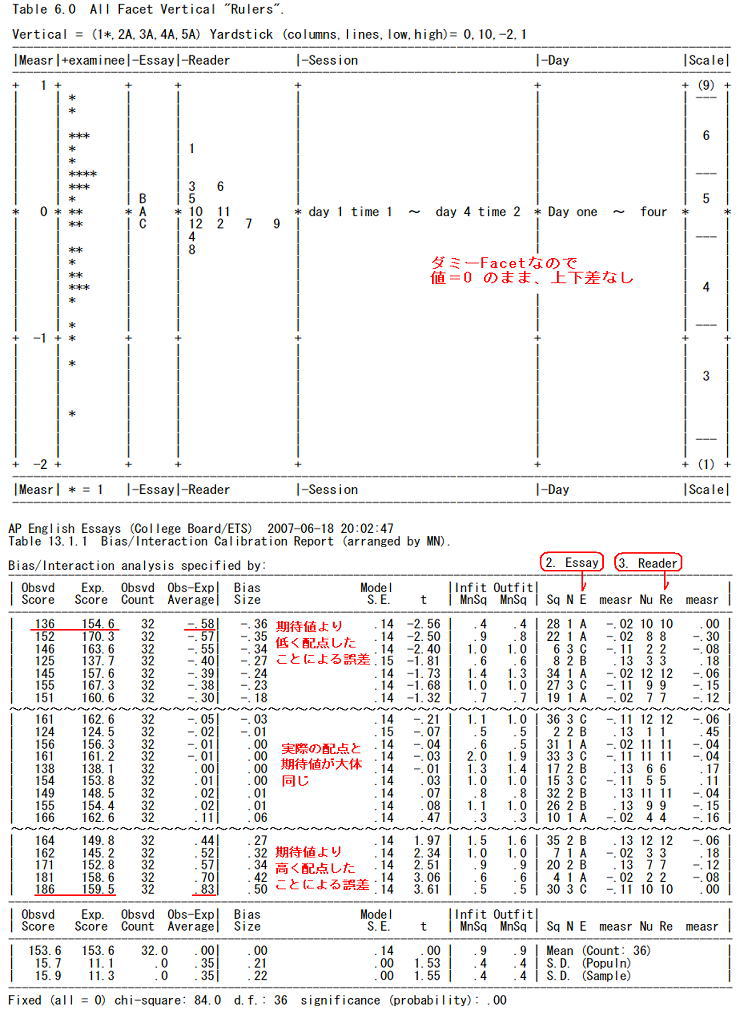
AP English Essays (College Board/ETS) 2007-06-18 20:02:47
Table 14.1.1.2 Bias/Interaction Pairwise Report (arranged by MN).
Bias/Interaction analysis specified by: 2. Essay, 3. Reader
AP English Essays (College Board/ETS) 2007-06-18 20:02:47
Table 14.1.1.3 Bias/Interaction Pairwise Report (arranged by MN).
Bias/Interaction analysis specified by: 2. Essay, 3. Reader
■あまりに長いので、当日にExcelファイルを配布、参照してもらった
(長橋)
ディスカッション&コメント
・dummy facetにすると、固定値になるためbias分析は行えない。
・FACETSではスペースを読まないため、今回の4番FACET、5番FACETにおけるDVALUEの読み方がよく分からなかった。
・Bias分析において、全部で198行になっていたのは、raterの組み合わせ(12×11/2)×essayの数(3)で、198になっていたため。従ってinteractionを見ている(Table 14.1.1.2)。
(森本)
ページトップに戻る
第7回 7/13発表分
37. Four-facet rating scale with missing data: Diving
■12人のダイバーが3回の演技をおこない、7人のジャッジによって採点される。ダイバーは全ての演技で競うわけではなく演技のタイプを選ぶので、データ上はほとんどがmissing(欠損)データとなる。採点は0.5点刻みで0~10点までを2倍にして整数で表示する。
前分析をおこなっており、どのくらいを好成績とするかが予めわかっている。演技に失敗したり、まぐれ (lucky guesses)等で明らかに異常な高配点が観測された場合、意図的に欠損値として扱った。これは過去のデータからパフォーマンス判定の説明力を補強する目的であり、将来的な予測を目的とした分析(例. 受験者の期待されるパフォーマンス、項目銀行のための項目困難度調査 等)ではこのような作業は行なわない。
DIVES.txt
Title = 1988 Illinois Boys Diving Competition (Anne Wendt)
Facets = 4 ; facet4つ(選手(ダイバー),飛び込み演技,ラウンド,採点官)
Inter-rater = 4 ; 4番facetが評価者
Noncenter = 1 ; 選手は0を基準としない(流れる)
Positive = 1 ; 1番facetはlogitが高いほど高得点者であることを示す
Models = ; these models will be scanned in order until a match is found for each datum:
7,8,?,?,M ; 7番の選手は8の演技をmissingで処理 - 不正の飛び込み演技をした
?,?,X,?,DoublePoints ; 3番facet(ラウンド)はXマークにより分析から排除(p.66参照)
*
Rating scale = DoublePoints,R20,Keep ; Keep unobserved intermediate categories
; (?)分析で観測できない0.5刻みでの中間得点を残すため、得点20は倍掛けであることを定義
0 = 0.0
10 = 5.0 ; 5.0は素点
20 = 10.0
*
Labels=
1,Diver
;前回の選手の得点が参考に付け加えられている
1=Marty Turek 292.85 425.65 , 2.08 ; 選手のlogit初期値がカンマの後に示されている(2.08)
| ; 10 other divers
12=Bryan Hanania 251.15 ,-1.19
*
2,Dives
; 各飛び込み演技で公式に難易度の重み付けがされている
; 例)イコールの後についている1.4とは飛び込み演技の名前
1=1.4, -0.60 ; カンマの後についている -0.60はlogitの初期値
| ; 他に演技が6種類
8=2.6, 0.99
9=2.4? ; どんな演技か不明の場合
*
3,Round
1-3 ; ラウンドは3回おこなわれる
*
4,Judges
1-7 ; 採点官は7名
*
Data =
1,8,1,1,14 ; 選手1(Marty)は演技8(2.6)を1ラウンドにおこない、採点官1が14点を配した
; ここでの14点とは、事実上は素点7点を倍掛けしたもの
| ; あと136例の採点結果(応答)が入力されている
12,2,3,7,11 ; 最後の応答
;選手12(Bryan)は演技1.7をラウンド3でおこない、採点官7が5.5の素点を配した(処理上は11点)
■exampleファイルの中身を調べると、こうなっている
Data=
1,8,1,1,14
1,8,1,2-4,11,12,12
1,1,2,1-7,16,13,13,16,14,13,14
2,8,2,1-7,12,12,10,11,10,11,13
3,1,1,1-4,10,11,10,11
3,6,2,1-7,11,10,09,08,09,09,11
4,3,1,1-7,12,13,13,13,10,12,12
4,7,2,1-7,12,12,09,11,11,11,12
5,3,1,1-7,10,09,09,09,09,08,10
5,6,2,1-7,07,08,08,08,06,06,07
6,3,1,1-7,11,10,10,11,09,10,09
6,5,2,1-7,13,12,12,12,12,13,14
7,3,1,1-7,13,12,12,12,14,14,12
7,6,2,1-7,14,11,11,12,12,12,14
8,1,1,1-7,11,11,12,12,11,12,12
8,4,2,1-7,13,13,13,14,13,14,15
9,1,1,1-7,12,13,13,13,12,12,13
9,5,2,1-7,12,11,11,11,12,12,13
10,1,1,1-7,12,11,12,12,10,12,13
10,8,2,1-7,08,06,08,09,07,07,06
11,3,1,1-7,08,06,08,07,07,07,08
11,7,2,1-7,10,10,10,09,10,10,11
12,3,1,1-7,08,07,08,07,07,06,09
12,6,2,1-6,09,09,08,08,08,08
1,8,3,1-7,13,12,13,12,13,12,14
2,8,3,1-7,13,14,11,11,12,12,14
3,8,3,1-7,07,07,11,08,09,08,10
4,8,3,1-7,12,10,12,12,12,11,12
5,7,3,1-7,07,08,08,06,06,06,06
6,4,3,1-7,09,10,10,09,09,10,10
; these next observations are made missing - wrong dive!
7,8,3,1-7,00,00,00,00,00,00,00
8,6,3,1-7,12,13,10,13,11,12,09
9,5,3,1-7,08,09,09,08,10,09,10
10,5,3,1-7,13,13,10,13,10,11,11
11,5,3,1-7,11,12,10,09,08,09,11
12,2,3,1-6,10,10,10,11,10,11
12,2,3,7,11
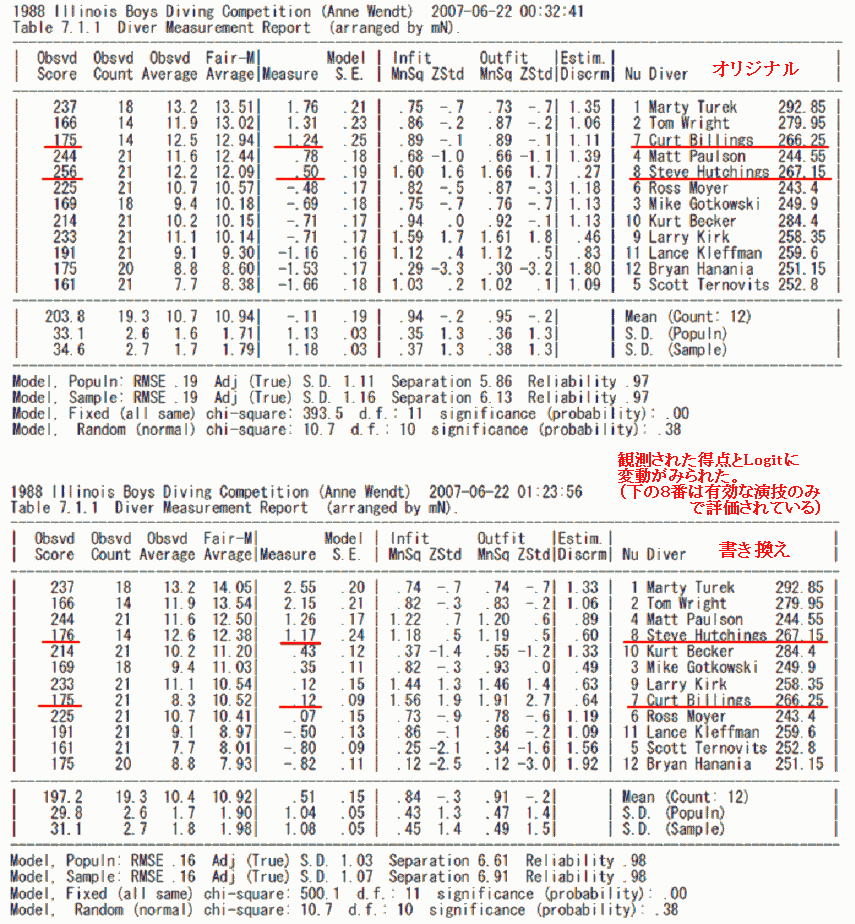
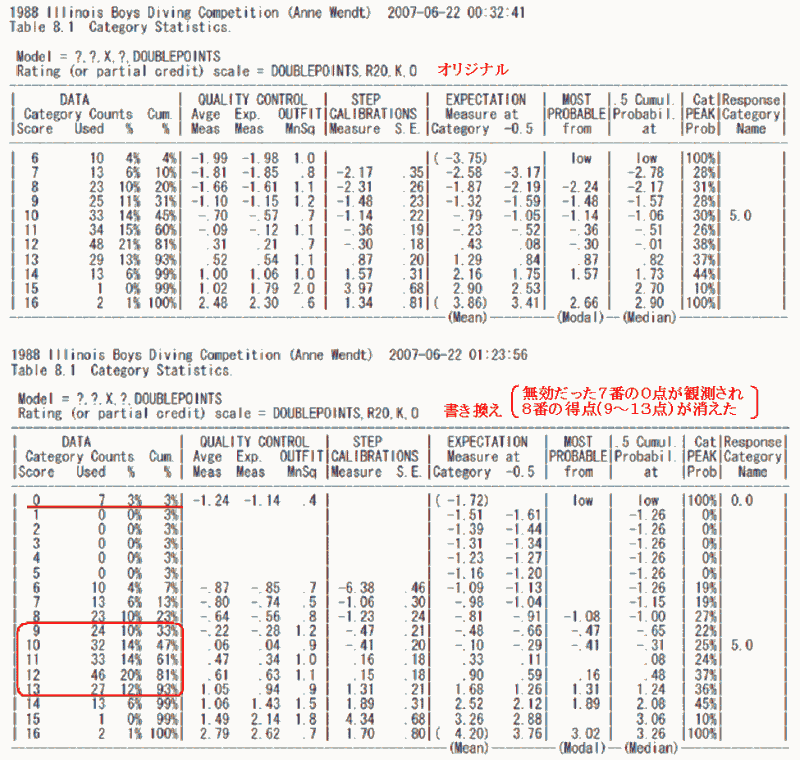
■モデルを以下のように操作して再分析してみた
Models = 7,8,?,?,M ?,?,X,?,DoublePoints → Models = 8,6,?,?,M ?,?,X,?,DoublePoints
"Data =" の中に入力されている下線部分が 有効/無効 データとして処理される。今回はオリジナル(7番の選手の3番目の演技を無効とするモデル)と、書き換えた後(代わりに8番の選手の3番目の演技を無効としたモデル)とで、出力結果の比較をおこなった(Rulerはこちら)。
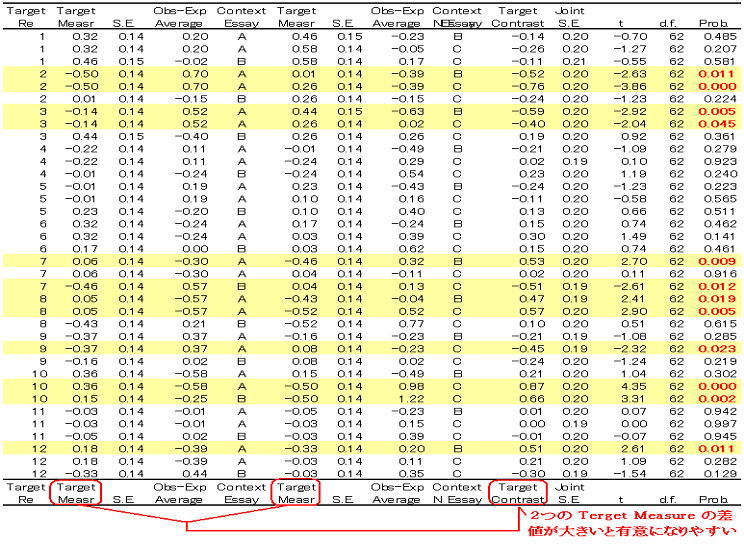
39. Two-facet partial credit/rank order: Sportscasting (p.46)
■7名のスポーツキャスターを6観点のパフォーマンスから格付けしたデータ。Polskin (1988) Chapter 12で多相ラッシュモデルによる考察が見られる。順序変数の分析を満たす手法としては、各順位付けを1つのテスト項目として扱い、順位配列の番号をその項目での部分的信頼度 ((?)partial credit grades) として扱う。
; sportcas.txt
Title = Rank orderings of Sportscasters (TV Guide, July 30 1988)
facets = 2 ; Facetは2つ: (1)「スポーツキャスター」と(2)「ランク」項目
arrange = 1m,N ; Table表示の際、1番Facetはlogitを降順で整列
全Facets について名義番号を昇順で表示
positive = 0 ; いずれの facet も値が少ないほどランク上位であることを意味する
noncenter = 2 ; スポーツキャスターは0を基準にとるが、ランクはとらない
unexpected = 2 ; 標準残差が絶対値の2を超える値は報告する
model=?,#,R7 ; 1番Facetのスポーツキャスターは従来のelementと同じ分析方法でモデル化
;2番Facetのランキングが今回問題となっているpartial credit モデル(それぞれに独立した尺度)
■今回のモデルで、はじめて#マークが出てきた (p.66参照)
→モデルが対象のFacetの中であらゆる要因にデータを合わせる点では、?マークによる分析と同じ。
更に#マークでは、モデルに組み込まれた各要因が独自の採点尺度を持っており、その適合度も調べる。
labels =
1,Sportscasters ; 1番Facet
1=Vin Scully ; スポーツキャスター名
2=Bob Costas
3=Al Michaels
4=Skip Caray
5=Harry Caray
6=Ralph Kiner
7=Steve Zabriskie
*
2,Items of Performance ; 2番Facet
1=Calling the game ; ランキングの尺度
2=Working with analyst
3=Broadcasting ability
4=Quality of anecdotes
5=Knowledge of baseball
6=Enthusiasm level
*
data= ; それぞれの列に、7項目のランキングが示されている
1,1-6,1,3,1,1,1,4 ; 例)1,1,1 = Vin Scully - Calling - Rank 1
2,1-6,2,1,3,2,3,3
3,1-6,3,2,2,3,4,2
4,1-6,4,4,4,4,6,6
5,1-6,5,7,5,6,5,1
6,1-6,7,6,7,5,2,7
7,1-6,6,5,6,7,7,5
■data の2番Facet を dvalutes で呼び出すこともできる。
→各data行の2列目を省略し、dvalues = 2, 1-6 とコマンドスクリプトに書き加える
(2列目は、2番Facetの1~6で定義した通り)
■Winstepsでも同じ様な分析が可能で、コマンドスクリプトが載せてある(省略)
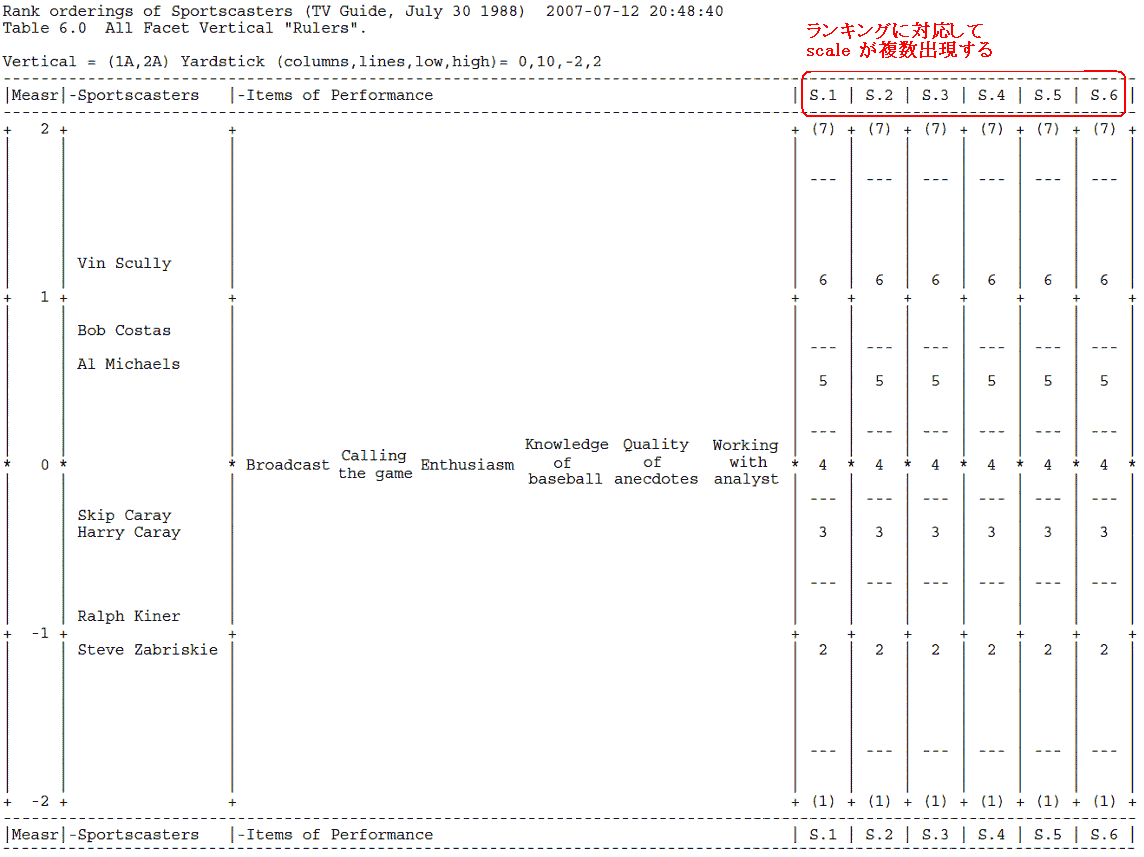
■出力結果から、Ruler はこのようになった。
■ランキング項目の分析結果: misfit している Knowledge of baseball と Enthusiasm level は、今回のキャスターを格付けするには機能してない可能性がある(総合評価で上位のキャスターが下位にランクしていることも関係あるかもしれない)→ Table 4 「予測に反する応答」を参照

■Enthusiasim に関して、総合ランキング1位の Vin Scully が4位、5位の
Harry Caray が1位、と逆転現象がみられる。Knowledge of baseball に関しても、2位の
Ralph Kiner は総合ランキングでは5位。
ディスカッション&コメント
・Mがmissing dataを扱いたいときに用いる記号だということは分かったが、MとXの違いについて理解する必要がある。
・オリジナルのデータと、多少手を加えたデータを比較できたので、大変わかりやすかった。
(森本)
ページトップに戻る
第8回 7/26発表分
40. One-facet paired comparison: League Baseball
■アメリカン・リーグでおこなった22回の各チーム総当たり戦をモデル (Mosteller, 1951)としている。各組み合わせの対象チームが対戦チームに勝利した数をベルヌーイ試行 (Bernoulli trial) に基づく成功回数としてモデルに組み込む。Facetはチームの1つだけであり、チームの成功確率はチーム間の能力の違いから計算される。
今回のモデルでは、対象のチームの観測値(対象のチームの勝利数)「?」と、対戦チームの観測値(対戦チームの勝利数)「-?」とで対を成してバランスをとっている。
ただし、チームが同じ試合数で対戦しなかったため、2番の Extra Facet を用意してある。このExtra Facet とはモデルの切り替え役 (model selector) として、ベルヌーイ試行での正しい値を特定する際に用いられる(1番Facetへの影響を避けるため、0に固定してある)。
; baseball.txt (Mosteller, 1951, Psychometrika, 16/2, 207-218)
Title = American League Baseball 1948
facets = 3 ; 入力してあるFacet は3つ: 勝ちチーム、負けチーム、Extra Facet
arrange = m,N ; arrange tables by measure-descending,
; element number-ascending
entered in data = 2,1,1 ; classifying facet, then two elements are from facet 1
model での Facet の分析手順を操作 → はじめに2番、あとの2つが1番Facet で構成される
positive = 1 ; 1番Facet(勝利数に応じて Logit が高くなる)
non-centered = 0 ; 全ての Facet が 0 を基準にとる
unexpected = 2 ; report ratings if standardized residual >=|2|
models=
22,?,-?,B22,0.5 ; first team opposes second team 22 times
; 対象チームは対戦チームと22試合おこなった(通常の対戦カード)
21,?,-?,B21,0.5 ; Washington-Chicago played 21 times
; 中止などで21試合で off になった場合(ワシントン 対 シカゴ の対戦カード)
23,?,-?,B23,0.5 ; Cleveland-Boston played 23 times
; 再試合などで23試合おこなった場合(クリーブランド 対 ボストン の対戦カード)
; weighted 0.5 because all data points entered twice
; element の値は2回現れるので、0.5点の重み
*
labels =
1,Teams ; 1番Facetの定義:チーム
1=Cleveland ; element (チーム本拠地)の名前
2=Boston
3=New York
4=Philadelphia
5=Detroit
6=Saint Louis
7=Washington
8=Chicago
*
2,Games played,A ; dummy facet - all elements anchored at 0
21,21 games,0 ; used for model selection only - anchored at 0
22,22 games,0 (試合(観測)回数の違いが、モデルに影響を与えさせたくないため)
23,23 games,0
*
data=
23, 1,2,12 ; 23試合で、1番のチーム(Cleveland)は2番チーム(Boston)に12勝
; ↓ 対戦チーム番号をハイフンで繋げば、勝利数をまとめて入力できるらしい
22,1,3-8,10,16,13,14,16,16
22,2,3-8,14,12,15,15,15,14
22,3,4-8,12,13,16,17,16
22,4,5-8,10,18,14,16
22,5,6-8,11,16,14
22,6,7,10
21,6-7,8,13,12 ; Chicago only played 21 games against 2 teams
; same data pairs reversed(前半と対になっているデータ:観測している中身は同一)
23, 2,1,11 ; 23試合で、2番チームは1番チームに11勝(前半の1列目と足すと23試合)
22,3-8,1 ,12, 6, 9, 8, 6, 6
22,3-8,2 , 8,10, 7, 7, 7, 8
22,4-8,3 ,10, 9, 6, 5, 6
22,5-8,4 ,12, 4, 8, 6
22,6-8,5 ,11, 6, 8
22, 7,6 ,12
21, 8,6-7, 8, 9 ; Chicago only played 21 games against 2 teams
■Models について、Facet は以下のように定義される。
22, ?, -?, B22, 0.5
② ① 逆① ② Extra(得点の重み付け調整)
■2番Facetの "-?" は結びついている別Facetと対応していることを示す。(pp.66-67)
-? は、どんなelementでも釣り合わせることができるが、対応している測定値を逆方向から入力し、model での値の重みは 0.5 とすべき。(ペアとなっているデータで折半)
少しページをとばして、データファイルの書き方をおさらい
46. Facets requires specifications and data
a) specifications とは、データをどのように分析するかを命令すること
b) データは概して質的な観測によるもので、同一のファイル、または別々のファイルとしてspecification を与えることができる。それぞれは定義・特定化された要因 (Facets) との相互作用を通して採られたデータ得点、応答、観測や採点結果として分析される。
The Template File
■データファイルの骨組み。コマンドバーの [Edit] → [Edit from template] で呼び出すことも可。
Title = ここにタイトル・見出しを入れる
Facets = ? ; ここにFacetの数を入れる
Positive = 1 ; ここに正の方向を好ましいとするFacetを入れる(例.受験者=平均より能力高い)
Noncentered= 1 ; ここに基準が流れるFacet(平均のLogitを0としない)を入れる
; Vertical = ; Table 6 Rulers の表示をデフォルト以外で設定したい場合に入力
Arrange = mN ; Table 7 の表示を整列させる基準(Logit,名義)や順序(降順/昇順)を設定
Models=
?,?,?, ...,R? ; model の説明をここに入れる
*
Labels=
1, 1番Facetの名前
1= 1番Facetで1番目にくる element の名前
2 =
*
2, 2番Facetの名前
1= 2番Facetで1番目にくる element の名前
*
data=
; Facet の順番にしたがって入力:
; 1番Facet の element どれか, 2番Facet の element どれか, , , , 観測値
47. Specification format for Facets
Syntactic Rules:
a. 1行につき、specification は1つ
b. それぞれの行で、最初の1文字または2文字目までが意味を為す
例)Title=, Titel=, T= ・・・ 全て同じ意味
c. 大文字/小文字は同じ specification として扱われる
例)Title=, title= ・・・ 同じ意味
d. セミコロン/;/のあとに続く入力は、コメントとして無視される
e. 空白行は無視される
f. 値に前後して置かれる空白(スペース)は無視される
g. イコール記号/=/とカンマ/,/はセルを区切るのに用い、互いに入れ替え可能
h. 各行は、印刷設定やDOSテキストで標準としている改行位置までには終わらせる。またワープロソフトからデータファイルを作成する場合、DOS/ASCII 形式で保存すること
i. Facets= (相の数を指定)は、どのコマンドよりも先に記述すること
Code Action
= ・・・ セル/文字列の区切り
; ・・・ コメントとして分析からは無視
;; ・・・ 無視されるが、出力ファイルには載る
■行に書き込まれた値は、カンマ/,/ イコール記号/=/ タブ によって分割され、以下は同じ意味
2,23,6,4
2=23=6=4
2 23 6 4
48. Data references to facets and facet elements
■採点者、受験者、項目等を例にした場合、
それぞれの element 番号は 1~2147483647 の間で、重複しないように番号を与えること
・Element 0 も "Keep=" というコマンドを書き込めば、使用できる
・異なる相で、番号が重複することはありうる。
→ 例えば、評価者1が 受験者1の 項目1について採点したelement
・データはそれぞれ、1つのelement につき1行で書き込まれる
例)評価者2(1番Facet)が 受験者23(2番Facet)の 項目6(3番Facet) について
4点の採点結果(観測R)を下した
→ 2,23,6,4
■データポイントや評価得点は「正の整数」(model= / Label= 等のコマンドで指定された整数)でなくてはいけない。Facets ではデータの値が高ければ、より多く潜在的な因子があると解釈される。つまり "1" を正答で処理した場合、誤答を "0" よりテスト発揮した能力があったことを示す。
■データを書き込んだ行は "Facets=" で指定した数と同じ element の数が存在し、相の番号順に並べるのが通常。element は "Label=" の後に書き込まれたとおりに名義番号や名前が与えられる(コマンド "Entered=" によって取り消された場合は除く)。
■データポイントの繰り返しは "R" と数字の組み合わせで記述
例)R3,2,23,6,4 → 4点という結果が、前述したFacets3つの状況で3回繰り返し観測された
(!)Rating score も R で model= の右端に書き込むので、紛らわしい
■(練習)p.57とは内容を書き換えてある。
Labels=
2, Person
13=Shinashina-Shuji
23=Tanaka&Togashi
33=Oriental TV
43=Mirin
*
1, Judge
1=Shimada Shunsuke
2=Samba
3=Matsushita Hitoshi
4=Nishiyama Kiyoshi
*
3, Item
1=Tempo&Timing
2=Topics
3=Enthusiasm
4=Originality
*
■Example 1: Data Record は、どんな状況を説明しているだろうか?
Data=
2,23,4,1
審査員2番のさんば氏は、23番のタナカアンドトガシの独創性について、1点の評価だった。
■Example 2: Example 1 とFacet は同じ構成だとすると?
Data=
4,13,1,3
審査員4番の西山きよし氏は、13番品々修司のテンポ・タイミングについて、3点の評価だった。
■Example 3: 文字による評価 (letter grades) を、数値として扱いたい場合
scale= specification
例)13番の生徒が書いた 作文課題1に対し 教師4番が B+ の評価を下した とする
Rating (or partial credit) scale=Grades,R9
9,Best,,A
7,B-Plus,,B+ ;数値に変換した後の得点,評(良/不可 等),,実際に使ったLetter Grade
: : :
: : :
*
Data=
13,4,1,B+
■Example 4: Date がFacet番号の順番どおりに入力したくない場合、Entry= で data records の順番を操作できる。
Facets=4 ;1番=Judge(評価者), 2番=Person(受験者), 3番=Item(評価項目)
Entry = 3,2,1 ;3つの Facets だけが Data に入力されてある。順番は本来とは違えている
Model = ?,?,?,D ;はじめの ? マークは Entry で最初に割当てられた相、つまり3番 Facet
;Model も Entry にしたがってデザインされる
Data =
4,23,2,1 ;Judge2番は Person 23 番をItem 4について1点(または正答)と判断した
③ ② ① D
■Element 番号で "0" は、そこの element に参加者が不在ということ(例えば、それが評価者の相だとすると、そこに評価者を割当てていない、または評価者がいなくても採点できたことになる)。
ただし Keepzero= を使えば、通常の番号と同じように0番が使える。
Facets=4 ;1番= Judge(評価者), 2番= Person(受験者), 3番=Item(評価項目), 4番=不明
Data=
2,0,27,3 ; 評価者2番は項目27番の採点には、採点を必要としなかった
■Example 5: データによって、相の説明を必要としない場合
受験者13番は(F2)項目9番(F3)で1点の評価だったが、採点者は不在(F1)
data = 0,13,9,1
■共通の相でelement 番号が昇順または降順で連続していて、なおかつ他の相が固定されていれば、複数の観測値を同一の行に入力することができる。
→ 方法は、両端の番号をハイフンで結ぶ( 例. 項目1から10まで通してなら "1-10" )
例)評価者(F1)2番が受験者(F2) 23番の項目(F3) 6番への評価を4点、受験者24 には5点を与えた場合
2,23,6,4
2,24,6,5
→ 2,23-24,6,4,5
■Example 6: 受験者3番(F1)が10項目(F2)のテストを受け、1~5問目で正解、6~10問目で誤答した場合
data =
3,1-10,1,1,1,1,1,0,0,0,0,0 ;項目番号を昇順で入力
3,10-1,0,0,0,0,0,1,1,1,1,1 ;降順で同一データを入力
または、
data =
3,1-4,0,0,0,0
3,5-10,0,1,1,1,1,1 ;行を改めて応答を追加することもできる
■Example 7: 受験者13番は、評価者8番から項目2について3点、項目3では4点、項目6では2点だった。 これをデータファイルで入力すると、以下のようになる
13,2-3,8,3,4 ;項目2と3は連続しているので1行
13,6,8,2 ;項目6は連続していないので改行
もしくは、カンマでセルを区切って
13,2-6,8,3,4,,,2 ;項目4と5をmissing 扱いとすれば、1行で入力可能
■Example 8: データ形式を整理する
Person Judge Responses to items 1 to 6
13 4 134243
5 17 243223
■Facets の形式にワープロソフトで整えると下のようになる (Facets では空白は無視される)
13 , 4, 1-6, 1,3,4,2,4,3
5 , 17, 1-6, 2,4,3,2,2,3
または、3番Facet をRating Score Facet に付与して、埋め込んでしまう ( "Dvalues=" を使う)
Dvalues = 3, 1-6 ; 3番Facet は項目1-6 の応答結果(下の赤字の部分)に含む
Data=
13 4 1 3 4 2 4 3
5 17 2 4 3 2 2 3
ディスカッション&コメント
*"Entered in data"のところで指定すると、FACETの表示の順番を変えることができる(これはデータの見易さの向上がひとつの理由である)。
*"-?"など、今まで触れたことがなかった記号が出てきたため、その都度マニュアルで確認していく必要があると思った。―>データが逆の順に読み込んでほしいときに使う(8月24日のセクション56を参照のこと)
*Table 8.2で、"Counts Used"が対称になっているのは、データに繰り返しがあるからであるということが分かった。
*"0"の使い方やテキスト形式で入力する際には折り返しをさせないこと等、復習ができてよかった。
ページトップに戻る
第9回 8/24発表分
43. Measuring, Anchoring and Describing: An Arithmetic Test
■測定での疑問の多くは、2つの相で取り組んで調べてみるとよい。
1.生徒の能力、評価者の厳しさ、項目困難度 など
こうした実質的な参加者の要素は相互作用しながらの観測値で測定される。係留された要素があれば、追分析で安定した枠組みが得られる。
2.評価者訓練やテスト内容の下位分類 など、要因による影響がデモグラフィックで確認でき、参加者の要素は仮定された値で置き換えられ、評価の分かりやすさ、測定条件などを考慮して更に追分析へと進められる。
■サンプルでは Mislevy のデータを用いており、776名の生徒の計算能力 (fixed effect) を測定してある。分析は、能力に対する性別や人種における影響の特定を目的としている。
最初に、項目困難度と受験者776名の能力測定から。
title = Arithmetic Competency - R. Mislevy
anchorfile = measure.anc ; ここに anchored file を書き込む
facets = 4 ; これらの相がデモグラフィックに含まれる
pt-biserial = y ; 大まかなfit値を point-biserial で表示する
vertical = 1N,2A,3A,4* ; (?)for communication
yard = 0, 4 ;マニュアルには書いてないが、ruler の幅は必要量だけ、1 Logit は4行分
models =
?, , ,?,D ; 項目(F1)と生徒(F4)の相互作用による測定結果を分析
; ?,?,?, ,D ; このモデルは demographic summaries を出力してから-ここはコメントアウト
*
positive = 2,3,4 ; 項目困難度(F1)を除いた全てが能力を表す
noncenter = 2, 4 ; 0を基準としない生徒の能力値(F2)と、demographic に用いる相(F4)
labels =
1,Arithmetic
1-4 ; 計算項目は4つ
*
2,Race
1=Black
2=White
*
3,Sex
1=Female
2=Male
*
4,Students
1-776 ; 生徒の情報は番号以外なし
*
Data =
1-4,2,2,1,0,0,0,0 ; 4項目に対し, この白人で男子の生徒は全問不正解
|
1-4,1,1,776,1,1,1,1 ; この黒人で女子の生徒776番は全問正解
または、以下のように書き換え可(Dvalues で項目番号を省略)
Dvalues = 1, 1-4 ; 1番Facet の項目番号 1-4 は全データ・レコードの1列目に含まれる
Data=
2,2,1,0,0,0,0 ; on the 4 items, white male student 1, failed
|
1,1,776,1,1,1,1 ; on the 4 items, black female student 776, succeeded
■記述ではデモグラフィック効果の概算がおこなわれる。このデモグラフィックは
anchorfile を作ることで得られる
Facets で MEASURE.txt を specification したのち、MEASURE.ANC というデータ・ファイルが作られる。(sample の MEASURE2.ANC が同一のデータ):
title = Arithmetic Competency - R. Mislevy
; anchorfile = measure.anc ← ファイル生成後は、コマンドがコメントアウトされる
facets = 4
pt-biserial = y
vertical = 1N,2A,3A,4*
yard = 0, 4
positive = 2,3,4 ; facets 1, 2, 3 this time
noncenter= 2,4 ; facet , Race, 2 floats 前のファイルと同じ
Models=
;?,,,?,RS1,1, (D) ;ファイル生成後は、測定モデルをコメントアウトする
?,?,?,,RS1,1, (D) ;(?)集約モデルでの分析はこちらを使う use the summarizing model
*
Rating (or partial credit) scale=RS1,D ; 測定値は rating scale を用いる
0=,0,A, ; (?)calibrations in the description run
*
Labels=
1,Arithmetic,A ; これらの Logit は calibrations によって係留(anchored)してある
1,1,-.6079245
2,2,-.1628681
3,3,.4518689
4,4,.9676156
*
2,Race,A ; Logit が書き込まれていないため、ここの A は作動しない
1,Black,
2,White,
*
3,Sex,A
1,Female,
2,Male,
*
4,Students,A ; ここの facet は今回の分析では無視される
1,1,-2.652209; ここの係留された値も無視される (!) マニュアルと sample で値が異なる
|
776,776,2.654636
*
Data=
1-4,2,2,1,0,0,0,0
|
1-4,1,1,776,1,1,1,1
56. Facet control characters
■使いはじめは記号(Control characters)の理解が難しいので、まずは一読して "Examples" や "Matching" のセクションを通じてコツをつかむとよい。Facets はModelと同じ順序で配置するのが原則であり、date line の入力・記述もそれに合わせる。Model 定義は一行にそれぞれの相を含める。Zero terms "0" は Entry コマンドの中で用い、分析の回避に使う。
Model= Facet control characters
? : モデルは、ここで指定されたFacet 内のどんな element データでも適合させる。(例.受験者)
# : モデルは、指定されたFacet 内のどんな element データでも適合させる。また、独自の rating scale を持ったモデルへとそれぞれの element を適合させる(例.partial credit を特定したい評価項目 等)
blank : モデルへの適合からは無視される。ただし、モデル内でのデータ特徴を、Labels= で書き込まれたとおりに element 番号/名義で表示できる。入力では ",," のようになる。
X : モデルへの適合からは無視される。またモデルが適合している限りはFacet内の element 番号はチェックされない。
0 : 参加者が不在のデータが含まれた Facet をモデルに適合させる場合のみ使われる。
- : 他の Control character と併用し、-?/-# のように使う。他のFacetで反対に位置するelement のペア(例.num のはじめと終わり)を結び付けて分析できる。どんな element でも釣り合わせることもできるが、同一Facetのデータを逆方向から入力したものを結びつけ、モデルでの観測得点の重みを折半にした分析を推奨している(主に繰り返しデータ (sec. 40) 等)。
an element number 例えば "23" と入力したとき、番号23 のelement のみを扱う。
number-number 例えば "23-36" と入力した場合、"23,24,25,26,27,28,29,30,31,32,33,34,35,36" と同義とみなす。つまり、番号のはじめと終わりの範囲にあるelement 全てを扱う(連番入力)。
number# 番号の右隣に#、例えば23#/23-36# と入力した場合、指定された番号の element をデータとして扱う。ただし、それぞれのelement は独立した基準や部分的信頼性 (partial credit) に結びついた観測得点として扱われる。
B 例えば Model= ?B,?,?B,R のように書き込んで、分析モデルの設定に使う。少なくとも2つの Facet を指定し、その組み合わせによって推定される誤差の値を算出する。この記号は他の control character を付け加えることもでき(例."?B")、1つないし2つ以上のモデルを設定することもできるが、組み合わせの必要に応じて全ての設定 (model statement) を入力する必要がある。
例.Models = ; examinee, task, judge, rating scale
?B,?B,? ,R10 ; 特定のタスクが受験者の得点に誤差を与えてないか調べたいとき
?B,? ,?B,R10 ; 特定の評価者による受験者の評価得点に偏りがないか調べたいとき
?B,?B,?B,R10 ; 受験者、タスク、評価者のあらゆる組み合わせで測定誤差を調べたいとき
(長橋)
ディスカッション&コメント
・今回も実際にFACETを動かしてみて、MINIFACでは2000以上のデータを扱ったときに、特にwarningが出ないことがわかった。MINIFACを用いて多くのデータを扱いたい場合には、そのデータ数が2000を超えていないかどうかをよく注意しないと、誤った結果を提示してしまっている可能性があるため、要注意。
(森本)
ページトップに戻る
第10回 9/14発表分
■当初の予定を変更し、今年度、発表者(長橋)が行っている調査(作文テストの評価について)のデータをFACETSで分析。
今回のケースに当てはめたデータファイルの入力方法を復習し、出力結果の解釈を中心にディスカッションした。
(発表資料はホームページ上では非公開。また、9/14に当初予定していた発表箇所は次回9/28以降に延期した)
ディスカッション&コメント
・FACETで評価者の厳しさやミスフィットが出てくると、一見その評価者には今後の採点を任せられないのではないかという心配が生じるが、その評価者に対してのトレーニングを行える(フィードバック、評価者トレーニング)という点では分析結果が実際の教育現場にも役立ちそうだ。
・1.00を基準として、そこから.30以上(または.40以上)をミスフィットとして扱い、分析から除くなどの措置を取ったが、overfitの取り扱いについてはどうすべきだろうか?恐らく、大規模なテストを行い、その結果を必要最小限の人物で採点を行うという場合には除くことも良いが、別の傾向を示す評価者を外す目的の場合にはoverfitの評価者を含めていても良いのではないかという結論となった。
書記より個人的に感じた点
・相関をとってみて値が高かった場合であっても、それぞれの評価者が内部一貫性をどの程度持っているか、他の評価者と比べてどの程度厳しい(または甘い)のかが分からない場合が多い。FACETでそれらを確認することで、基礎的なデータをどのように取り扱うかを判断できそうだと感じた。
・評価者については、指導経験や採点観点によって、さらには時間の経過によっても基準や甘さがバラけることが分かった。特に、指導経験は対象とする学生の熟達度で求める厳しさなどの基準が変わったりするのかどうか気になった。
・ミスフィットの高い評価者を除いたあとで同じ分析を繰り返すと、一度目の分析では、あてはまりの良かった評価者がミスフィットとなる場合が出てくる。このような手順は何度か繰り返すことが必要なのだろうか?私も、反応時間などで凄く遅すぎ・速すぎるレスポンス(±2.5SDや±3SD以上)を削除し、その後更に±2.5SDや±3SD以上となるデータを削除する場合があるが、本当は一度に留めるべきなのだろうか?
→ 評価者は貴重なので、評価者を削除することによって、その評価された被験者が削除されるのでかなり慎重に行わなければならない。また、評価者が1人だけでなく、複数の評価者が高いミスフィット値を示せば、その評価尺度(方法)に問題がないかを、まず考えるべきだろう。同様に、person
misfitの結果で、ミスフィットの被験者がそのサンプル中の2%以上であれば、問題のあるタスクはないかを検討する(McNamara,
1996)。かなりはずれている被験者を除くことも考えられるが、ミスフィットの被験者をはずして再度分析を行っても、新たにミスフィットの被験者が出てくる場合が多い。2%以内であればその被験者を分析からはずす必要はなく、たとえ2%以上であっても機械的に削除する必要はないように思う。
(中川・平井)
ページトップに戻る
第11回 9/28発表分
(発表資料はホームページ上では非公開。9/14から予定していた発表箇所は次回10/13に再延期)
第12回 10/13発表分
71. Fair averages based on = Mean
■Fair average scoreとは、関係している他のfacetによる困難度・厳しさが同等になったと仮定した場合のLogitを測り、予測される得点を返したもの。
75. Inter-rater Agreement Coefficients = 0
■評価者に関するfacetを指定することで、評価者間での完全な一致頻度・率を報告する。
(!) This specification is misinterpreted to mean Iterations= in early
versions of Facets.
Inter-rater = facet number :データファイルへの命令行
■あらゆる評価者・評価対象・基準の組み合わせで、何回採点がおこなわれたのか、またどのくらい完全な一致があったのか表示できる。また、ラッシュ・モデルに当てはめた一致率の予測値も計算される。
→ 重複するが、採点機会の数は総当りの組み合わせで報告される。これによりmissing dataが混ざっていないかを確認できる。
100. Unexpected (standardized residuals reported, if not less than) = 3
■規定値を超える標準残差を表わす応答(エレメント)について、リスト化して報告する。5%水準の標準残差であれば、±2、1%水準であれば±3を超えた値が検出される。特定のエレメントで局所的なmisfitが起こってないか確認できる。
例 1: 絶対値2.5を超える標準残差全てを抜き出したいとき
Unexpected=2.5
例 2: 全ての標準残差を抜き出したいとき
Unexpected=0
■Facets Manual は、113. Completing analysis以降のセクションで出力結果の読み方を直接的に扱っている。(一部、前のセクションで解説し、繰り返している場合もあり)
117. Table 4 reports Unexpected Responses
■これらのコマンドは Table 4 に関係している。特定化された値以上の標準残差がある応答は Unexpected=. で表示、表示順序については、Usort= で指定できる。
■下は残差が規定値を超える原因として考えられるものをリスト化したもの。
1)誤った形式で入力してないか(生データからFacet用へ変換した場合は特に)
2)採点時の解答に誤りがないか。例えば、多肢選択問題など。
3)rating scale や partial credit items の値と解釈の認識が逆に扱ってないか。この場合は "-?" で model を組むことによって特定のエレメント群が逆方向の解釈が可能。
4)特異でいわゆる "off-variable" がみられる場合。考えられる原因として、大雑把な推量で応答、「わからない」のオプションへの回答が頻繁にみられる等、測定方法が意図した行動を計測できてない場合が考えられる。こうしたデータはmissingでコードし直すのがよい。(modelからMデータの定義)
5)特定のエレメントに予測外の残差が重み付けて影響している可能性。Facets は入力されたデータファイルの列、規則性にしたがってmisfittingを報告するため、このTable 4から残差の大きさ順に並べて吟味するには便利かもしれない。また、misfitの組織的パターンの把握が誤差分析や Model= コマンドの再考で促進できることもある。
■測定モデルでは常にある程度のmisfitは表れるものであり、どのへんで分析の目的に適ったモデルとなったか決断しなくてはならない。
表中の記号の読み方:
Cat = データファイルで入力された結果(カテゴリー)
Step = "0" を最小として数え直した場合のカテゴリーの値
Exp. = 現行のモデルで予測された得点
Resd = StepからExpで差し引いた残差
StRes = 標準化された残差だが、1.6が1で報告されるため注意。正確な値はResiduals fileを参照。
122. Table 7 is the facet measurement report
■各列の記号は、以下のとおり(ほとんどが頭書きで表示):
Obsvd Score = 実際の採点で与えられた得点の合計。
Obsvd Count = 実際の採点をおこなった回数。
Obsvd Average = 上記2つで割り算をした場合の、実際の得点平均。
Fair Avrge = ラッシュ・モデルにあてはめて生得点が公平な条件で出されたように収束・標準化させた値。基準値としてFair-Mが使われるが、0を基点にしたFair-Zもある。
Error = モデルに適合した場合の漸近的な標準誤差 (Model error) と、モデルに適合しないデータで拡大する場合の誤差 (Real error) がある。
Standard error = Real errorが大きくなるのはデータから敏感に影響するためである。Xtreme = コマンドを使えば、極端な得点による標準誤差の予測がわかる。なお、統計サマリーでは極端な得点による標準誤差は省略されている。
Infit MnSq = 重み付けがされているfit値の平均平方。実際の観測からのノイズが少ないが、応答パターンに影響されやすく、独立性に乏しい。
Zstd = 平均平方を標準得点化したもの。小数点以下が切り捨てられて報告されるので、注意が必要。例えば1.00 ~ 1.99 は 1、-1.00 から -1.99 は -1といった具合。
Outfit MnSq and Zstd = 重み付けがされていないfit値の平均平方、基本的に解釈はInfitと同じだが、外れ値に影響されやすい。
Estim. Discrim = 2パラメータ・ロジスティックモデルのように、項目弁別力を予測する。他のパラメータに影響されない限り1.0が期待される値で、標準的な項目特性曲線を描く。1.0より小さいと曲線の傾斜は緩く、高いと急勾配な傾斜となる。
PtBis = ひとつの応答に対する全体との相関。
Exact Agreement = 命令行 Interrater= で報告される、raterの一致率。実際の採点結果と、予測値での両方で計算され、実測値での一致率が高い場合、偶然等による見せかけの一致も含まれていることになる。
123. Table 7 Reliability and Chi-square statistics
Mean = いわゆる平均
Count = 報告されたエレメントの数
S.D. (Populn) 母集団を仮定した標準偏差
S.D.(Sample) ランダムに抽出されたサンプルに基づく標準偏差
With / Without extremes 極端な得点(0点・満点)を報告に含む/含まない
Model ノイズを考慮してモデルが最大限適合化した場合の予測
Real ノイズを特定せず最低限でモデルが適合する場合の予測
RMSE (root mean square standard error) 0点・満点を抜いた場合の標準誤差の平均
→ (?)自乗して自乗根で戻すのは、正の値をとるからだろうか
Adj (True) S.D. 真の得点から求めた標準偏差
Separation 調整済み標準偏差をRMSEで割った値 (Adj S.D. / RMSE), 適合した予測値の散らばりを示す測定値。有益な情報と役立たない情報との比率
(signal-to-noise ratio) は Separation^2で表せる ( = "true" variance
/ error variance)。
Reliability (not inter-rater) ラッシュ・モデル分析独自の係数で、KR-20 またはクロンバックαに相当する。言い換えれば「観測値の分散」に対する「真の値の分散」比率。これはテストがどれくらい違いを測定しているか成功度を示す。受験者(person)と項目(item)は、1.0に近いほど好ましいが、一方、この信頼度は評価者間信頼性 (inter-rater reliability) とは正反対の性質を持ち、評価者 (judge / rater) にとって0.0に近いほど望ましい。
Fixed (all same) chi-square: 母数効果仮説 (fixed effect hypothesis) の検定: 一連のエレメントが、測定誤差を考慮に入れた上で同じものを測っているか調べる。有意な場合、この母数効果があると仮定されることを意味し、Tableが示すfacet (e.g., 項目/評価者) によって 「テストの項目が同じくらいの難しさだったか」とか、「評価者は同じくらいの厳しさだったか」等に統計的な答えを返す。
Random (normal) chi-square: 変量効果仮説 (random effects hypothesis) の検定: 一連のエレメントが正規分布した中の無作為抽出といえるか調べる。有意な場合、変量効果があると仮定され、正規分布した母体から無作為抽出されたサンプルであると考えられる。
124. Table 7 Agreement Statistics
■inter-rater= コマンドにより評価者facetが定義されている場合、それぞれの評価者ペアで応答の一致している統計量が報告される。報告される数と率は評価結果が完全一致したものに限り、期待値による一致率も報告される。これによって、評価者間信頼性の一側面として、評価者が独自性のある評価をおこなっているか、単なる機械的な採点結果を返しているだけなのか調べられる。
ページトップに戻る
第13回 10/26発表分 【最終回】
152. Decimal and continuous data
■Facetsでは整数でデータを扱うことが前提となっている。この整数は、観測している対象を質的な階層順列でつけた値として捉える。
Decimal data: 小数を含む観測値は掛け算を利用して整数化する。もしくは Rating scale = のコマンドより、データの再コードをさせる。例えば、パフォーマンス評価得点で0.5点刻みの値を扱う際は、倍掛けするとよい。もともとの得点のままで扱いたい場合は、下記のとおりモデルを定義する:
Model = ?,?,?,R6, 0.5
Continuous data:
■数値を範囲で括りながら昇順で良しとする解釈を扱いたい場合(例.速い方が優れている時間タスク)、0-0.5 seconds = 6; 0.5-1.0 seconds = 5, 1.5-2.0 seconds = 4...のように Rating scale= で定義するとよい。
153. Diagnosing Misfit
General rules:
Mean-squares(平均平方)は無作為性の尺度であり、測定方法の歪みを診断し、この場合1.0が期待される数値である。一方1.0を下回る数値は、ありきたりな観測・余剰データばかりを集めていると診断されmodel overfitとも呼ばれる。反対に1.0を上回る場合、予測に従ってないことを示し、モデル適合しないノイズ、またはmodel underfitと呼ばれる。
mean-squares は通常1.0を平均にとるため、これより高い値が存在すれば低い値も当然現れる。必要であれば、一時的に高い値のエレメントを先に除外してから分析を繰り返すこともありうる。
Zstdは「モデルと完全に適合しているか」という仮説にt検定で答えており、z-scoreで報告している。有意性を回避したいのであれば0.0が期待される値であり、負の値をとるとoverfit寄り、正の値をとると予測から離れていることを示す。もしmean-squaresが許容範囲ならZstdは無視できる。
Zstdは小数点以下が省かれ、1.00 から1.99までは 1 で、2.00から2.9は 2 で報告される(より正確な値はscore filesを参照)。
Guidelines:
(a) 負の双列相関がないか探し、そこに大きな応答の残差がないか調べる。まずはこれらを取り除くべき。
(b) Zstdが許容範囲 (絶対値2ないし3を下回る) なら、深追いしてみる必要なし。
(c) mean-squareがモデルからそれほど離れていないなら、データは測定に貢献している。
(d) misfitエレメントの割合が小さければ、含めたままでも削除しても実質的な違いはない。また、両方の分析をおこなって結果比較するのも方法のひとつ。
(e) misfitエレメントを除いて結果が改善された場合、
(i) エレメントを除いた結果を採用する。
(ii) エレメントを除いた分析をし、anchorfile= をつくる。
(iii) anchorfile= を編集し、misfitエレメントを有効に戻す(missing コマンドの削除)。
(iv) 編集後のanchorfileで再分析をおこなう。
■これによって測定の質を下げることなくmisfitエレメントを意図した測定の枠組みに配置されるようになる。
Anchored runs:
■係留値 (anchor values) となったデータが、モデルに適合しなくなる場合もある。これは統計値が誤って適合した場合が考えられる。極端に中央に位置した値を分析中のデータに係留させると、適合しすぎでモデルの融通が利かなくなったり、逆に中央から外れた値を係留させると、データにノイズを与えたりする。
Mean-square interpretation:
2.0を上回る場合、測定システムを歪め、質を下げる。
1.5から2.0の範囲は、測定の質を下げるほどではないが、解釈には貢献しない。
0.5 から1.5の範囲なら、測定の解釈に貢献している。
0.5 を下回ると、測定の質を下げることはないが、解釈にはほとんど貢献しない。注意すべき点として、reliabilityやseparationの結果が実態よりも良く出すぎでしまい、誤った解釈を導く場合がある。
■一般的にmean-squareは1.0に近いほど測定システムに歪みが少ない。
154. Dichotomous Misfit Statistics
OUTFIT:外れ値に影響を受けやすい。
INFIT:応答パターンに当てはめやすい。
→ INFITは外れ値を除いたモデルから診断しているらしい。
155. Differential performance on items
(発表者の資料研究が進展次第、随時更新する予定)
156. Equating tests
(随時更新する予定)
160. Fair average
Meaning of the Fair Average:
(随時更新する予定)
Calculation of the Fair Average Score
(随時更新する予定)
A basic many-facet Rasch model for observation Xnmij is:
log ( Pnmijk / Pnmij(k-1)) = Bn - Am - Di - Cj - Fk
Bn is the ability of person n,
Am is the challenge of task m,
Di is the difficulty of item i,
Cj is the severity of judge j,
Fk is the barrier to being observed in category k relative to category k-1,
where k=0 to t, and F0 0.
■上の式から、スコアK点を(K点より1点低い能力から乗り超えて)受験者が獲得する確率を、ロジスティック曲線グラフ(緩い右肩寄りのS字曲線)で表わすことができる。右辺のBn
より右側の項は、タスク、項目、評価者がもつ特性による誤差要因(難しさ・きびしさ)を取り除いた値が、真の受験者の能力であることを示す。
Thus, the model underlying a fair rating, when Fair=Mean, is:
log ( Pnmijk / Pnmij(k-1)) = Bn - Amean - Dmean - Cmean - Fk
or, when Fair=Zero, it becomes:
log ( Pnmijk / Pnmij(k-1)) = Bn - Fk
175. Rater misbehavior
■よくいわれている望ましくない評価者の行動パターン
1. Leniency/Severity/Generosity.
評価者facetで直接数値 (Logit measure) に表れ、自動的に調整される。
2. Extremism/Central Tendency.
採点の方向性での極端な高低差や、中央に固まる傾向。これはmodelオプションのseparate rating scale またはpartial creditを使うことで確認できる。central probability(?) の高い評価者は、極端な配点傾向にあり、逆にprobabilityが低ければ中央化傾向の評価者である。
3. Halo/"Carry Over" Effects.
ある評価特性が別の特性の判断へ誤差となって影響すること。同じ困難度 (通常はLogit=
0で) の項目全て係留し、この測定環境でbest fitした評価者はハロー効果を示している可能性が高い。
4. Response Sets.
評価結果が対象の能力と関係していない場合。同じ能力 (通常はLogit= 0で) の受験者を係留し、この測定環境でbest fitした評価者は、この傾向の疑いがもっともある。
5. Playing it safe.
評価者が独自の採点ではなく、別の評価者に合わせて採点しようとした場合。Inter-rater= コマンドを追加して一致率を調べるとよい。この場合の評価者からはoverfitも検出される。
6. Instability.
状況ごとに評価のきびしさが変動する。
177. Reliability and separation
(Separation) Reliability
■123. Reliability (not inter-rater) と同じ説明)
■サンプルからは「真の」得点による分散はわからないが、概算で求めている。その「真の」信頼性も概算で得られるものにすぎない。したがって、以下の信頼性KR-20, クロンバックα, Separationも単なる概算である。計算方法は以下のとおり:
Separation Reliability = True Variance / Observed Variance
■Facetsでは、真の信頼性が存在すると仮定される下限から上限の範囲を計算する。上限のModel reliabilityは、 ラッシュ分析どおり予測外とするデータに基づき計算される。一方、下限のReal reliabilityはラッシュ・モデルとは矛盾した予測外のデータに基づき計算される。真の信頼性はこれら2つの値の間に存在している。反対方面から互いにデータのノイズを取り除くことで、ModelとReal の信頼性は近づきつつ、真の信頼性がModelの信頼性に近づくという仕組みをとる。
■通常、Person Reliabilityはテストの信頼性と呼ばれて報告されるが、Facetsでは全てのfacetからreliabilityが得られ、エレメントの独立性を仮定して推計している。
■特に評価者は「単なる採点マシン(scoring machine)」ではない「独自性ある専門家(independent experts)」であるかを検定しており、前者(SM)であれば過剰な値となって現れる。これはちょうど多肢選択問題で全く同じ回答結果を並べて分析すると、テスト信頼性が高い値で出るのと同じ仕組みである。こうした状況に陥ってないか確認するため、Facetsでは評価者たちに独自性があるのかという枠組みで評価者間信頼性の一側面を提示している。
Inter-Rater Reliability (IRR)
■いわゆる従来の評価者間信頼性は計算されないが、正反対の性質をもつSeparation Reliabilityがみられる。他に Inter-rater= コマンドで、定義されたfacetの評価者一致の統計値が報告される。
■一致度は Cohen (1960) のカッパ係数に相当し、計算式は以下のとおり。
Rasch Kappa = (observed agreement% - expected agreement%) / (100 - expected agreement%)
■ラッシュ・モデル環境では、「一致率の期待値(%)」も推計され、Rasch Kappa = 0が最善と解釈される。例えば、次の "Readers" の分析でTable 7.3.1 を参照すると、
Rasch Kappa = (25.2-21.5) / (100-21.5) = 0.05
この場合、Rasch kappaは-0.27 から 1の範囲をとる。モデルが予測している期待一致率よりはるかに低く、過度に消極的な(負の?)Rasch
Kappa係数を示す場合、採点結果の中にモデルに不適合な応答を繰り返している可能性がある。反対にRasch
Kappa係数が0よりはるかに高い値を示す場合、全体に高い一致を含み、Wilson
& Hoskens (2001) のRater Bundle Modelのような、何か代わりのアプローチをとるべきである(?)。
Myford, C. M., & Wolfe, E. W. (2004). Detecting and measuring rater
effects using many-facet Rasch measurement: Part II.
Journal of Applied Measurement, 5, 189-227.
pp. 195-196
■この論文の注目すべき点として、シミュレーション・データを提示した上で、各指標の解釈が分かり易く解説されている。特にテスト評価者の separation に関する解説・解釈は、マニュアルより詳しい(発表者の資料研究が進展し次第、詳述を更新する予定)。
(2) rater separation ratio.
評価のきびしさの特定で、統計的に異なると判断される評価者グループが何層に分かれるか。
(3) rater separation index.
計算式: (4G + 1) /3 (G = rater separation ratio)
separation ratio より値が大きく出る(場合によって、評価者人数よりも多く出ることもある)。参加者で討議したところ、層のしきい/境目の数を数えているものと現状では推測する。
(4) reliability of the rater separation index.
Facets Table で表示される reliability は、従来の評価者間信頼性(ピアソン積率相関係数など)とは異なり、separation に由来する値らしい(マニュアルではKR-20やクロンバックαに相当すると説明した箇所も)。この係数は 0.0 に近ければ評価者に好ましい結果(評価者のきびしさが似通っていて、互換性が高い)になるが、 .70 を望ましい値と具体的に挙げている点で注目される。

ページトップに戻る
{kind=link}
{kind=link}