研究会トップに戻る
5/18 6/1 6/22 7/13 7/26 8/24 9/28 10/13 10/26
11/9 11/30 12/21 1/11 1/25 2/8 2/29 3/14 4/7 4/18
Kormos, J. (2006). Speech Production and Second Language Acquisition. Mahwah,New
Jersey: Lawrence Erlbaum.
2007/05/18 (Introduction, pp. xvii-xxvii)
Issues in L2 Speech Production Research
1. Introduction
● コミュニケーションにおいて会話は最も身近なものであり、「話すこと」はL2学習において重要である。そのためL2の発話のプロセスを理解することはL2教育において重要な位置を占める。本書の目的は、重要な理論や発話産出(speech production)において明らかになっていることを紹介し、第二言語習得研究にどのように関連付けることができるかを示すことである。
● L2発話産出に関する2つの主なアプローチ
(1)認知心理学的研究(cognitive psychological line of research):
→L1研究者が中心。L1研究での問題がL2にもみられるか。実験的手法。
(2)応用言語学的研究(applied linguistic approach):
→SLA研究者が中心。L2学習からのL2発話産出の問題。実験的、観察的手法。
2. Overview of Issues in L1 Speech Production Research
● L1発話産出の4つの重要な構成要素
(a) 概念化(conceptualization):言いたいことを準備する。
(b) 形成(formulation):文法的、語彙的、音韻的にメッセージを符号化(encode)する。
(c) 発音(articulation):発話(音)の産出。
(d) 自己モニタリング(self-monitoring):アウトプットが正確かチェックする。
● 概念化→形成→発音の順で起こる。概念化は意識的だが、形成と発音は自動的。プロセスの仕組みは並行して起こるため、L1の発話はスムーズで速い。
● activation spreading(活性化拡散):脳研究の神経ネットワークから由来。→発話処理システムは段階的レベル(上記の(a)~(d))からなり、activation
spreadingのようにそれらの間で情報が伝達される。またレキシコンや概念記憶の蓄積のような知識の蓄積からも構成されており、それら知識の蓄積の中で項目から関連項目へactivationが伝達される。
● 概念、語形、音素などの単位を表す 'nodes'と呼ばれるものの活性レベルに基づき決定がなされる。
● L1スピーチ産出の2つの理論:(1)spreading activation、(2)modular theories
相違点① 符号化におけるフィードバックの違い
(1)下位レベルから上位レベルへの活性化の逆の流れが可。(エラーが生じると、警告が発せられ、上位レベルに活性化が伝わる。
(2)先に広がるのみ。(エラーが生じた段階では気づかないが、エラーが発話されたら気づく。)発話産出システムの処理要素は自動的で、独自のインプットを持ち、またそのインプットを他の要素からは独立して処理している。
相違点② 統語・音韻的符号化
(1)話者は最初に文や発音表記の枠組みを構成し、枠組みに合うように適切 な語や音を選んでいく。
(2)単語が統語的構築を活性化し、語彙的符号化が統語的符号化より前に起こるという前提。音韻的符号化は語彙・統語的プロセスができた後に起こる。
● これらのモデルでは発話はクリエイティブなものとして捉えられているが、Pawley
and Syder (1983)は、発話はクリエイティブではなく、記憶された一つのまとまりであるformulaic
languageから取り出されるものの連続であると主張している。
● Levelt (1989):イディオムなどは単語と同じようにレキシコンの中に蓄積している。
3. Issues at the Major Stages of L2 Speech Production
● モジュラーモデルではメッセージは概念化の段階で考えられ、概念化のアウトプットはメッセージ伝達のための概念の特定を含む 'preverbal plan'である。
● 話者はコミュニケーションの場面や談話の規則についての情報を含んだ宣言的記憶にアクセスする。(唯一の意識的決定)
● 言語選択は社会言語的、個人的要因に制限される。
● L1/L2の発話プランは並行して起こっているのかどうかという問題があったが、現在ではpreverbal planに言語の手がかりを加えていくという形でなされている。
● レキシコンに蓄積されている語(レマ)は意味的情報を含んでいるのかという問題。最近のモジュラーモデルでは、レマは意味情報を含まず統語情報のみを含んでいるとしている。
● 記憶研究では概念的情報と意味的情報は一緒に蓄積されるもの考えられているが、L2産出においては意見の分かれるところである。
[Lexical encoding]
● 語彙の符号化に関して、preverbal planの概念の特定はレキシコンの中のL2のみを活性化するのか、L1/L2共に活性化するのかという問題。→研究からL1も活性化されるという結果。
● L1/L2が活性化される場合、語彙の符号化において両方とも候補とされるのかという問題。→L1は無視されるのではないか?<L1/L2両方が選択対象になるのではないか?(特定の絵の名前を挙げるタスクではL1は選択対象にならない)
● 語彙の符号化はどのように制御されているのか?→情報(意味、スタイル、使用域など)はpreverbal
planの概念化の段階で特定され、概念に合う語彙を見つけることで選択される。
● バイリンガルレキシコンではL1とL2は共通のネットワークとして同じレキシコンに蓄積されていると考えられるが、賛否両論ある。
● バイリンガルの概念的・意味的システムにおいてL1とL2の語彙は共有されているか?
[Syntactic encoding]
● 語彙と一緒に蓄積されている符号化メカニズムの統語的情報とL1/L2における統語的構築の活性化はどの程度異なるか?
*語のジェンダーの例:統語的情報が似ている場合L1/L2の情報は共有されるか?
文法的特長は語が取り出されるたびに自動的に評価されるのか?
● Meiher and Fox Tree (2003):両方の言語によって共有される統語的規則は、言語によって分類されておらず、一緒に蓄積されている。
● 文法的な形態素はどのように評価されるのか?→文法的形態素は2つの方法で活性化される(概念的、語彙的符号化の過程)
[Phonological encoding]
● 音韻的符号化に関して一度活性化されたが選ばれなかった音韻形式は、レマから語彙項目(lexeme、音韻形式)レベルに下がるのだろうか?→多くの研究では、L2における活性化の移行(cascading
of activation)は語彙、音韻レベルで起こるとされる。
● 音素はL1/L2で共有されているのか?→一緒に蓄積されており、L1/L2で同じ場合は共同の記憶表象(memory representation)を持つ。
● 音韻レベルのL2処理のメカニズムはL1と類似しているか?→Roelofによると類似している。発話に関してはL1では音節が基本単位であり、発話プログラムは音節文字表(syllabary)にある(Levelt,
1989)。De Bot (1992)によるとL2の初級者はL1の音節プログラムに依存し、上級者は独立したL2音節プログラムを構築する。
[Monitoring]
● モニタリングは注意力(attention)が必要であるという点で、L2のモニタリングはL1とは異なる。L2学習者は語彙、統語、音韻処理に注意をとられ、モニタリングまで意識がまわらない。モニタリングの意識は熟達度やタスクに制限される。
4. General Issues in Speech Production
● L1/L2の大きな違いはL2の知識は完全ではないということ。そのためL2話者はコミュニケーションストラテジーを駆使する。
● Dornyei and Scott (1997):L2コミュニケーションの4つの問題
(a) 情報不足
(b) 処理時間のプレッシャー
(c) 自身のアウトプットの不足
(d) 相手のメッセージ理解の不足
● バイリンガルにおいてはL1のL2に対する影響をなくすことはできない。→言語知識がL1/L2で一緒に保存され、言語選択のときにどちらかが抽出される。(Unintentional
code-switches)
● どのように統語的符号化を支配する言語が決定されるのか、2つの言語が発話で用いられつつ、どのようにある一定の規則にしたがっているのか?
● L1転移→意識的なものはコミュニケーションストラテジーの一部。統語、音韻的なものの方が語彙よりも複雑。
● 統語に関して、L1転移における制限はあるか?ある言語能力の段階で転移可能な発話タイプなどはあるか?
● 音韻でもL1転移はよく生じる。
● L1/L2では話すスピードが異なる。L1はformulation/articulationが自動。L2は意識的に行うため、L2における自動化の研究が重要である。
●
5. Summary
● 各章の説明(省略)
(鳴海)
<ディスカッション&コメント>
※今回の範囲は、本全体のsummary的な章であるため、深い議論は、各章を読む中で行いたい。
※spreading activationとactivation spreadingを異なる概念として使用しているという説明があった点が気になる。後章で見ていくことにする。
(中川)
ページトップに戻る
2007/06/01
Chapter 1 An Overview of Theories of First Language Speech Production (pp. 3-11)
1. Introduction
● L1スピーチ研究の起源は、Meringer (1908)のslips of tongueの研究までさかのぼるが、L1産出の包括的理論が構築されたのは1970年代からである。
● 本章ではL1産出の主要な理論―spreading activation theory(活性化拡散理論)とmodular
theory of speech processing(モジュール理論)―について述べる。
2. Spreading Activation Theory
● Levelt (1989, 1993)のmodular modelの方が広く用いられているが、この理論はslips
of tongue / unintentional code-switching / bilingual lexiconの組織の研究の多くに影響を与えている。
● Stemberger (1985)とDell (1986)が最初の包括的なモデルを構築した。ここではDellのモデルを扱う。
● Dellのspreading activation theoryの4つの知識レベル:
① semantic(意味的)level:語の意味
② syntactic(統語的)level:句の構築と語順の規則
③ morphological(形態素的)level:語や接辞の規則を作る
④ phonological(音韻的)level:音素や音韻的規則
Chomsky (1965)の生成文法や、frame-slot model of productionの考えを採用している。
● Dell (1986)は、レキシコンを相互に関係したもののネットワークとして考え、言語単位(例えば、概念、語、形態素、音素、音素の特徴等)のノード(node)を含んでいるとする。概念ノードが語のノードを結び、語のノードが形態素ノードをつなぎ…となる。
● 語が文の中のスロットに入るように選択されるために、語は統語的分類で分けられている。(e.g. "cow"は名詞)同様に形態素や音素も分けられている。(e.g.語幹と接辞)
● 文産出のメカニズムがspreading activation(活性化拡散)である。
<間違いのない産出の場合>
・ 要求されたノードの一番高いレベルのものが活性化
・ その後に来るノードが選択され活性化が下位レベルのノードに拡散していく。(p. 5)
● このモデルでは、選ばれたノードは文法標識が与えられ(tagged)、それがどの様な順で符号化されるのかを特定する。
● 活性化は一つのレベルからもう一つと拡散するだけではなく、レベルをまたいでも拡散する。(語彙レベルではレキシコン内で関連のある意味的、音韻的事項も活性化される。 "dog", "hog", "cat"の例)→slips of tongueを説明
● 活性化は二方向(トップダウン:発話理解、ボトムアップ:文産出)にも拡散する。
例)発話理解 → 音から形態素、語へと進む。モニタリングも同様の働き。
● Dellの理論は、語、形態素、音節、音素などの階層的なネットワークが存在すると仮定している点でLeveltのmodular
modelと似ているが、異なるレベルで平行な処理が行われるとしている点でLeveltのモデルとは異なる。
3. Levelt's Modular Model of Speech Production
● 一番広く用いられているモデルで、モノリンガルのコミュニケーションのために開発された。ここでは最新のモデル扱う
● 発話産出はmodular(モジュラー)であり、つまりシステムにおいて多くの自動的な処理要素が機能することを通じておこる。
● 構成要素は2つに分けられる。
(1)rhetorical / semantic / syntactic system
(2)phonological / phonetic system
● 知識を蓄積する場所が3つ存在。
(1)mental lexicon
(2)syllabary音節文字表(gestural scoresも含む)
(3)knowledge of the external and internal worldを蓄積する場所
→discourse model(談話の内容についての共通の知識の記録)
model of addressee(その時点での相互関係と談話の文脈)
encyclopedic knowledge(一般的な知識)がある。
● 発話処理のプロセス
・メッセージの概念化
・言語表象の形成(符号化)
・発話
● 発話理解のプロセス
・acoustic-phonetic processor(聴覚・音韻処理装置)で発話を受信
・発話理解のシステム内で言語の解読(decoding)
・概念化モジュールで解釈
● このモデルは、聴覚的・音韻的符号化と、文の処理を一つの包括的なシステムに統合している点でユニークである。
● このモデルではそれぞれの処理装置は "specialists"とされ、処理機能を共有しない。処理装置はその特徴的な(characteristic)インプットを得たときのみに作動する。また、処理は付加されていくもの(incremental)と捉えられている。(あるメッセージが概念化から形成に移ったとき、概念化では次のメッセージが他の進度に関係なく概念化され始める)→話者の全体のメッセージが完成する前に発話が始まる。つまり並行的な処理が行われており、産出メカニズムは自動的である。→言語産出のスピードを生む。
● 発話産出に関する処理構成要素(Fig. 1.2, p. 8)
(1) conceptual preparation(概念化準備):メッセージはmacroplanning(communicative intensionが発話行為を通じて表される)とmicroplanning(どのように発話するか、 "accessibility status"を考える。例えば既に述べられたことを考慮し代名詞などを決めたり、適切な時制を決めたりなど。)を通じて生じる。意味を言語化する。
(2) grammatical encoding(文法的符号化):preverbal plan(発話前の計画)であり、語彙単位や統語的符号化の選択が起こる。mental lexiconから情報が取り出される。
→lexical entriesを含む:(a) lemmas(統語的情報、語彙入力。意味的情報は含まない), (b)lexemes(語彙入力の形態素的、音韻的形式の情報)
・lemma activation:発話前の予定の意味と合うlemmaを取り出す
・surface structure:連続したlemmasを句にする。さらに形態的・音韻的符号化で処理される。
・articulation(発話):articulatory scoreが発話へと変換される。
● Leveltのモデルはモニタリングについても説明。モニターは概念化装置の中にあるが、mental lexiconとつながっているspeech comprehension system (parser)から情報を受け取る。
● 知識の重複を避けるために、産出と受信のレキシコンは同じであると考えられる。
● 3つのモニターの輪(loop)がある。
(1)preverbal planと形成前の基の意図の比較。preverbal planに修正が必要かもしれない。
(2)発話前の音韻的計画のモニター。 "covert monitoring"と呼ばれる。
(3)発話後のチェック。聴覚・音韻処理装置を介する。誤りを感知すると、シグナルを発し、2度目の産出メカニズムを起動させる。
4. Summary
● spreading activation theoryとmodular modelの大きな違いは、前者は活性化が様々なレベル間を複数方向に拡散するが、後者は一方向にしか拡散しない。
● また、統語的、音韻的符号化を異なって捉える。前者は、話者がはじめに文や音韻の枠組みをつくり、それから適切な要素を枠組みに当てはめるが、語彙が中心で語が統語構造を活性化し、語彙の符号化が統語的符号化より先行し、音韻的符号化は、これらの準備ができないと始まらない。
(鳴海)
<ディスカッション&コメント>
・なんとなく概念はわかっても、日本語での訳出が難しい箇所が多かった。
・modularは、moduleの形容詞なので、modular theoryの訳語は「モジュラー理論」より「モジュール理論」の方がいいようだ。
・2節で出てきている二方向の活性化に関して、トップダウンが文産出で、ボトムアップが発話理解であった。
・3節で出てきているsyllabaryは、英辞郎によると「音節文字表」と訳語が出ていた(第1章より)
・3節で出てきているgestural scoresは、口や舌の動きのことであろうか。
・articulatory scoreという単語の解釈が分からなかった。scoreという単語は活性化値のようなものであろうか。
・本章では2つのモデルが出てきたが、結局L2のspeakingにおいてはモジュラー理論の方が一般的だという結論になるのであろう。しかし、単語認知などではspreading activation theoryが用いられることも多いため、L2理解においてはどちらのモデルが合うのかもう少し検討する余地がある。
(森本、平井)
ページトップに戻る
2007/06/22
Chapter 2 (前半) Issues in First Language Speech Production Research (pp. 12-23)
1. Introduction
●第1章でモジュラーモデルと活性化拡散モデルについて述べたが、この二つのモデルには相違点があるが、この二つのモデルを検証し、実験に基づく有効な発話処理モデルを構築することがL1発話産出研究の主な目的である。
2. Research Methods Used in Studying Language Production
●言語産出研究における方法は3つに分類される。
(1) 観察的手法:同時的な発話の分配的分析(distributional analyses)と非流暢さ(disfluencies)および誤り(errors)の研究。
*分配的分析 → 様々な文の種類、音韻的特徴(prosodic markers)、語形、統語構造がどのくらいの頻度で起こるのかを分析。
*非流暢さ研究 → 沈黙やつなぎ言葉、言い始めの間違い(false starts)、繰り返し、言い直し、訂正の研究。
*誤り研究 → 誤りの頻度とタイプの研究。
☆利点としては、自然な状況での発話処理が見られ、発話産出が統合的な体系の中でどのように機能しているかを考察できる。
★問題点として、分類の難しさや、評価者の一貫性、書き起こしの不正確さがある。
(2) 実験的手法:誤りを引き出す(特にslips of tongueや様々な産出の単位における)。
多くの発話産出の実験は以下の2つに分けられる。
①同時的模擬実験パラダイム(concurrent simulation paradigms)…干渉(interference)とも言われる
→錯乱肢と目標語を同時に処理
* Stroop taskが代表的(目標語の絵と錯乱肢の語を同時に提示。p.14 絵の語を答えるまでの時間で測定)
②連続的模擬実験パラダイム(successive simulation paradigms)…primingと呼ばれる
→はじめに刺激(prime)が提示されてから、目標語や構造を産出する。
* 構造的プライミング実験がよく用いられる。(ある特定の統語構造を持った刺激文を提示し、その後に絵を見て文を産出。前に提示した文とどのくらい同じ統語構造を使っているかの割合が測定される)
★実験的手法は実際のコミュニケーションからは乖離している点で不利である。
(3) 神経イメージング(neuroimaging)を用いた手法:3つのグループに分けられる。
① ERP (event-related brain potential、):EEG(electroencephalogram、脳波図)を用いて記録。
② PET (positron emission tomography、ポジトロン放出断層撮影法):PET装置を用いて、脳内の領域における高血流によって見られる活性化レベルの上昇を追跡。→脳の機能の位置を探ることが可能になる。
③ fMRI (functional magnetic resonance imaging):ヘモグロビンが酸素を運搬するとき/しないときに異なる磁気信号を送ることに基づき、上昇する脳内活動を、酸素を運搬するヘモグロビン分子の増加から測る。
*fMRIが一番好んで使用されている。
3. Conceptualization and Speech Planning
●心理言語学的研究が発話プランニングに関して挙げる問題点。
(1) 発話プランニングの単位 → 節、概念、情報単位、調子単位、成句、文などの単位があるが、Levelt (1989)は、各処理レベルにおいて、異なる発話単位が用いられるため、発話単位の議論は無意味であると述べている。
↓
(2) 発話産出における時間的サイクル(temporal cycle)の存在 → 同時的な発話においては、流暢な発話とそうでない発話が交互に生じる(temporal cycles)。発話産出は準備と遂行を伴い、準備の段階では流暢さが低くなり、遂行の段階では高くなる。
*Roberts and Kirsner (2000):先行研究の方法論的問題点(時間的パラメータの不適切な指標、サイクルの分析における主観的判断、不適切な統計処理)を指摘。これらを修正した結果、同時的な発話において、流暢な発話とそうでない発話は交互に現れ、これらのサイクルは規則的で定期的であることを明らかにした。さらに、トピック構造と流暢さに強い一貫した関連があることを発見した。(新しいトピックの前に流暢さが下がり、トピック導入後に発話が速くなる。)
→マクロプランニングは準備のトピック中心の形式。メッセージに関して意識的な決定をする必要があるため、発話プランニングは注意を必要とする。そのため、通常は遅いがL1では自動的に行われるために速い。
(3) 発話前のプランにおいて概念がどのように符号化されるか → 収束の問題(convergence problem);意図する概念に当てはまる語を探す際、概念の数とレキシコンにおける語彙入力は一対一の関係ではないのに、なぜいつも選択プロセスは正しい語に収束するのか。(female actor / actress とfemale teacherの例)類語の問題(synonymy problem)や(receiveの概念とreceive / obtain / getの例)、上位語の問題(hypernym problem)もある(上位語の概念は下位語に分類されるものの概念と重なる。animal / dogの例)。なぜ意図する語彙の変わりに上位語が用いられるという間違えはあまり起こらないのか。
●feature theoriesは概念が意味的特徴のリストからなり(puppyの例)、語彙アクセスにおいて、適切な語彙が概念的特徴と適合される。
→ 語彙の抽出に成功するために、関連する概念的特徴はどのように構築されるのかという疑問。(モジュラーモデルでは、概念化装置はレキシコンへのアクセスがなく、語彙抽出の成功のための概念細目の情報を持っていない。)
*Bierwisch and schreuder (1992):分離したモジュールを提案。
→verbalizer:語彙的に関連する概念特徴を構築する処理が行われ、モジュールがレキシコンへアクセスできる。
*Levelt (1992), Levelt et al. (1999), Roelofs (1997):概念は完璧な本質(complete
entities)として捉えられるべきで、特徴のまとまりとして捉えられるべきではない。分離した概念レベルがあり、そこで語の意味が特定され、概念が語彙項目へと活性化される(Roelofs,
1997)。
●概念はノードで表される。
例) YOUNG / DOG / PUPPYのそれぞれのノードがあり、PUPPYのノードが一番高い活性化を受けたので選ばれたので、話者はyoung
dogではなくpuppyという。
●La Heij (2005):完全な類語はほとんど存在しないため、類語の問題は発話産出にはあまり関連がない。(young dog / puppyの例) 発話前のメッセージはある語を特定する全ての情報を含み、語の核となる意味だけでなく、どのくらい形式的な語が良いか、婉曲表現を使うか、タブーの語や低頻度語を避けるかなどの情報も含む。これらの情報は方言やレジスターにも拡張される。手がかりは、場面や相手の知識に基づいて設定される。(blokeの例、p. 19)
4. Lexical Encoding
●語彙の符号化において、以下の点で研究者は一致している。
・発話の3つの処理レベル→概念プランニング、語彙的符号化、音韻的符号化
・これらの処理は競争メカニズムであり、概念、語、音素のどれかが選択される。選択は項目の活性化に基づき、一番高い活性化レベルのものが選択される。活性化レベルの差が大きければ選択は速く、低ければ難しい。
・発話において、意図した概念のみならず関連概念も活性化される。(table / bed / deskの例)
●どのようにして語が選択されるのかということが問題。→ "cat"の絵に "dog"の文字がある場合、どのように話者は目標概念を言語化するのか?
(1)タスク活性化
・Starreveld and La Heij (1996), La Heij (2005):タスクの活性化(task activation)が存在すると考える。タスクが「視覚的に提示された絵の名前を挙げよ」であれば、それが文字よりも絵をより活性化する。
(2)チェック機能(checking process)
・Roelofs (1992):絵と文字の両方が活性化され、またタグが付けられる。
・Roelofs (1992), Levelt et al. (1999):語彙選択メカニズムがタスクの指示によって決定されたタグを持つ語彙入力を選び、確認メカニズムが正しい語が選択されたか確認(チェック)。
●タグ付けとチェックには問題が多い。
・La Heij (2005):このモデルは複雑すぎ、不必要なチェックメカニズムが働く。複雑なタスクではタグが増え、効率が悪い。チェック機能はLeveltのモジュラーの原理にも反する。Levelt (1989, 1999)は、一つの処理機能は一種類のインプットと機能し、他の処理モジュールとは関わらないとしている。
●(1)の案がシンプルであり、タスクの指示によって特定された側面が、パフォーマンスの成功に関連する概念の活性化レベルを上げるという仮定(Phaf, van der Heijden, & Hudson, 1990)にも支持される。
●語彙のアクセスは、連続した処理かそれともカスケード的(cascaded)処理化という問題。
→語彙の符号化は、語彙的符号化と音韻的符号化の2段階であるが、これらの処理がどのような関係になっているかが問題。
*Jescheniank and Schriefers (1997):連続モデルでは、一つの語彙の選択は音韻的活性化が始まる前にスタートするが、選択された語の音韻的な形のみが結果としてアクティブになる。意味的に関連する他の選択肢の音韻的形は活性化されない。カスケードモデルや活性化拡散モデルでは、目標語とそれ以外の意味的に関連する選択肢の音韻的活性化が起こり、音韻的な共活性化(co- activation)が生ずる。(TABLE a table / desk / bedの例)カスケードモデルでは、語彙選択は音韻的語の形式の活性がスタートする前に終わらず、語彙選択と音韻的符号化が並行して起こるとしている。
●カスケードモデルの反例:脳内活動の測定(ERP)における電気生理学的手法より
*Van Turennout et al.:参加者の脳内活動は2つの決定タスク(decision task)をやっている間に記録される。絵を見て、①有生(animate)/無生(inanimate)概念、②特定の音素から始まるかを決める。
実験1:動く概念のときに片手を上げる(動かないときは反対の手)。音韻的情報が反応するかを決定。(go/no-go condition)
実験2:どちらの手を上げるのかを決める要因となった音素を決定。
結果的に、意味的情報は、音韻的情報よりも早くに入手できることが示された。
*Rahman and Sommer (2003):似た研究で同様の結果。しかし、意味的情報が音韻的情報より先に来ることが、カスケード的活性化を不可能にはしない。カスケード処理は、語彙がはじめに活性化され、その後音韻的語形の活性化が起こると仮定し、語彙選択が終わる前に音韻レベルのまで活性化が届く。つまり、音韻的符号化は意味的な抽出が始まるのと同時に現れると結論付けている。
●L2においては、語からの活性によって意図しない音韻形が生じることから、カスケード的処理の可能性がある。また、カスケード的処理がL2のみで生じL1では起こらないとは考えにくい。
(鳴海)
<ディスカッション&コメント>
・feature theoriesとは、おそらく意味素性にまつわるもののことであろう(+ animateなど)。
・cascadeをどう日本語訳すればよいのかが難しかった。
・音韻的な共活性化とは、音韻的活性化のレベルまで達するということ(最初は意味的な活性化のみで、それよりも活性化値が高くなると音韻的な活性化も起こる?)
(森本)
ページトップに戻る
2007/07/13
Chapter 2 (後半) Issues in First Language Speech Production Research (pp. 23-37)
5. Syntactic processing
●統語的処理
⇒活性化拡散モデル:統語的規則が文の枠組みを作り、その後それが語で埋められる。
⇒モジュラーモデル:語の統語的性質が文の産出を導く。
モジュラーモデルの方が統語的な処理については詳細にわたって説明している。
●Kempen and Hoenkamp (1987)のIncremental Procedural Grammar(付加的手続き的文法?)に基づくと文法的符号化は6つの段階を持ち、文法の記憶蓄積を含む。
例) The child enters the room.
① 第一の概念的要素であるCHILDに関する語が取り出される。
② その語の統語的範疇が、その語が主部となるような句(ここでは "child"が名詞なので名詞句)のカテゴリーを形成することを通じて、分類の手続きを開始する。
③ "child"に関して、単数形で+accessibleな状態。よって限定詞ノードが名詞句ノードに付加され、
"the"が活性化される。
④ formulatorが次の文法的符号化のステップへと進む。形成されたアウトプットが主部になるのか補部になるのかが決定される。ここでは、名詞句
"the child"が文の主語になる。
⑤ 語順のルールが活性化され、主語が文の最初の位置に来るべきであることが特定される。その後に、従属節の手続きが句に従属節を付加する。
⑥ 上位の分類手続きが活性化され、語の抽出段階、又はStage 2から、メッセージに関連するものを処理し始める。ここでは
"enter"という語が次に呼び出され、句の手続きにおいて、文法記憶の蓄積より得られる情報(主語が単数形である)に基づいて、屈折の
"s"が付与される。
●語彙の選択メカニズムと統語的構築手続き( syntactic building procedure)がどの程度相互に作用するかについても活性化拡散モデルとモジュラーモデルでは異なる。
●Feed-forward theories (e.g., Levelt et al., 1999):語彙の選択は統語的フレームよりも先に起こり、この方法で構築された統語構造は、語彙の選択に影響を与えない。
●Interactive theories (Dell, 1986; Stemberger, 1985):統語的フレームは、語彙入力(語彙選択のための候補)の活性レベルを上げることによって語彙の選択プロセスに影響を与える。発話の誤りに関するデータによって主に支持されている。
例) "I switched on the light"と言いたい所を誤って"I switched
on the *sun"といった。
このような誤りの場合、代替語の品詞は同じであり、ジェンダーも同じ場合が多い。
⇒統語的フレームが、一つの文法的カテゴリーに属する語を選ぶ傾向を創っている。
●Feed-forward theoriesを支持するものとして、Vigliocco, Lauer, Damian and Levelt (2002)がある。それによると、統語的プロセスと意味的プロセスの間には相互作用はない。しかし、Vigliocco, Vinson, Indefrey, Levelt and Hedwig (2004)が実験的に様々な句構造における置き換えの誤り(substitution errors)を誘導した結果、限定詞(名詞のジェンダーにより形が決まる)の後に名詞が来る場合、誤って用いられる代替語は意図している語と同じジェンダーであることが分かった。これは統語的フレームがフレームの中に入るべき語よりも早くにアクセスされると仮定しないと可能にならない。
⇒統語的符号化が語彙の選択よりも先行しないと考えるモジュラーモデルに対する問題提起。
●句構造に注目が集まるのと同様に、文の構築に関する研究も多くある。文の構築は主に統語的プライミングと呼ばれる手法によって研究される。
●統語的プライミングの実験:一文(prime)において一つの統語構造を用いることが、他の文でも同じ構造を用いる傾向を増大させる(priming effect)。
例) "The lightning struck the church" a(絵を見せて) "The dog chases the cat"
"The church was struck by the lightning" a (絵を見せて)"The
cat is chased by the dog"
この実験では統語構造の類似がpriming effectを生み出す。primeと目標の間の語彙、語幹(thematic)、韻律(metrical)、音韻の類似はprimingを引き出していない。
⇒一つの統語産出の規則が似たような規則を活性化する。つまり、統語的符号化において、活性化拡散モデルのメカニズムが働いている。
●問題は、どのようにこのシステム内で活性化が拡散するか。活性化拡散モデルのように、一つの統語フレームから他の統語フレームに拡散するのか? それともモジュラーモデルのように、語彙中心の統語的符号化の枠組みの中で活性化が起こるのか?
●統語的プライミング実験の延長として、参加者が前に提示された文をリコールする。その結果、彼らは文の要旨を覚えており、一番最後に使用した語を用いて文を再生していた。(primeであるgive + NP + NPと錯乱肢であるdonate + NP + to NPの例、p. 25)⇒この結果は統語的符号化が語彙中心であることを裏付けるものである。一番最後に活性化された統語構造ではなく、最後に活性化された語を用いているから。
●統語情報と音韻情報へのアクセスの順序についての問題。多くの場合は、ジェンダーの符号化と音韻処理の関係を検証する。
●Leveltの支持者は、文法的ジェンダーは名詞の語彙・統語的(lexico-syntactic)性質であり、形態・音韻的(morpho-phonological)性質によって導かれるものではないと主張。性を与えられた全ての名詞について一つの抽象的なジェンダーノードがある。(ドイツ語の例、p. 26)
●文法的ジェンダーは常にアクセスされるのか、それとも必要なときだけか。また、ある語のジェンダーに関する情報は、その語の音韻形式に関する情報よりも先に入手されるのかという問題。
・Bock and Levelt (1994):語の音韻形式は、語彙・統語的性質がアクセスされてか選ばれる。
⇒Caramazza (1997)により "syntactic mediation hypothesis"(統語的媒介仮説?)と呼ばれる。語の統語的情報(ジェンダーなど)は、常に音韻的符号化より前に活性化される。しかし、Bock
and Leveltはこの情報は常に選択されるわけではなく、ジェンダーの情報が必要ない場合もあると主張。(ドイツ語の中性名詞、Kinderの例、p.
26)
●Caramazza and Miozzo (1997):喉まで出かかる(tip-of-the-tongue)状態のとき、イタリア語話者は、語を産出できないにも関わらず、語のジェンダーと最初の音素を正確に伝えることができる。⇒概念的表象が語の音韻表象を直接活性化し、語彙・統語的情報が、音韻的符号化と並行して進行している。Independent network modelでは語レベルを分離する必要はない。
●van Turennout, Haggort and Brown (1999):参加者の脳の活動をみることで、語の文法的ジェンダーは音韻形式よりも早くにアクセスされることが示された。
6. Phonological Encoding
●3つのモデル
① Featural theories(活性化拡散モデルと関連):音韻的部分はそれらの特徴によってのみ表象され(例えば[b]は、+有声、+両唇、-鼻音)、音韻プロセスでは、形態素はその音を構成する特徴の上に位置づけられる。
② Segmental theories(モジュラーモデルと関連):音韻的部分は、それらの独自の抽象的表象(特徴のまとまりとして蓄積された)が記憶の中にある。
⇒Roelofs (1999):implicit primingとコンピュータシュミレーションを用いた実験。まず参加者は語のペアを学習する。一つの語が視覚的に提示されたら、ペアのもう片方の語を産出する。二つの異なるセット(homogenous set:一部の形式が同じ、heterogeneous set:形式に類似がない)の語が使用される。反応時間を計測した結果、類似している語のほうが応答が早かった。
また、homogenous setの中でも、最初の音が同じ語(table, tennis, token)と、音は似ているが一つの特徴は異なる語(door, table←有声・無声だけが異なる)を比べたとき、後者は影響がない。つまり音素はチャンクとして蓄積、抽出される。
③ WEAVER (Word form Encoding by Activation and VERification) model:活性化拡散とLevelt (1992)のonline syllabification(音節に分けること?)をあわせた音韻的符号化の包括的モデル。このモデルは、音節のチャンクを用いる代わりに、音節化(syllabification)を算出し、オンラインの音節化処理は隣接する形態素や単語も考慮に入れる。
例) "I've seen him" の "I" "have" a [aiv]
音素やストレスの位置が音節化プロセスのインプットとなり、音素は、語の初めの音素から最後の音素まで、連続して活性化される。音素の位置は言語の音節化の規則にしたがって決められる。⇒母音や二重母音は異なる音節ノードが与えられ、子音は音素配列の例外でない限りは、onsetとして考えられる。
例) "tiger"の[t]は最初の音節の初めに位置し、[ai]は第一音節の核になり、[g]は第二音節の最初に位置し、[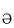 ]はその核となる。
]はその核となる。
●音声的符号化では韻律の表象が、声の大きさ、ピッチ、長さなどのパラメータを設定するのに用いられ、その仕組みは発声行為をコントロールするために利用される。
●このモデルは、付加的な産出を仮定し、インプットの断片が産出を引き起こすのに十分であると考える。韻律構造があれば、最初の音素で音節化がスタートする。音節化プロセスの合間は次の部分の準備ができるまで弱くなる。( [tai]・[g] )
●発生段階においては、モータープログラムが音節文字表(syllabary)から取り出される。発声行為(唇を丸める、顎を下げる)がなされるために、音節はスコア(score)のまとまりとして作られる。スコアは同様にジェスチャーとそれらの一時的関係を特定する。音の同化(assimilation)は、ジェスチャースコア(gestural score)が重複した結果。
●このモデルでは活性化拡散は、それぞれのノードが隣接するノードに活性化を拡散することで、同時にその活性が減少し、前に進むのみである。(p. 29, Fig. 2.7.)
7. Monitoring
●フィードバックとモニタリングにおいても活性化拡散モデルとモジュラーモデルは異なる。
●活性化拡散モデル:自分の発話をモニターするときも、活性化のボトムアップの流れが起きている。モニタリングは、知覚や産出プロセスの内在的特徴であり、モニタリング装置が別に存在することは仮定されない。
・問題点⇒誤りが自動で検知されたとき、モニターは全ての誤りを認識し、全てが自動的に修正されるはずである。しかし、話者は全ての誤りを直すわけではない。
⇒MacKay (1992):node structure theory (NST)という気づきの研究に基づく仮説。全ての誤りが自動的に検知されても、誤りを修正するかどうかは意識的に決められる。
●Editor / production theories of monitoring:エディターが発話の誤りを抑止したり訂正したりする。しかしそのエディター能力がどこから来るか、どこにあるかは疑問。⇒エディターはアウトプットをチェックする独自の規則体系を持つのではないか。
⇒Baars, Motley and Mackay (1975), Motley, Camden and Baars (1982):発声前エディターが、発声する前に語彙判断、統語的・意味的適切さ、文脈、社会的適切性に基づき、発話内容を検査しているというモデルを提案。しかし、このモデルが完全に適用されると、全ての誤りは起こらなくなってしまい、現実的でない。
●現実的には、規則体系が退化したり、用いられる規則が変化すると考えなければならない。ある規則の適用は、文脈や注意力による。しかしこのモデルではエディターは処理の成果を点検するだけで、途中段階でのアウトプットの誤りを抑止できない。さらに発話前の適切さを決めるのに必要な情報はエディターにおいて反復され非効率的。
●Production theory of monitoring ( production-based monitoring / PBM):処理体系のそれぞれのレベルに特化したモニターがあるのではないか。モニターは産出の異なる段階にアクセスできる。しかし、モニターは処理要素と同等の知識を備えていなければならない。また、モニターがどのように操作されるのかは明らかでない(それぞれの段階で発話産出プロセスが止められると仮定すれば、処理速度がかなり下がる)。
●Perceptual loop theory (PLT):Levelt (1983, 1989)が提案。エディター理論に基づき、発声前のアウトプットは点検される。活性化拡散と同様のメカニズムが、話者が自分のメッセージをチェックするのに適用される。知識の重複を避けるために、このモデルでは、発話理解システムが適用され、話者は他者の発話だけでなく、自分の発話にも注意していると考える。
●PLTにおけるモニタリングの3つのループが用いられる。
(a) 概念的ループ:発話前のメッセージが話者の最初の意図と比較される。(文脈におけるメッセージの適切性)
(b) 発声前ループ:音韻的処理の成果がチェックされる。(符号化の誤りが発話前に抑止)
(c) 外在的ループ:発話されたメッセージが説明される(parsed)。(コミュニケーションにおける適切性と発話の言語形式の両方をチェック)
●Levelt (1989, 1993):音韻的符号化の3つの段階
(a) 音韻的断片(segment)の活性化
(b) 音韻的語の産出
(c) 音声・発生プランの生成
●Wheeldon and Leveltは話者は、音声・発声プランにアクセスしなくても自分でモニターできると提案。発声前のモニタリングは、音節構造に敏感である。話者は音声・発声プランが符号化される前に、抽象的な音韻的表象の段階でモニターすることが可能。
●まとめ⇒p.32, Table 2.1.を参照。
●最も検証されているのがPLT。話者が自分たちのいっていることを聞いていないのに、誤りを検知できることから支持される。問題点としては、間違いを検知する際の発話の妨げと修正プロセスの間がとても短い点がある。中断と修正は並行して起こっているのではないか。
8. Neurological Studies of Language Production
●Indefrey and Levelt (2000, 2004):一つの領域(左中側頭回)が、語の産出や絵に語をあてるタスクの際に活性化された。しかし、単語を読むタスクのような、概念の選択を伴わないタスクの際は活性化されない。⇒左中側頭回は概念が関係する語彙の選択の際に働く。
●メッセージの概念化は脳の異なる分野でなされているが、タスクタイプ別に特定するのは難しい。
●音節化の段階では、ブローカ領域が使われる。
●音声的符号化や発声は、12のcentral nervous motor systemが関連している。
●神経イメージングの研究により、PLTのモニタリングが支持された。(話者は他人の発話だけでなく、自分の発話にも注意している)
●脳の領域研究の問題点:一つの語を処理するタスクに偏る。熟達度の高い学習者と低い学習者や、L2を頻繁に使用する/しない学習者を比較する研究がない。
●Abutelabi et al. (2001, 2005) :L1 / L2において処理に関する脳の活性化の程度や領域は、L2を早期に学んだバイリンガルとL2に多く触れた熟達度の高い話者ではあまり変わらない。
(鳴海)
<ディスカッション&コメント>
・プライミングの実験の部分で、音韻の類似などはプライミングを引き出さないとあるが、語彙の反応時間のプライミングなどでは、音韻の類似についてもプライミングが起こることが多い。今回は、絵を描写させる際のプライミング課題であるため、同じプライミングであっても種類がかなり違うので注意が必要であろう。
(森本)
ページトップに戻る
2007/07/26
Chapter 3 Theories of Automaticity and Their Relation to Speech Production Models (pp. 38-51)
1. Introduction (pp. 38-39)
●母語において自分の言いたいことを言語的に符号化することが、最も複雑な活動の一つである。
●言語産出における自動化の研究の問題点
① 「自動化」が意味するところが研究者の間で異なり、その結果自動化がどのように発達しているかに関して意見の食い違いが生じる。
② 言語産出は異なったタイプの符号化プロセス(規則を用いるものと、記憶された語彙を引き出すもの)を持つため、それらに応じて異なる自動化の理論が適用される可能性がある。
③ L1 / L2習得の研究者の間において、言語習得を他のスキルの習得と類似したものと捉えるのか、それとも言語習得が他のスキルとは異なる独自の認知プロセスであると捉えるかに意見が分かれる。
④ 発話産出と自動化の研究は認知心理学において異なる分野であるため、スピーキング処理の自動化を研究したい場合は、未知の領域に踏み込まなければならない。
2. Definitions and Characteristics of Automaticity (pp. 39-40)
●様々な「自動化」の定義がある。
●DeKeyser (2001):1974~1993の心理学の分野で提案された、14の異なる自動化の基準をまとめる。それらの特徴には以下の点が含まれる;速い、平行的
(parallel)、労力を要しない(effortless)、容量無制限(capacity-free)、非意図的、一貫した練習の結果、他の処理の干渉が少ない、無意識的、誤りがなく柔軟、厳しい産出規則、ワーキングメモリからの干渉がない、パフォーマンス基準において平均と標準偏差の間に相関がない。
●1970~80年代には、自動的処理とコントロールされた処理は二項対立的に捉えられていた。
自動的処理⇒ 速くて効率的、短期記憶に制限されない、話者の労力を要しない、意図的にコントロールできない。
コントロールされた処理⇒ 遅くて非効率的、短期記憶に制限される、話者の労力を要する、話者によってコントロール可能、柔軟、部分的に反省の余地がある。
●Schneider, Dumas and Shiffrin (1984):多くの基準は不要であり、自動化の重要な特徴は2点⇒ 処理の容量と注意を必要としないという点
●Kahnemann and Treisman (1984):自動的処理とコントロールされる処理は二項対立ではなく、異なる程度の自動化がある。
●1980年代半ば頃より自動化に関する2タイプの考え方
① Rule-basedアプローチ:自動化は宣言的知識(declarative knowledge)を手続き的知識(procedural
knowledge)に変換させること。どの程度の注意が処理に払われているかに注目。
② Item-basedアプローチ:自動化は記憶されたことに一回でアクセスできる(single-step
access)こと。記憶に基づく検索(retrieval)が中心)。
●N. Segalowitz (2003):過去30年の実証研究より次の特徴を挙げる;速い、弾道的/止まらない(ballistic)、負荷から独立(load-independent)、労力を要しない、無意識的。
●自動的処理はコントロールされる処理よりも一般的に速いが、自動化の発達は量的な変化だけではない(
Sheffrin & Schneider, 1977)。また、自動的処理が常に負荷から独立したものであるという仮定は十分に支持されなかった(
Schneider & Shiffrin, 1977; Shiffrin & Schineider, 1977)。
●自動化の研究より、自動的メンタルプロセスは弾道的であり( Neely, 1977)、労力を要せず(
Posner & Boies, 1971)、無意識的である( Jacoby, 1991)ことが分かっている。
3. Theories of Automaticity (pp. 40-44)
●大きく分けて2つの理論がある:
① Rule-basedアプローチ⇒ 自動化を宣言的知識から手続き的知識への変換と捉え、この変換がどのようになされるかを説明しようと試みる。
例) a / anの冠詞の使い方の違いを学習したとき、最初は宣言的知識として蓄積される。練習とともに意識しなくても使えるようになり、手続き的知識になる。
② Item-basedアプローチ (上の説明参照)
●ACT(adaptive control of thought) / ACT-R(adaptive control of thought-revised)理論(Anderson,
1983):自動的処理の発達は量的変化(速度増)だけでなく、質的な修正を伴う。自動化の発達に寄与するものとして、次の5つの学習メカニズムが存在する;composition,
proceduralization, generalization, discrimination, strengthening。
① Composition:処理のより小さな単位からmacro-productionを作る。
⇒チャンキング(ワーキングメモリにおける処理を促すためによりアイテムを大きな単位に変換させる心理的プロセス)
例) 電話番号246192236を一桁ずつではなく246-19-22-36とチャンクにして覚える。
② Proceduralization:宣言的知識を取り除き、全体(まとまり)としての産出を生み出す。一度自動化されると、はじめにあった宣言的知識はもう取り出されない。
例) L2学習者が最初に現在完了が用いられる場面を明示的に教えられるが、規則が自動化した後は、規則を正確には思い出せない。
●手続き的知識における質的な変化は、次の3つのtuningプロセスとともに生じる。
③ Generalization:産出に必要な宣言的知識の適用範囲を広げ、産出規則が当てはまる全ての文脈に適用されることを確認。
④ Discrimination:適用範囲を狭め、適切な文脈においてのみ規則が適用されるように気を配る。
⑤ Strengthening:良くない規則を弱め、良い規則を強める。
●再構築モデル(model of restructuring):あるタスクの実施が向上するのは、タスクの構成要素が再構築されるからである。パフォーマンスの速さは、処理のスピードアップによるだけでなく、再構築してできた新しいメカニズムの創出にもよる(Cheng,
1985)。
●N. Segalowitz and S. Segalowitz (1993); S. Segalowitz, N. Segalowitz
and Wood (1998):自動化の発達は処理のスピードアップだけではなく、タスクの構成要素において質的変化が起きるからである。練習の初期は学習者のパフォーマンスは多様で非効率だが、あるスキルが発達すると処理はより効率的で間違えの傾向が少なく、多様性も低下する。
●Competitive chunking理論:産出が互いに追随しており、目標が類似している場合、古いメカニズムの単位を壊すことで古いものから新しい産出を構築すると仮定(Servan-Schrieber
& Anderson, 1990)。Newell (1990)は、1つのメカニズム(チャンキング)は学習、産出理解を含む認知の基礎になると仮定。
●Newell (1990) and Newell and Rosenbloom (1981):チャンク構築の3つの基礎プロセス
① 一定速度でチャンクをつくり、経験とともにチャンクを追加。
② タスクのパフォーマンスは関連したチャンクが作られるとスピードアップする。
③ 高レベルのチャンクは低レベルのチャンクよりも生じる頻度が低いため、利便性が低く学習も低速化する。
●Instance理論(Logan, 1988):全ての学習が宣言的から手続き的な学習への変換を伴うわけではない。自動的処理は記憶の抽出と同じである。つまり問題を解くための操作が記憶から一回で解法を引き出すことに取って代わられる。問題が繰り返し解決されることでそれが一つの単位として構築され、必要なときに呼び出される。練習によってこの処理の速度は上がる。Loganの3つの重要な仮定:
① 記憶における符号化は、注意による必然的な結果。つまり、人は注意を払うもののみを符号化する。
② 記憶からの抽出も注意の必然的な結果。
③ 刺激による接触(encounter)は別々に符号化され、蓄積され、抽出される。
例) 6×3を考えるときに、6+6+6のプロセスを経るが、練習により18という解が記憶より取り出されるようになる。記憶の抽出は、計算を用いるよりも速くなった時に生じる。
●Strength理論:応答と刺激のつながりは練習の結果強くなる(MacKay, 1988)。自動化プロセスは柔軟で、練習により自動化された低レベルのタスクが高レベルに転移される。低レベルの例の練習が高レベルの自動化スキルを発達させるためには不可欠。
●Power law of practice(練習の指数法則):初期の練習はパフォーマンスをかなりスピードアップさせるが、ある段階を過ぎると反応時間における練習の効果は減少し、最終的にはパフォーマンスの限界に達し、練習の影響がなくなる。Rule-/item-basedアプローチは両方ともこの学習曲線を正確に予測した。
●Instance理論の限界点:同一の刺激でないと記憶の抽出のきっかけとならない。ある解法を新しい場面に一般化することはできない。
従来のRule-basedアプローチの限界点:ある場面においては解法が記憶されており、規則の産出が記憶からの直接的な抽出によって代わられるという事実を考慮していない。
●Exemplar-based random walkモデル(Palmeri, 1997; Nosofsky & Palmeri,
1997)):基本的にはitem-basedモデル(記憶処理が中心)だが、入ってくる刺激と他の範疇の刺激を比較し、目標範疇からと他の範疇からの応答が互いにcompeteすると仮定。伝統的なitem-basedと異なり、少しrule-based寄りになる。
4. The Role of Theories of Automaticity in L1 Learning and Speech Production (pp. 44-48)
●L1の発話産出研究において自動化の理論と発話産出を結びつける試みは少ない。
●Towell, Hawkins and Bazergui (1996):上級フランス語学習者の流暢さの発達に関して、量的かつ質的な調査の結果、Anderson
(1983, 1995)で提案されたproceduralizationはLeveltモデルのモジュール形成において生じる。
●発話産出における自動化を議論する際、言語学習がrule- / item-basedのプロセスか、また言語産出が主に創造的か、記憶によるものかを考える必要がある。
●Pawley and Syder (1983):発話のほとんどは、統語的な規則に従い単語ごとに形成された文から成るのではなく、一つの単位として記憶から抽出された語や句の連続(定型言語:formulaic
language)であるとする。発話産出は主に記憶によるプロセスである。
●心理言語学の先行研究における発話産出モデルの問題は、定型言語がどのように蓄積され抽出されるかについて議論していないことである。
●定型的知識が蓄積されうるのはレキシコンである。定型(formula)とは単一の単位で蓄積され取り出される言語の単位である。
●心理言語学的見地から定型表現の用法には2つの側面がある。
① どのように定型が取り出されるか。
② メッセージの統語的符号化においてどのような役割を果たしているか。
●定型には異なるタイプがあり、発話産出理論が何を仮定してもどのように語がアクセスされるかはこれらの定型のタイプに当てはまる。
●抽出に関する問題は、語用論的な長い構造の表現(謝罪、要求など)。母語話者が
"I regret to tell you"を統語的規則に基づいて構築するのではなく、一つの単位としてレキシコンから取り出すのはなぜか。
●チャンキングや意味の大きな単位の構築は概念的レベルで起こる。
●La Heij (2005)に基づくと、ほとんどの語用論的機能は一つの単位として概念化され、形式的な度合い、スタイルなどのレベルに関しての細目も含んでおり、これらの概念的な単位が語彙アイテムを活性化すると仮定できる。
●定型表現の統語に関しては、モジュラーモデルでは、定型表現は他の語と同様に統語的情報の様々なタイプを提示し、この情報が統語的符号化に用いられる。
●定型表現の習得は自動化のチャンキング理論とinstance理論の両方で説明される。
●Law of contiguity(連続の法則)(James, 1890):一度一緒に経験された複数のものは、頭の中でまた一緒に連想される傾向があり、その中の何かについて考えたときに他のものも一緒に考えられる。
⇒ つまり、一緒に生じる語彙項目はチャンクを形成する傾向があり、ある概念細目がそれらを必要とするとき、一つのまとまりとして取り出されると考えられる。
●LoganのInstance理論は、言語学習の初期には規則の適用の方が記憶の抽出よりも速く、練習するにしたがって記憶抽出のスピードが規則に基づく処理よりも速くなり、定型表現が記憶から一つのまとまりとしてアクセスされると考える。しかし、この理論では全く同じ刺激(それはめったに生じない)でないと記憶が抽出されないとするため、言語産出に必要な柔軟性に欠ける。
●Instance理論を新しくしたExemplar-based-random-walkモデルでは、同一でなくても刺激が類似していれば記憶抽出が可能であるとしている。
子どもがL1においてどのように定型言語を獲得するかはチャンキングとinstance理論の両方から説明される。
●Peter (1977):子どもはL1学習において2つのストラテジーを用いる。
① 全体論的(wholistic/ゲシュタルト的学習者は、習得プロセスの初期には未分析の一連の文章を使い、後にチャンクから抽象的な言語規則を用いる。
② 分析的学習者は、最初の段階から単語で発話を構築し、簡単な規則を適用しようとする。
⇒ 定型表現は、最初に規則に基づき後にまとまりとして記憶される、未分析のチャンクや句として習得されるのではないか。
●語彙的符号化の自動化:概念と語の結びつきが強くなり、検索メカニズムが一回の抽出で直接的になされるようになる。
Memory strength理論/connectionism(結合説):MacKay (1982)は、言語のような段階的ネットワークの中でのノード間(ここでは概念と語彙項目)の結びつきは、練習によって強化される。ここでの自動化は、あるノードが活性化されたとき、自動的の次の関連するノードが活性化されるということを意味。
⇒ 語彙アクセスの自動化とは、あるインプットにより概念が活性化されたとき、関連する一番高いレベルの語彙ノードを自動的に活性化すること。
●統語的/音韻的符号化の自動化:規則の適用(句や節など)に基づくメカニズムと、語彙入力の統語的音韻的情報の活性化に基づくメカニズムを区別する必要がある。
●統語的/音韻的情報の選択は語彙アクセスと似ていて、語彙抽出の自動化の考えが適用される。Strength理論に基づくと、語彙と関連する統語情報(ジェンダーなど)、語彙と音韻的形式の間の結びつきが強くなることで、検索メカニズムが必要なくなり自動化が起こる。
●Rule-basedモデルのACT / ACT-R理論に基づくと、統語規則の自動的適用はproceduralizationの結果であり、つまり意識的に獲得された統語的知識が自動的な産出規則へと変換されることである。proceduralizationは、符号化プロセスの速度アップだけでなく、generalization
/ discrimination / strengtheningのようなプロセスの適用における質的な変化も生じると考える。
●チャンキング理論/Connectionismに基づくと、統語的規則はproceduralizationを通じて学習されるのではなく、多数の原型(exemplar)を習得し、それらの項目から言語規則を概念化することによって学習されるといえる。この考えは、文法習得のコンピュータシュミレーションによって支持されている。(関連のある学習プログラムが大量の言語インプットを受けると、一緒に生じる項目の可能性を分析することから、統語的/音韻的規則を概念化することができた。)
●音韻的規則における自動化の研究はないが、統語に関するものが適応できるのでは?
(鳴海)
*ディスカッション&コメント
Theories of Automaticityには、大きく分けて2つの理論、
①Rule-based アプローチ
②Item-based アプローチ
があるが、ACT( adaptive control of thought )が上記①、②のいずれであるかが不明。
全ての学習が宣言的から手続き的な学習への変換を伴うわけではなく、自動的処理は記憶の抽出と同じであるとする、Instance 理論(Logan, 1988)は、Item-based アプローチである。
(多尾)
ページトップに戻る
2007/08/24
Chapter 4 Lexical Encoding and Bilingual Lexicon (pp. 55-67)前半
1. Introduction (pp. 55-56)
●バイリンガルの言語産出において、語彙のプロセスは大変重要である。語彙知識は第二言語のコミュニケーションにおいて不可欠であり、語彙のレベルにおいてL1/L2の相互作用のレベルは最も高い。またモジュラーモデルに基づくと、語彙の符号化が発話産出において中心的な役割を果たしている。
●本章では、L2産出における語彙の符号化、語彙アクセスのメカニズム、語彙選択の流れ、バイリンガルレキシコンの体系について議論する。また語彙レベルでのコードスイッチングや転移、語彙習得に関する心理言語学的メカニズムについても述べる。
2. Lexical Activation and Selection in L2 (pp. 56-64)
●コミュニケーションに用いられる言語は、概念化の段階で選択される。Levelt (1989,1999a)モデルでは、この段階はコミュニカティブな場面に関する情報が入手可能で、与えられた場面にどの言語が適切かを決める段階である。
●語彙の選択について議論する際、活性化と選択を区別することが重要である。概念レベルにおいても、語彙レベルにおいても活性化されることと選択されることは異なる(TABLEの例, p. 56)
●L2の語彙的符号化の研究において、概念システムは意図している言語の語彙だけを活性化するのか、それとも意図していない言語の語彙も活性するのかという問題がある。以前は、活性化は意図した言語においてのみ拡散すると考えられていたが、最近の研究ではそれが否定され、新しい研究の多くは、概念システムはL1/L2の両方で活性化されることを明らかにしている。
●Poulisse and Bongaert (1994), Poulisse (1999):オランダの英語話者の言い間違い(slip of the tongue)の研究。多くの言い間違いはL2の訳語となるL1の語彙であった。
●Hermans et al. (1998):オランダの英語話者を対象に、絵を見てそれをL2で描写する。その際絵に書かれた錯乱語(英語またはオランダ語。意味的または音韻的に絵と関連性があるか、または関連がない)は無視する。錯乱語がオランダ語(e.g., dal-[vally])で、またその語が目標語(mountain)に対応するオランダ語(berg)と関連がある場合、 "berg"と "mountain"が競争し、関連のない錯乱語を用いた場合より選択が遅くなった。(Fig. 4.2., p. 59)
●L1産出では、絵と意味的関連がある錯乱語がある場合は、発話が遅くなることが知られている。
○Semantic interference ⇒意味的に関連する語が他の関連語の活性化レベルを高めるため、目標語と関連語の活性化レベルの差が小さくなることで選択により時間がかかる。(Fig.
4.2., p. 59)
●L1産出では、絵と音韻的関連のある錯乱語の場合は、語彙の選択を円滑にする。
○Phonological facilitation effect ⇒音韻的に関連する語が目標概念に活性化を拡散することで、目標語彙と意味的に関連する他の語彙の活性化レベルの差を広げ、選択が容易になる。(Fig.
4.1., p. 58)
●Colome (2001):phoneme-monitoringタスクの結果、語彙の符号化においてL1/L2両方が活性化されると結論付ける。
●Costa et al. (2000):言語にまたがってphonological facilitationが生じる。カタランとスペイン語のバイリンガルが絵を描写する。絵を表す語は両方の言語の語と音韻的に類似しているものと、どちらにも類似していないものを用いる。その結果、両方の言語が活性化されれば、前者(類似あり)の語の発話がphonological facilitationの影響で早くなるという仮説が支持された。(Fig. 4.3., p. 60)
●様々な言語を用いた研究から同じ結果が導かれたことから、概念的システムは2つの言語(選択された言語/されない言語)両方において語彙項目を活性化することが明らかになった。
●両方の言語が活性化されるということは、活性化された語は全てその後のプロセスの選択対象となることが考えられるがそういうわけではない。どのように活性化された語が選択されるのかについては2つの見方がある。
① Non - language - specific selection:言語に関わらず、全ての語が後のプロセスのために考慮される。
② Language - specific selection:意図された言語内の語のみが選択の候補となりえる。
Non - language - specific selectionを支持する研究
●Herman et al. (1998)とColome (2001)は、語彙の符号化においてはL1/L2の語彙が活性化されるだけでなく、選択においても両者が競い合うことを明らかにした。
●Poulisse (1999)も同様にL1/L2の語の部分を混ぜ合わせて新たな語を生むことが、L1/L2の語の両方が選択のために競っていることを裏付けるとしている。
●Lee and Williams (2001):言語スイッチングと語彙選択の関係についての研究。参加者は、3つの異なる定義の後にそれぞれの語を挙げる。その後、2枚の絵に当てはまる語を挙げる。定義と絵の語が関連する場合としない場合がある。英語とフランス語のバイリンガルが英語の定義に英語で答え、絵の語は英語またはフランス語のとき、L2産出におけるL1/L2の語彙選択の間には競争があり、それが意味的に関連のある英語とフランス語の語の対においては産出が遅くなることが分かった。(Fig. 4.4., p. 61)
Language - specific selectionを支持する研究
●目標語を表す絵の上に錯乱語(目標語の訳)が書かれているという形式の実験結果に基づく。
●前の実験では意図しない言語の訳語は産出されるべき目標語と競い合うことになり、産出が遅くなるという結論であったが、これらの実験では全て、訳語が産出を促す結果になった。⇒ translation facilitation effect
●Costa and Caramazza (1999) and Costa et al. (1999):語彙選択はnon-language-specificであるので、例えば英語とスペイン語のバイリンガルの場合、 "bed"はスペイン語の "cama"も活性化する。しかし、意図しない言語の語彙は競争に入ってこないので、語彙の選択が容易になる。(Fig. 4.5., p. 63)
●Costa, Colome, et al. (2003):Hermans et al. (1998)の追実験をし、異なる熟達度においても同じ結果が得られるか検証した結果、同様の結果(意図する/しない言語において競争がある)。
●この競争がどこで起こるのかが問題である。
*Hermans et al. (1998) and Lee and Williams (2001):語彙ノードがお互いに争うのではないか。
*Costa, Colome et al. (2003):音韻レベルで競争が生じ、語彙選択においては意図しない言語の語彙は考慮されないのではないか。
⇒ この考えは、語が活性化されないのに音韻レベルでその語が活性化されることはないので、不可能である。
●Hermans (2000):参加者が訳語と絵を同時に見たとき、符号化されるべき概念が二つのところ(文字と絵)から活性化を受ける。これが概念の選択を語彙レベルでの競争を補う程速くする。概念選択の加速が、意図しない言語の干渉によって語彙選択が遅くなるのを上回ることで、facilitationの効果が見られた。
●先行研究をまとめると、non-language-specific selectionの仮説の方がlanguage-specific selectionより立証されている。
3. Control in Lexical Encoding (pp.64-67)
●語彙の符号化においてL1/L2の両方が活性化されることが分かったが、バイリンガルがいつも場面に適切な語彙を用いて、ほとんど意図していない言語の単語を使わないのはどのようにして可能なのか?語彙レベルでの意図的なコードスイッチングがなされるのはどうしてか?語彙レベルでの言語の混合(blend)が起きるのはなぜか?という疑問がある。これらを考えるには語彙の符号化のコントロールについての説明が必要であり、それには2つの視点がある
① Language - specific vs non - language - specificの視点
② Complexity of the access and selection mechanismの視点
●Language - specific selectionモデルでは、語(lemma)が言語標識(language tag)をもっていると仮定し、語彙概念はlanguage - specificであるとする。
●Costa (2005):スペイン語と英語のバイリンガル話者はDOGとPERO(犬)において異なる語彙概念を持っており、英語を話すときはDOGの概念が活性化し、英語の標識を持つ "dog"が導かれ、点検(checking)メカニズムが選択された語彙と意図した概念があっているか確認する。⇒ コントロールプロセスの"simple access and complex selection" のタイプの例である。
●語彙符号化に点検メカニズムを含める問題点
⇒ メカニズムは選択をコントロールするための知識をどこから得ているのかが不明。
⇒ 異なる概念表象が全てのL2の語に対して存在すると考えることは、メンタルレキシコンの体系の分野での結果に反する。
⇒ Language - specific selection仮説は、語彙符号化の分野の多くの結果を説明できない。
●Non - language - specific selectionモデルにおいては異なる視点。
●抑制メカニズム(inhibitory mechanism)の存在: "simple access and complex selection"のタイプ。代表的なのがD. W. Green (1998)のInhibitory control (IC)モデル。
●Inhibitory control(抑制コントロール)モデル:メッセージの概念表象が生じ、概念プランがレキシコン、そして言語プロセスをコントロールする注意システムへと活性化を拡散する。これはsupervisory attentional system(SAS)と呼ばれる。
●Green(1998):発話がなされるとき、異なるタスクスキーマが活性化されると指摘。SASはタスクスキーマの活性化をコントロールする。例えばL2で絵を表さなければならないとき、SASが適切なタスクスキーマを活性化し、それがさらに言語タグを付与されている語彙レベルと活性化を拡散する。意図される言語/されない言語の両方の語彙が活性化されるため、タスクスキーマがL2の語彙の活性化レベルを上げ、またL1語彙の選択を抑制する。タスクスキーマは注意システムによって監視されているため、話者は使用されていない言語を抑制するために意識的な労力を要する。
●Greenのモデルを検証。タスク遂行中に言語を切り替え、その切り替える時間で切り替えの労力を測定した。熟達度の高いバイリンガルの場合、L2で話しているときにL1を抑制する方が、その逆よりも労力を要するという仮説が立てられた。
*Meuter and Allport (1999):数字を用いてL1a L2とL2aL1の切り替えの実験の結果、後者の方が労力を要することが分かった。
*Lee and Williams (2001):L2を話しているときにL1は強く抑制されているが、L1を話しているときは、L2は少し抑制されている、もしくは抑制されていない。
*Green (1998)によると、語彙選択をコントロールするのに必要な注意力はタスクにも依存する。
例 ⇒ 簡単なL2 picture - namingタスクでL1を抑制する方が、Stroopタスク(L2で発話するとき、錯乱語がL1で、絵にもL1が印刷されている)よりも楽である。
●ICモデルは、熟達度が上がるにつれて、意図しない言語の抑制は難しくなると仮定する。L2の使用頻度が上がるほど、L2の語の活性化レベルの保持が高くなり、L1/L2の保持レベル(resting level)の差が小さくなるので、より熟達度の高いバイリンガルの方がL1を抑制するのに多くの労力がかかる。
●Greenのモデルの問題点
*L2の能力が上がると、パフォーマンスをコントロールするために必要な注意力も減少する(Meuter
and Allport, 1999)。
*Greenは抑制メカニズムの領域を特定していない。語彙のレベルで抑制されるのか、音韻レベルで抑制されるのか、また両方なのか、が明らかでない(Kroll
and Tokowitz, 2005; Costa, 2005)。
*意図されない言語の語の音韻的特徴も活性化されており、それは活性化が拡散されるもととなる語彙ノードが抑制されると説明できなくなる(Costa, Colome, et al., 2003; Kroll et al., 2000)。
*L1/L2の語彙の並行的な選択を認めていないので、2言語の語彙の混合(blend)も抑制モデルでは説明できない。
*抑制はL1産出では見られず、L2の符号化理論を不必要に複雑化してしまう。
●発話前の(preverbal)メッセージが適切な語を引き出す必要な情報を全て持っていると仮定するのが一番シンプルな考え方である。⇒ complex access, simple selection
●Poulisse and Bongaerts (1994):発話前メッセージは概念細目に加えて、言語手がかり(language cue)をもっており、語彙も同様に言語標識をもつ。語彙選択はその概念細目と言語手がかりを適切な語彙と合わせることである。(L2を使いたいときはL2の言語手がかりがL2の語を活性化し、L1の語をL2の発話に挿入したいときは、対応する語の概念の言語手がかりを変換する。意図しない発話は、言語手がかりが誤ってしまう、または偶然的に意図しない語彙の活性化レベルが高くなってしまうということ)
●La Heij (2005):言語手がかりは概念レベルで存在すると考えることで十分。使用中の言語の語彙はそうでない言語の語彙よりも高く活性化されているから。使用されている言語の語は、頻繁に用いられることで、活性化レベルが高く、選択を容易にしている。
●Poulisse and Bongaerts (1994)とLa Heij (2005)の相違点は、前者は語彙が言語標識を持っている、後者は言語手がかりは概念レベルで付与されるべきとしている点である(Leveltモデルの語彙符号化では語彙が意味情報を持たないとするため)。
●語彙選択のコントロールに関して、点検メカニズム、抑制プロセス、語の活性化レベルに基づく選択という視点があったが、言語手がかりと高頻度による語の活性レベルに基づく選択がもっともよく語彙の符号化の現象を説明している。
(鳴海)
ディスカッション&コメント
・phonological facilitationの部分で、どの程度音韻的に類似していればfacilitationが起こるのであろうか。本文の例に出てきた、mountainとmouthの程度でも起こるのか、それともreadとleadのようなミニマムペアではより強くfacilitationが起こるのだろうか。
・言語の混合のことをblendと書いてあったが、combineの方がわかりやすいかもしれない。
・"simple access and complex selection" と "complex access and simple selection" の違いがいまいち分からなかった。Accessが簡単であればselectionも簡単であり、accessが複雑であればselectionも複雑になるのではないだろうか。
・"simple access and complex selection" の部分で、L1とL2では異なる語彙概念を持っていると書かれているが、これは今まで言われてきているメンタルレキシコンの構造 (特にKrollらのRevised Hierarchical Model) とは異なるのではないだろうか。上級者になれば、L1とL2で違う概念であると認識できるようになるのかもしれないが、初級者では難しいのではないだろうか。
(森本)
ページトップに戻る
2007/09/28
Chapter 4 Lexical Encoding and Bilingual Lexicon (pp. 68-82)中
4. Conceptual and Lexical Presentation in Bilingual Memory (pp. 68-71)
● 語彙知識のどの側面がレキシコンに蓄積されるのか、また概念と語の意味の関係はどのようになっているのかについて研究者で意見は一致しておらず、バイリンガルレキシコンの構造やそれが持つ情報については明らかになっていない。
● Pavlenko (1999):バイリンガルメモリー研究における問題点
⇒ 意味的情報と概念的知識がどちらも明確に定義されていない。
(a) 概念は語の意味とは区別されるべきである。
(b) 意味的・概念的表象は区別されなくても良い。
● 意味的情報と概念知識を区別するかどうかの違いが、言語処理における概念と意味の表象に対する異なる2つのアプローチを生む。
① 意味的・概念的表象は相互依存関係にあり、同じレベルにある
● Roelofs (1992) やLevelt et al. (1999)の語彙アクセスのモデルは概念と意味レベルを統合している例。(互いにつながっているノードによって概念が表される)
⇒ 概念は語彙的(1語で表される)にも、非語彙的(節や文で表される)にもなる。
概念は文化・言語に依存するので、言語によって異なる概念が存在しうる。
● 語彙概念は背景知識とも結びつき、語彙アクセスは概念の活性化を伴う。
● Roelofs (2000):失語症の人が語彙のアクセスに失敗しても、概念的特徴を抽出できた。→ 概念レベルと語レベルのつながりにダメージがあったと考える。
② 意味的・概念的表象は異なったレベルに蓄積される
● Paradis (2000):語彙化された概念の語彙的・意味的要素は概念の一部ではなく、言語システムの一部である。概念的性質と語彙的性質は異なるもの。
⇒ ある失語症患者は語彙表象にアクセスできなくても、語彙入力のための概念表象はアクセス可能である。
● Pavlenko (1997):アメリカで英語を習得した英語/ロシア語バイリンガルは、 "privacy"を定義できたが、語についてのエピソード的知識がなかった。"privacy"を意味する語がない言語があり、語彙概念がない。
⇒ 語彙化された概念は、区別された意味的要素・概念的要素を持っている。
● Jarvis (2000):Pavlenkoへの批判 ⇒ 意味と概念の暗示的知識を考慮していなく、語の明示的意味や暗示的意味を排除している。意味と概念レベルの区別は、失語症患者が語に関する意味的情報を抽出することができるが、語の形式や概念的特徴にアクセスできないときに証明されるのではないか。
● 意味的・概念的表象に関する理論の違いは表4.1(p. 70)を参照。
● Pavlenko (1999):意味的・概念的知識についての意見が分かれるのは、研究の多くが文脈から切り離された実験室的環境でなされており、今後文化的文脈的要因にも配慮した研究が求められる。
5. Models of the Organization of the bilingual Lexicon (pp. 71-81)
● バイリンガルの語彙表象研究初期のレキシコンに関する3つの重要な分類
⇒ Weinreich (1953) → 語彙的storageのみを用いて分類
(a) compound:ある語の概念表象は共有される。1つの概念に対して2つの語。(Fig.
4.7参照)
(b) coordinate:話者は2つの言語で異なる概念を持つ。(Fig. 4.8参照)
(c) subordinate:ある語の概念はL1の語(L2とつながっている)と直接結びついている。(Fig.
4.9参照)
⇒ Ervin and Osgood (1954) → 2言語を異なる環境で学習した場合も考慮
* 2言語を異なる文化的文脈で習得した場合(b)の傾向。
* 2言語を同時に習得した場合(a)の傾向。
* 外国語学習環境(教室など)で学習した場合(c)の傾向。
● Ervin and Osgood の問題点
① 語の性質(言語間での類似性、品詞、抽象度)がレキシコンで語がどのように符号化されるかに影響している。
② 熟達度の発達とともに語彙表象は変化する。
→ 熟達度が高くなるとsubordinateからcompoundへとシフトする。
● 階層モデル (hierarchical model)(Potter et al., 1984):これまでのcompound vs subordinateの分類を再編。概念がL2の語と結びつく2つの方法。
(A) concept mediationモデル:L1とL2の語の両方が同じ概念から連想される。L1同様L2も共有概念を通じてアクセスされる。(Fig.
4.11)
(B) word associationモデル:L2語は概念への結びつきがなく、L1の訳語と結びついている。そのためL1からL2にするときは概念を抽出しなくて良い。(Figs. 4.10)
● Potter et al. (1984):階層モデルを検証。→ picture namingが熟達度上位と下位の両方においてword translationと同じくらいの時間だった。
→ (A)を支持
● 他のモデル検証の研究:
① Potter et al. (1984)の下位グループよりも熟達度が低い学習者グループはpicture
namingよりtranslationが速かった。
② 熟達度に関わらず、cognatesの方がnoncognatesを訳すより速かった。また熟達度の低い学習者のほうがcognates facilitationの効果が強かった。
③ 語が翻訳等価(translation equivalent)であるかどうかを判断する実験。
→ 熟達度の高い話者は、語に意味的関連がある場合判断が遅く、熟達度の低い話者は、語の形が似ている場合に判断するのが困難だと感じた。
● RHM (revised hierarchical model) (Kroll & Stewart, 1990, 1994):異なる言語発達段階において、概念と語の結びつきの強さは変化する。
⇒ L2習得の初期段階ではL1の語と概念、L2の語とL1の訳語のそれぞれの結びつきは、L2の語と概念の結びつきよりも強いと仮定。熟達度が上がるにつれて後者は強くなる。(Fig. 4.12)
⇒ L2とL1のリンクの非対称性(Fig. 4.12)
● 階層モデルの問題点
① これらのモデルは語彙的と概念的表象のモデルであるが、実際は語彙アクセスについてしか説明していない。概念がどのように表象されているかは明らかでない。語彙レベルに語の意味が含まれているかどうか、語と概念の関係も不明。
② 概念から語彙への自動的アクセスと、意識的な処理や問題解決との区別がされない。
③ word translationは語彙的処理、picture namingは概念的表象であるという考えに基づくが、翻訳は様々なサブステップからなる。語彙が他の語彙を引き出すという語彙アクセスは存在しなく、レマは常に概念表象を通じてアクセスされる。
● L1レマからL2語が学習された場合、L2とL1の訳語のリンクが強いことも考えられる。
⇒ ある言語の語を知覚するとその訳語の活性化レベルを高めることで語の選択が速くなる。→ 初級学習者に見られる。
● 初級者 ⇒ picture namingは遅い → 最初に絵だけしかなく(概念は活性化される)L1が提示されないので訳語のL2が出てこない。
● 上級者 ⇒ picture namingとword translationが同じくらいの速さなのは、あるレベル以上の学習者はL2語をL1訳語ではなく概念と結び付けているから。L1/L2リンクは弱い。
● 熟達度だけではなく、習得の文脈、教授法、学習ストラテジーも考慮する必要がある。
● word associationモデルを支持する研究
⇒ Dufour et al. (1996):cognates / noncognatesの翻訳スピードの比較。音韻レベルでのfacilitation効果によりcognatesの方が速いことが仮定できる。熟達度の低い学習者のほうがfacilitation効果が高かった。なぜか?
→ 異なるL2熟達度における語の異なる自動性のレベル。(上級者は語の音韻形式に自動的にアクセスでき、音韻的facilitation効果が小さいが、初級者は音韻形式に意識的にアクセスするので効果が大きい。)
⇒ Talamas et al. (1995):熟達度の低い学習者は、綴りの似ているL1 / L2の語が翻訳等位であることを判断するのに時間がかかった。
→ レマから語形へのマッピングがまだ強い符号化を受けないので、語の形式的側面に注意がいく。上級者はレマの音韻形式に自動的にアクセスできるので、様々な意味的側面に注意を向けられる。
● RHMの問題点:語彙アクセスの理論は、概念的表象の活性化無しに語彙を抽出することはできないとしているので、習得の初期段階でL1 / L2のリンクがL2語と概念のリンクよりも強いというRHMの説明は成立しない。
● conceptual feature model (de Groot, 1992):語の概念へのリンクを前提。それらは相互に結合した特徴のまとまりによって構成される。バイリンガル話者の2言語における概念表象は共有されているとは限らないが、重なっている可能性。(Fig. 4.13)
● Van Hell and de Groot (1998):cognates、具体的な語、名詞は一般的により多くの概念的特徴を共有している。言語間でより多くの概念的特徴を共有している語は、かけ離れている語よりも翻訳するスピードが速い。
● L2語彙研究において、新出語を学習する際に (a) 音韻的、(b) 綴り、(c) 統語的、(d) 形態的、(e) 意味的、(f) 語用的/社会言語的、(g) 慣用的な情報を習得する必要がある。前者4つのタイプに関しては研究者間で意見が一致している。
→ しかし意味的な特徴に関する情報がどこで符号化されるかは明らかでない。
○ Levelt et al. (1999), Roelofs (1999):語の意味が保存される異なる概念レベルが存在する。
○ de Groot (1992):概念的・意味的情報は語彙記憶の中に一緒に保存。
● Paradis (1997, 2000), Pavlenko (1999):概念は意味的・統語的情報を持つレキシコンの外に位置する。
● de Groot (1992, 2000), Paradis, Pavlenkoは、L1とL2の概念が別々のものであるが、多くの特徴や記憶痕跡 (memory trace) を共有しているという点で一致。また、ある語とその訳語の意味は重なっている部分もあるが全く同じではない。語用的・社会言語的情報が概念レベルに蓄積されていると仮定。
● バイリンガルレキシコン研究における大きな課題は、蓄積されている項目間での関係がどうなっているかである。
● Wilks and Meara (2002):母語話者や非母語話者のレキシコンの中核において、語彙項目間で多くのつながりがあり、それはL1内のほうがL2内でよりも多い。
→ モデル内で可能となるよりも実際は少ない結びつきしかない。
⇒ メンタルレキシコンの高いネットワーク密度に反する。L1/L2のネットワーク構造は異なり、ある語彙項目はネットワークの中心的役割を担い、ある項目はネットワークの周辺に存在すると仮定。
● Wolter (2001): L2の語が存在するネットワークでは、一般知識 (world knowledge) の深さが、語彙項目が中心的又は周辺的に位置するかを決定する。(高頻度語⇔低頻度語=中心的⇔周辺的)(Fig. 4.14)レキシコンの中心にある語は意味的つながりが強く、周辺の語は音韻的つながりが強い。また、L2の語彙項目のつながりは不安定。
● Wolterの研究は、メンタルレキシコンにおける語のリンクはどうなっているのか、それらのリンクは熟達度の変化とともにどのように変わっていくのかに示唆。
(鳴海)
ページトップに戻る
2007/10/13
Chapter 4 Lexical Encoding and Bilingual Lexicon (pp. 82-90) 後半
6. Code - Switching and Lexical Processing (pp. 82-84)
● コードスイッチングは、同じ談話内で2つ以上の言語の使用を伴い、多くの語用論的、社会言語的現象を含んでいる。
● 2つの分類
① 意図的コードスイッチング:意識的。バイリンガルのコミュニケーション。
② 非意図的コードスイッチング:言い間違い。2人の話者がコミュニケーションに使われる言語のみを共有している。
● コミュニケーションに用いられる言語はどのように決定されるのか?
→ 非意図的な場合:言語選択は話者がコントロールできないので考慮しない。
→ 意図的な場合:主に社会言語的要因によって決定される。
● 話す言語の決定は、概念化装置 (conceptualizer)の中でなされることが研究者間で一致。(概念化装置は話者の場面の知識に基づき、場面に適した言語を選択するモジュールである。)→ 概念的情報に加え、発話前メッセージも同様に言語を特定する性質 (language - specifying feature) や言語手がかりを持つと仮定される。
● de Bot (1992):コートスイッチングは、L2話者が二つの並行したスピーチプラン(1つは選択された言語、もう1つはそこで使用されていない言語)を形成することで説明される。選択された言語の符号化において問題が生じた場合、L1のプランを用いる。
⇔ 非効率的であるという批判(↓)
● de Bot & Schreuder (1993):コードスイッチングは発話前プランに付加された言語手がかりを話者が無視したときに生じると仮定。
⇔ もし言語手がかりを無視することが可能であれば、発話前プランの意味的細目も無視されてしまい、誤りのない産出における適切な語彙入力の説明が不可能になってしまう。
● 最近のコードスイッチングの理論は、どの言語を使用するかについての情報は、言語手がかりの形で発話前プランの中に含まれていると考える。
● Myers-Scotton (1993):
* Matrix Language → コミュニケーションにおけるより支配的なモード
* Embedded Language → Matrix Languageに埋め込まれるもの
● Poulisse & Bongaerts (1994) and Poulisse (1999):意味的、統語的タグに加えて、レマも言語タグとともにラベル付けされており、レマの活性化は、言語の特定もの含めた発話前プランの特性が全て、レマの特性と合致したときにのみ起こる。
● La Heij (2005):レマは言語タグを含む必要はなく、概念レベルにおける言語手がかりで十分。Levelt et al. (1999)の新しい語彙の符号化モデルでは、レマは意味的情報を含まないから。
● 非意図的コードスイッチングについては意見が一致:
→ 誤って符号化された概念がL1とL2のレマ両方を活性化し、これらのレマがさらにレキシム(語彙項目)を活性化する。L1のレキシムのほうが頻繁に使用され、高い活性レベルに位置するため、音韻処理でL1語彙が選ばれる。
● 意図的コードスイッチングは、話者が意図的に発話前プランのL2細目をL1細目にかえたときに生じる。
→ 適切なL2語彙知識の不足、L1の方がL2より概念細目に合致
7. The Influence of L1 on Lexical Encoding (pp. 84-86)
● 様々な転移に関する定義があるが、ここでは便宜上転移は、言語習得、使用、理解におけるL1の影響であると考える。
● 転移の最初の段階は、概念的転移。L2習得は、言語と概念についての話者の経験全てに基づいて構築された心的概念システムの上に、新しい言語形式の体系を写像すること。つまり、L1の概念体系はL2の語彙使用や習得に大きな影響を及ぼす。
● Swan (1997):概念的、意味的転移の原因を分類。
(a) L1とL2両方があるものごとや行為に対して同じ概念を持つこともあるが、二つの言語は異なる場所に言語ラベルを与える。
(b) 概念転移は、あるものごとや行為が、2つの言語において概念や語彙形式の観点から異なって分類される場合に生じる。
(c) 言語が(特に抽象的な)物事を異なって概念化するため、L2の概念とL1の同等の概念を結び付けられない。
● 発話産出の心理言語学的モデルでは、ある語に関する語用論、スタイル、頻度の情報は概念化装置に位置し、学習者がこれらの語彙知識の側面を身に着けるまではL1からの転移が起こるとされる。この考えに基づくと、語の意味も概念レベルに保存され、語の意味の転移も概念化の段階で生じる。
● L2語彙研究では、学習者が初めてL2語をメンタルレキシコンに取り込むとき、L1の翻訳等価の持つ概念的特徴と関連付ける傾向があることで一致。その語と出会う回数が多くなるにつれて、新たなL2の概念的特徴が構築される。しかし、L2学習者は母語話者ほどに豊かな概念構造を築くことができない。
● 転移はレマ、レキシムのレベルでも起こる。語の意味だけでなく、統語的な情報も転移する。学習者のメンタルレキシコン内では、L2レマは対応するL1レマの区分パラメータ (diacritic parameter) を指している可能性。転移は正しくも誤っても生じる。
● レキシムレベルでの転移は少ないが、主に同族語 (cognate) において生じる。
● 音素のL1からL2の転移は良くあるが、学習者がL2語をL1語であるかのように発音することは稀。→ L2語が同族語であるため、L1と発音が似ているだろうと予測。
8. The Acquisition of L2 Lexical Knowledge (pp. 86-90)
● Meara (1997):語彙学習のテクニックに関する研究は多くあるが、語彙習得のモデルを構築する試み、特に語の学習プロセスの研究、は少ない。
● 語彙習得研究における課題:
① どのように新しく習得された語彙項目の記憶痕跡 (memory trace) が発達するのか。
② 語の知識の異なる側面はどのように符号化されるのか。
③ L2熟達度の発達とともに、メンタルレキシコンの構成はどのように変化するのか。
● Truscott & Sharwood-Smith (2004)のacquisition by processing theory (APT):統語的知識の習得に関するモデル。話者が未知語に出会うと、最初にその語の音韻形式に対応する空の統語的構造をつくる。次に統語処理装置が、その語の統語的環境に基づいた統語構造のための文法的カテゴリーを構築。その後、文脈の手がかりに沿って語に意味を付与する。コネクショニズムの立場をとり、学習は項目の活性化レベルの上昇と、層 (layer) のつながりを強化することを通じて生まれるとする。
● Meara (1997):習得は新しく出会った語と学習者のレキシコンに既に存在する語とのつながりを構築すること。関連付けられる語はL1翻訳等価かL2語(類義語、反意語)。
⇔ 習得おいて概念的レベルとレマレベルの区別がなく、記憶痕跡についても議論がない。しかし熟達度の発達とともにレキシコンで生じる変化を説明するのに有用。
● 上記2つの研究は語の意味と統語的知識に限られており、綴り、音韻、スタイル、頻度、コロケーションについては含まれていない。これらを含むモデルは無い。
● N. Schmitt (1998):4人の上級学習者のスペリング、文法的情報、意味、11語の結合 (association) の習得について研究。
→ 語の意味の知識は、受容的から産出的、未知から受容的にシフト。学習者の語の結合がよりネイティブライクに。語の意味の一部しか知らなくても適切な文法的知識を持ち、スペルミスは少なかった。
● 熟達度と語彙項目間の関係の変化は主にRHMで説明されるが、Meara (1997)の語彙学習理論がより詳細な説明。
● Meara (1997):語彙学習は関連するリンクの構築 (associative link)。L1項目へのリンクだけでなく、L2語にもリンク。そのリンクは一方向的 (unidirectional) また双方向的 (bidirectional) である。この2つのタイプがあることで、ある語はactive/productiveであり(双方向的)、ある語はpassive/receptiveである(一方向的)ことが説明できる。話者の良く知る語彙には多くのリンクが存在している。語彙の習得はこのリンクを形成し、一方向的リンクから双方的リンクになることである。
● 語彙習得において、学習された語彙は長期記憶に保存される必要があり、記憶が重要な役割を果たす。初期の研究では長期記憶に保存される新情報はより深い処理 (in-depth processing) が必要であるとされていた。しかし深い処理が何かは明らかでなかった。
● 新情報に学習者が十分な注意を向け、また新情報と旧情報の関連が強くなるとより保持が高まる。
● Laufer & Hulstijn (2001):involvement load hypothesisをたてる。処理に関連するものは3つの構成要素からなる。
① need → 与えられた語を学習する必要性。
② search → どのように語の意味がみつけだされるか。
③ evaluation → その語の意味を他の語の意味と比較したり、その語のある意味を他の意味と比較したり、文脈の中でその語が適切かどうかを評価する。
語彙学習指導タスクや自然な環境には、これらの要素がある場合と無い場合があり、また程度も様々である。
→ involvement index:involvement index(上記の指標)が高いほど、長期記憶における語の保持が高まる。
(鳴海)
ページトップに戻る
2007/10/26
Chapter 5 Syntactic and Phonological Encoding (pp. 91-96)
1. A general overview of syntactic encoding processes (pp. 91-93)
● 統語的符号化はサブプロセスから成る。
・ レマレベルにある統語的情報と文法的形態素の活性化(宣言的知識)
・ 節や句を構築する統語的ルールの選択(L1の手続き的知識)
・ 文の要素の並び方を決める語の順序のルールの適用(L1の手続き的知識)
● Ullman (2001), Paradis (1994):失語症と現代の脳イメージの研究を用いて、宣言的知識と手続き的知識は脳の異なる部位に属することを示す。
● 統語的処理の基本的特徴
・ Levelt (1989), Kempen and Hoenkamp (1987):model of grammatical encoding
最も詳細にわたり、研究により指示されている。何度か修正される。
・ Incremental Procedural Grammar (IPG):Kempen and Hoenkampが開発したものが現在も残る。
・ 他にも多くの理論(Minimalist Program、Optimality theoryなど)
● IPGの4つの基本的な仮定:
① 処理を行う構成要素は、少なくともL1では自動的に働く。
→ 統語的符号化のサブプロセスは並行的/自動的に進み、処理要素はそれらの特徴を持つインプットによって機能する。(名詞句の例)
② incrementality:処理要素はその特性を持つインプットの一部によって機能する。
つまり前の要素の処理が終わらなくてもよい。そのためには既に処理されたメッセージはどこかに保存されることがある。
③ liniearization problem:アウトプットの成果は線状であるが、それは根底にある意味に線状に写像されるわけではない
。
例) "Before going to university, he served two years in the
army"
命題はhe served two years in the armyであり、Before going to universityよりも先に概念化される。
最初の命題が符号化され始めるが、次の命題が符号化され終わるまで、記憶に保存される。
文法機能も一時的に保存される。(主語述語の一致 )
④ 情報の保存、中間的処理のアウトプットが一時的に保存される特別な文法的メモリーの存在。
● 文法的符号化がどのように起こるのか?
① レマの活性化(このレベルでの統語的性質の符号化へのアクセスを伴う)
② 分類過程(category procedure)
→ 補語や修飾語がないかどうか現在処理中のマテリアルを調査しdiacritic
featureの価値を付与する。
③ phrasal procedureが句に文法的機能を与える。(NPが主語か目的語か)
④ S-procedureが文の統語構造を構築し、処理された構成要素を適切に並べるための語順の規則を用いる。(文が従属節を伴う場合は、さらなる従属節procedureがそれを符号化する)
2. Diacritic features: The encoding of grammatical gender (pp. 93-96)
● L2の統語的処理の実証的手法を用いた数少ない研究の中の一つにインド・ヨーロッパ語における文法的ジェンダー
(grammatical gender) の研究がある。
● L1産出では、文法的ジェンダーは名詞の語彙統語的 (lexico-syntactic)性質と考えられている。
● monolingual modelでは、ジェンダーを与えられたすべての名詞はジェンダーを特定するジェンダー・ノードと結びついている。
● L2研究での問題:もし複数の言語が同様なジェンダー体系をもっている場合、L1とL2のジェンダーシステムは言語観で共有されるのか?
(1) 2言語のジェンダーシステムは共有され、同じジェンダーのL1/L2語は同じジェンダー・ノードで結びついている。(図5.1)
*これはgender-integrated viewとよばれる。 (Costa, Kovacic et al., 2003)様々な言語の文法的ジェンダーと意味的ジェンダーの関係
と、音韻的特徴とジェンダーの関係に基づく。
→L1とL2で同じようなジェンダーの特徴があれば、学習者はあるL2語のジェンダーがL1語と同じと推測するかもしれない。
(2) 2言語のジェンダーシステムは別々のものである。(図5.2)
*これはlanguage autonomy viewとよばれる。(Costa, Kovacic etal., 2003)指示する根拠はないが、異なるジェンダーシステムを持つ言語は存在する(2つのジェンダーの言語と3つのジェンダーの言語)。
学習者は初めは別々のジェンダーシステムを持っていたのが、熟達に伴ってそれらのシステムを統合することもあるかもしれない。
● 名詞の加算・不加算や動詞の自動詞・他動詞に関する情報はL2話者のメンタルレキシコンの中でどのように保存されているのか? (一緒または別々か?)という問題も生じる。
● ジェンダーの選択は活性化に基づく仕組みか、それとも自動的プロセスか?
(1) L1では名詞のジェンダーが符号化される速さはあるジェンダー・ノードの活性化レベルに依存する。(女性名詞の符号化は、その前にも女性名詞を符号化した場合の方が男性名詞を符号化したときより速くなる。)
(2) 名詞のジェンダーは名詞が符号化されるときにアクセスされる。この処理は自動的で活性化レベルには依存しない。
● Costa, Kovacic (2003):L1/L2のジェンダーシステムには2タイプあり、ジェンダーの選択に関して2種類あるということは、4つの可能性が存在する。gender-integrated
viewでもlanguage autonomy viewでもジェンダーの特性は自動的または活性化拡散のメカニズムに基づくどちらかの方法でアクセスされる。
● 2つのジェンダーシステムが別々の場合、L1とL2の価値が同じでもジェンダーの符号化を促進しない。language
autonomy viewでは自動的アクセスも活性化拡散の説明もジェンダー符号化の速さを説明することができない。またジェンダーシステムが共有されていても、同じジェンダーの語を取り出すスピードには違いがない。
● 促進が見られるのはジェンダーシステムが統合され、アクセスが活性化拡散に基づいているときのみ。(速さが遅くなるのはL1翻訳等価の影響
)
● Costa, Kovacic et al. (2003)の実験:ジェンダーシステムが似ている言語話者(仏&伊、カタラン&西)と異なる言語話者(クロアチア&伊)。L2
picture namingタスク。3つのペアに差はなし。
→ L1/L2のジェンダーシステムが統合されている場合、ジェンダー特性のアクセスは活性化には基づかない。
→ 更なる研究が必要(L2話者は1言語のジェンダーシステムに頼っていのか?もしそうでないなら、アクセスは自動的か活性化ベースか?)
(鳴海)
ディスカッション&コメント
・言語の線状性とは、2つ以上の意味や形態を同時に発することが不可能なことから、少なくともアウトプットに当てはまる。インプットでは、2人以上の話を同時に聞き分けられる人がいるとすれば、その場合も厳密には非常に短い時間差で符号化や解釈ができているということだろうか。あるいは、同時に平行して解釈できるのかもしれない。
・Noun Phrase(NP)等の文法上のジェンダーが存在しない日本語や英語のL1話者は、仏語や伊語に熟達した場合でも、ジェンダーの文法的符号化プロセスはNPとジェンダーが一体化/自動化されているネイティヴと異なるのだろうか。(長橋)
ページトップに戻る
2007/11/9
Chapter 5 Syntactic and Phonological Encoding (pp. 97-100)
3. Accessing Grammatical Morphemes (pp. 97-98)
● 心理言語学の用語では、形態素はどのように蓄積されアクセスされるかという観点から分類される。(一般的には内容語/機能語、開いた類/閉じた類)
● 4-Mモデル (Myers-Scotton & Jake, 2000):コードスイッチング、L2発達データ、失語症者の言語産出の研究に基づき4つに分類。
① Content morphemes(内容形態素):主題に関する役割を与えたり受けたりし、maximal projectionの主要部となる。
⇒ 名詞、動詞
② System morphemes(システム形態素):主題に関する役割はない。
⇒ 決定詞、派生、前置詞
(A) early system morphemes:概念的に活性化され、内容形態素の主要部に依存。
⇒ 決定詞を含み、発話前プランで特定される特徴 ([+accessible] や [-accessible])、名詞の単・複数、派生の接頭辞などに基づき活性化される。
(B) late system morphemes
(a) bridge late system morphemes:要素をつなぎ構成素が整っているか確認。
(b) outsider late system morphemes:maximal projectionの外の情報に依存。
表5.2にまとめ(4Mモデルとは①、(A)、(a)、(b)を含めたモデルである)
● Myers-Scotton (2005):4つのタイプの形態素は、L1/L2そしてそれらを同時に使用する場面では異なってアクセスされる。
⇒ まず①と(A)が発話前メッセージの概念細目に沿ってメンタルレキシコンの中で活性化されて選択され、それらが統語的構築過程を活性化する。
● Pienemann (1998):IPG(Incremental Procedural Grammar)に基づいて同様の分類。
① Lexical morphemes:early system morphemesと対応。レマの識別特徴に基づいて分類され、レマレベルで概念的に活性化される。(決定詞の例)
② interphrasal morphemes:outsider late system morphemesと対応。文の中の句の一致により選択される。(人称による動詞の決定)
③ phrasal morphemes(記述無し?)
● IPGは最初にlexical morphemesが活性化され、phrasal morphemesが選択され、interphrasal morphemesに続く。
● Processability theory (PT):熟達度の高いL2話者は上記の順で形態素の3つのタイプを符号化するが、学習者があるレベルでの形態素の活性化に必要な手順を習得していない場合、それ以降意図したメッセージを文法的に処理することはできない。
4. The Activation of Syntactic Building Procedure (pp. 99-100)
● 統語構築順序についての研究は少なく、L1においての研究もあまりなされていない。
● 文(プライム)におけるある統語構造の使用が他の文における同じ構造の使用を増加させる。これはプライミング効果とよばれる。
● プライミング効果は類似した統語構造においてのみ生じる。(語彙、主題、音韻、などの類似では見られない)→ ひとつの統語構造が他の似たような統語構造を活性化する。つまり活性化拡散のメカニズムは統語的符号化でも機能している。
● さらなるプライミングの研究:L1話者は思い出さなければならない文を作るために最近活性化された語を用いることがわかっている。
→ 統語的符号化は語彙中心であることを支持。
● L2レマはL2統語構築手順に特定して活性化するのか、それともL1同様なのかという問題。
・De Bot (1992) and Pienemann (1998):句そして節構造の構築プロセスは言語に特定される
(language specific) ものである。
・Pienemann et al. (2005):L1の統語的順序の転移は、L2学習者が既に処理ヒエラル キーにおける前段階の処理を習得していることが条件である。
⇔ Truscott and Sharwood-Smith (2004):APT (Acquisition by Processing
Theory)では、もしL1の統語手順がL2の過程より活性化されるとするならば、目標言語プロセスの代わりにL1が選ばれるのではないか?
*Pienemann et al.の議論は十分な根拠に基づくが、APTモデルは検証されていない。
● Meiyer and Fox Tree (2003):L1とL2のある構造における統語的手順が両言語において同じ場合、何が起こるのだろうか?
・プライミングの実験1:熟達度の高いスペイン語・英語のバイリンガル。
① NP-NPを補語、またはNP-PPをとる与格動詞を含む英文のリコール。目標文は英語で提示。その後スペイン語で同じ構造又は異なる構造を含むプライム文を提示。
② 錯乱語が提示される。参加者はその語が文に含まれていたかを判断。
③ はじめに提示された英文をリコールする。
・その他の実験:直接目的語の代名詞の順序、2重否定 vs. 1重否定
⇒ ある言語における1つの特定の句構築手順の活性化はもうひとつの言語における手順の選択に影響を与えるかを調べる。
→ プライム文である統語構造を見た場合、L1/L2両方において話者はある統語構造からもうひとつの統語構造に切り替えた。2重否定を除く。両方の言語に必要な統語規則は中央に保存される。またそれらは言語に関するラベル付けはされていない。
● 一度L2規則が自動化されると、L1/L2の統語規則は同じ場所に保持される。しかし熟達度が低い場合、規則の使用は意識的で宣言的記憶に保存され、それは手続き的知識とは異なる脳の部分である。
● Pienemann et al. (2005):もしL1/L2の規則が同じだとしてもL2学習者は下位の統語手順を先に習得しないと、L1からその知識を転移することはできない。
⇒ 2言語のバランスの取れていないバイリンガルはL1とL2の統語手順を同じ場所に保存していない。
(鳴海)
ディスカッション&コメント
・ 語彙でもプライミングは起こるので、類似した統語構造のみにおいて生じるというのは、今までの研究と合致していないような気がする。
・ 統語構造と語彙などのプライミングが同時に働くようなマテリアルを作成した場合、どのようなプライミングが最も優先されるのだろうか。
(森本)
ページトップに戻る
2007/11/30
Chapter 5 Syntactic and Phonological Encoding つづき (pp. 100-107)
5. Transfer and the Acquisition of L2 Syntactic Knowledge
●L2習得において統語的知識の転移と習得は相互に関係したプロセスであると考えられてきたが、後に統語の習得は単にL2の文法体系を転移するだけでなく、L1とL2から独立した創造的な構築プロセスが適用されることが明らかになった。
●Chomsky (1965) の普遍文法 (Universal Grammar: UG):人間には言語獲得装置 (language acquisition device: LAD) が備わっており、その中にすべての言語について普遍的な原則と特定の言語を習得する際に設定される必要があるパラメータ(普遍文法)がある。
●L2研究では長い間、学習者がUGにアクセスできるかどうか、またできるとするとそれは完全なものかそれとも部分的かという議論がなされた。
●多くの生得主義的パラダイムにおける研究によると、学習者はUGへの完全なアクセスがあり、L2の統語学習には、L1のために構築されたパラメータをリセットし、L2のルールに順応することが必要であると提案。L1の転移に関しては制限がありそれについては異なった見解。
(1)Schwartz & Sprouse (1996):L1統語のすべての側面が転移。L2統語が完全に習得されないのは、L1知識の再構築のために必要なインプットが不十分なために生じた化石化が原因。
(2)Vainikka & Youn-Scholten (1994):転移は語彙的範疇と語順の規則に限定される。
Eubank (1993):語彙と機能的な範疇に限定される。
Felix (1985), Clahsen & Muysken (1989):学習者のUGへのアクセスは限定的、
または間接的であるため、ある年齢以上になると完全な習得が困難になる。
(3)Meisel (1991):学習者はUGへアクセスできなく、入手可能なインプットからL2文法を再構築するために一般的な問題解決ストラテジーを適用する。
●White (1996):UGの理論は文法習得を説明するために誤って適用されている。UGは表象の理論であって発展の理論ではない。
→学習者の中間言語における文法体系は、自然言語の原則と同じか、またそれよりも小さいものであるのかという問題にシフト。
●コネクショニストのアプローチは、生得的な言語獲得装置の存在を否定。言語学習は他の学習と異ならないと主張。
●competition model (Mac Whinney, 2001):コネクショニスト・パラダイムの一つ。
・頻度と文法形式とコミュニケーション機能の関係の複雑さが学習に影響する。
・UGは存在しない。
・L2学習=意図を表現するための特定の表面的な形式を習得すること
⇒form-function mappingと呼ばれる。
・生まれながらの言語能力は必要なく、入手可能なインプットのみに依存。
→学習者が必要なインプットはcueと呼ばれる。
→cueは互いに競争し、重なり合う。(例Mac Whinney (1997):オランダ語では格を決めるcueは語順のcueよりも強い。)
・L2の統語獲得と転移に関しては、学習者はL1のform-function mappingをL2に転移することから開始する。転移により正しいアウトプットが得られなければ、さらにインプットのcueに注目し、一つ一つ構造を組み立てる。
・2言語においてある構造が同じ機能を持つ場合、習得が促進される。一方、類似した統語的構造でもコミュニカティブな価値が異なる場合、学習が困難になる。
●competition modelを用いたスピーキングの実証研究は少ない。
→Dopke (2001):バイリンガルの子どものL1とL2獲得において、学習者が発話の表面構造に注意を向け、徐々にL1とL2における正しいform-function mappingを作ることで統語的知識が構築される。
●コンピュータシミュレーションによりコネクショニストモデルを検証。
→N. Ellis & Schmidt (1998):学習者がどのように人為的な文法の形態素を習得するかを記録し、コネクショニストのコンピュータネットワークを用いてモデル化した。コンピュータは学習者と同様の発展パターンを示し、事前のルール無しに規則的なものを構築することができた。
●APT (Acquisition by Processing Theory)(Truscott & Sharwood-Smith, 2004):メッセージは3つの独立した処理装置によって構築される。
① 概念処理装置 → 言語モジュール外にある。
② 統語的モジュール ③ 音韻的モジュール → 言語モジュールを構成。
・統語的モジュールは言語間において普遍であり、UGへの完全なアクセスがある。
・中間言語のバリエーションのもとはレキシコンに位置する。
・処理による学習は、アイテムの活性化を加えることを必要とし、その結果これらのアイテムがその後の処理において入手しやすくなる。
・転移は起こらない。→習得の初期は活性化レベルがL1>L2のためL1が選択される仕組み。
・APTは完全には発展しておらず、根拠となる実証研究も少ない。
●PT (Processability Theory) (Pienemann, 1998):文法知識の表象よりもむしろ習得の制限に関する理論。
・学習者は必要な条件を習得した言語形式のみ産出できる。(Pienemann et al., 2005)
・処理の構成要素は自動的かつ専門的であり、追加的に機能する。(IPGに基づく)処理の中間段階の産出は文法記憶に保存される。
・統語的符号化が起こる順序:(a) lemma access、(b) category procedure(句のカテゴリーを構築)、(c) phrasal procedure(句を符号化する)、(d)S-procedure(文の中における句の位置を決定)、(e) subordinate clause procedure
・レマはL1とL2で別々であり、言語ごとに識別特徴を含む。すべての統語的手続きはlanguage specificである。
・統語の符号化プロセスはヒエラルキーを形成し、学習者は次の段階に進む前に、下位の文法的符号化の手順を習得しなければならない。
→統語的知識は統語的符号化手続きの順序に従う。
・形態素の例:① 語彙的形態素(過去形など)、② 句の形態素(決定詞)、③ 句間の形態素(動詞の屈折)
⇔de Bot (1998):Pienemannは知識不足によりある段階で処理が途切れた場合どうなるかという説明をしていない。おそらく学習者はその場合、知識不足を補うためにコミュニケーションストラテジーを用いていると考えられる。
・PTは多くの実証研究により支持されている。
・Wei (2000):content morphemeが処理のヒエラルキーにおいて最初に活性化され、習得される。次にearly system morpheme、そしてlate system morphemeと続く。
●Pienemann et al. (2005):学習者はL2の文法体系を処理のヒエラルキーに従い、下から順に一から再構築する。L1の転移は発達とともに緩和され、転移される構造が発達中のL2体系において処理可能な場合にのみ生じる。(Table 5.4参照)
→Hakansson, Pienemann & Sayehli (2002)によって支持される:スウェーデンのドイツ語学習者は、特定のルールを処理できる段階になるまでL1の知識を転移しない。
●まとめ
*生得主義理論:L2学習において生得的な言語獲得装置が存在し、それは部分的または完全にアクセスできる。
*PT:統語体系の制約に基づいて様々なL2の統語的符号化プロセスが習得されるという流れに焦点。
*APT/competision model:入手可能なインプットから統語がどのように学習されるのか?
・competition model→統語ルールの習得はインプットの分析を通じて可能になる。
・APT/生得主義理論:学習は主として活性化に基づくメカニズムであるが、それとは別に生まれながらにもつ言語モジュールが存在する。
(鳴海)
ディスカッション&コメント
・PTでは熟達度がある程度高くならないとL1からの転移が起こらないと言っているのであろう。
・今回は統語の転移について見ていたが、意味の転移と競合したりはしないのであろうか。
(森本)
ページトップに戻る
2007/12/21
Chapter 5 Syntactic and Phonological Encoding (pp. 107-121)
6. Code-Switching and Syntactic Encoding (pp. 107-8)
●この分野においては多くの研究がなされているが、これらが用いている理論の性質は複雑であり、また発話産出の認知的側面を考慮しているものは少ない。ここでは、認知心理学的背景を持つ、Myers-Scotton
(1993)のMatrix Language Frameのみについて触れる。
●Myers-Scotton (1993):Levelt (1989) のモデルに基づいた、発話産出の心理言語学的理論。
→Matrix Language:常にコミュニケーションにおいて支配的なモード。文法的枠組み。
Embedded Language:より支配的ではないモード。
→二つの制約
① Morpheme order principle:Matrix Languageが形態素の順序を決定。
② System morpheme principle:句の構成要素の間における文法的関係を指示するsystem
morphemeも同様にMatrix Languageから来る必要がある。
→ある文法的形態素は発話前プランにおいて概念的に特定されていると仮定。その他のものは統語の構築過程により、形成される。つまりそれらはcode-switchingにおいて異なって働く。
⇔MacSwan (2000, 2003):Myers-Scottonの仮説は文法理論によって支持されない。さらない統語的枠組みという考えは、統語的符号化が語彙中心であるという自身の仮説に反する。→ 矛盾したモデルである。
7. Summary of Grammatical Encoding Processes (pp. 108-9)
●レマの識別特徴に関しては、近年ではジェンダーのみが研究されている。
→上級のL2話者にとってジェンダーの符号化は活性化に基づくもの、または自動的であり、ジェンダーの特性はL1とL2で別々に保存されている、または同じジェンダーノードを共有している。
●文法的な形態素は、発話前の細目と統語的符号化の過程の2つの異なった方法により活性化される。(研究者間で一致の傾向)
●L2レマはL1の統語構築過程を活性化するのか、それともL2のみを活性化するのかという問題。
→Meijer & Fox Tree (2003):もしある文法的なプロセスがL1とL2において同じ場合、それらは統合され、上級L2話者においては言語の指定はない。
⇔PT:統語構造には処理のヒエラルキーがあり、L2学習者はある構造を学習する際、ヒエラルキーにおける前段階の処理ができる必要がある。
→つまりL1をL2に転移・適用するにはL1のプロセスがヒエラルキーにおいて位置づけられる段階でなければならない。
●転移や統語的符号化処理の習得における3つの理論(PT、Competition Model、APT)。
→PTは様々な統語的符号化プロセスが統語システムの制約に基づいて習得されるとするのに対し、他の2つは統語が入手可能なインプットからどのように学習されるかという点に焦点。PTは実証研究が多くなされているが、Competition Modelは理解における研究が主であり、バイリンガルの統語習得の研究は少なく、またAPTも検証が必要。
8. General Overview of Phonological Encoding Processes (pp. 109-10)
●Roelofs (1997)のWEAVERモデルの音韻的符号化プロセス:
①音韻的語の心的表象にアクセスする。それは語の韻律構造や構成する音韻的要素の情報を含む。
②音節に分ける (syllabification) 処理により、特定の言語の音節分節ルールに基づいた音節に分ける。(音節の分節が布を織るようなので、WEAVERモデルと呼ばれる。)
→韻律の表象は声の大きさ、高さ、長さを決めるパラメータを設定するために使用され、プログラムは発声動作をコントロールするために用いられる。
→増加的 (incremental) 産出を仮定する。インプットの断片でも産出を誘発するのに十分である。
→発声段階については、すでに学習されたプログラムからmotorプログラム (syllabaryと呼ばれる)が引き出される。音節はscoreのまとまりとして産出される。Scoreはジェスチャーやそれらの一時的関係を特定する。
→このモデルは活性化は前にのみ拡散する。
●L2における音韻的符号化はあまり研究されていない。L1研究では、活性化はレマレベルからレキシムレベルに連なって進むのかという課題がある。また、音素の表象はL1とL2で共有されているのか、または別々なのかという問題もある。
●音韻的符号化処理におけるL1の役割とL2音韻論の習得に関しては、多くの研究が言語学的理論を適用している。L2の音韻的符号化メカニズムに関する心理言語学的プロセスの研究は少ない。
9. The Activation of the Phonological Form of Lexical Items (p. 111)
●活性化はレマレベルからレキシムレベルにカスケード的に生じるのかという問題。つまりある語彙項目の音韻形式は選択されていないが活性化されているレマからの活性化も受けるのか?
→L1については活性化のカスケードを支持する研究と支持しない研究がある。L2では多くの研究が使用中ではない言語における語の音韻形式も活性化されるとしている。
●L1とL2の音韻形式に活性化が拡散することは、同語族 (cognate) のnaming latencyの研究からわかっている。多くの研究において、参加者は2言語間において音が類似する語の名前を挙げる方が、音韻的関係がない語の名前を挙げるよりも速かった。
→同語族の場合、使用されていない言語のレマの音韻形式も同様に活性化され、使用中の言語のレマの音韻的特徴を付加的に活性化する。それが絵の名前を挙げる速度を速める。
●Clome (2001)とHermans (2000)はphoneme-monitoringタスクを用いて、活性が音韻レベルに流れていくかを調査。
→ある音素が語に含まれているかの判断において、音素が目標語の翻訳等価に含まれるが目標語自体には含まれない場合、速度が遅かった。つまり使用されていない言語における語の音韻形式も同様に活性化され、使用中の言語における語の音韻形式の選択を阻害する。
10. Shared Versus Separate Phonological and Phonetic Systems (pp. 112-115)
●バイリンガリズムの分野における中心的な課題:どの程度まで符号化プロセスや表象が共有されているのか?
●Roelofs (2003):音韻的要素の記憶表象がどの程度L1とL2で共有されているか、また上級バイリンガルにおいて、音韻的符号化はモノリンガルのWEAVERモデルと同様のincrementalな形で進行するのかどうかを検証。両言語において共通の音韻的要素が一つのものとして、または音韻的特徴の組み合わせとして保存・アクセスされるのかも疑問。implicit primingを用いて実験。
→実験1:対の語を学習。対の最初の語が視覚的に提示されたら、もう片方の語を産出(対象言語は英語。オランダ人の参加者)。3つの種類のセット(2つのhomogeneous
sets、2つのheterogeneous sets、3つ目?)
→前の語の最初の音節を産出することは、L2の目標語を速く符号化するのに役立つが、前の語と目標語が最後の音節を共有するときにその効果は見られなかった。
⇒L2話者は音韻的符号化の際、左側の最初の要素から始め、右の要素へ移行していく。
→実験2:実験1と同様だが、言語(英語とオランダ語)を混ぜる。⇒ 答える語が最初の要素を共有している場合、facilitation効果が見られた。つまり両言語に共通の音韻的要素の心的表象は共有されている。
→実験3:再びL2産出。RQはfacilitation効果は要素の重なりで生じるのか、または特徴の重なりで生じるのか?(L2音素はひとまとまりとして保存されるのか、それとも特徴のリストとして表わされるのか?)
2つの異なるhomogeneous setsを用いる。
①最初の子音を共有(river-boat, girl-boy)
②最初の要素において、一つの音韻的特徴だけを共有(cat-dog, sugar-tea)
①についてのみ産出のスピードが上がり、②については効果なし。
⇒L2の音韻的要素は特徴のまとまりではなく、一つの音素として保存されている。
●Poulisse (1999):オランダ人英語学習者における音韻的言い間違えの熟達度別研究。
→L2音素の代わりにL1音素が偶然活性化され、L2が入るべき音節にL1が入ることがある。L1とL2の音素はおそらく単一のネットワークとして保存されラベル付けされている。通常はL2語はL2音素で符号化され、L1語はcode-switchingで用いられるだけでも、L1音素を活性化する。
●Laeufer (1997):音韻体系の3つのタイプ( coexistent, merged, supersubordinate)
子音の閉鎖音の例)VOT(voice onset time)上における3つの分類。
①voiced stop [b]
②short-lag VOTs : 無声音、無気音の子音。例)フランス語 [p]
③long VOTs: 無声音、気音の子音。例)英語 [ph]
Coexistent system:フランス人の英語話者は音素[p]の共存的表象を持ちえる。つまり2つの異なる音韻表象を同時にかつ別々に持つ。(図5.3参照, p. 115)
Merged system:話者はL1とL2の音素の共通の表象を持つが、それらは別々に符号化される。(図5.3参照)
Supersubordinate system:L2音素のための別の記憶表象はなく、L2音素もL1から同様に現れる。
→ネイティブのようなL2音の実現はcoexistent systemにおいてのみ可能。Merged / supersubordinate systemでは音韻レベルにおいてL1とL2の間のさまざまな程度のインタラクションが見られる。異なる表象体系が実証されている。
→L1とL2を同時に習得、または7歳以前にL2を学習し始めたL2話者の場合、主にcoexistent
systemが現れる。Merged systemはNNSがL1とL2の音素を表現するときに見られ、L2がコミュニケーションの主となるモードであり、L1の弱化が始まる場合に生じる。Supersubordinate
systemは7歳以降にL2を習得した初級から上級のL1を日常的に使う学習者に見られる。
●Roelofs (2003)や発話産出の心理言語学的理論を考慮した場合のLauefer (1997)の類型の問題点:
*すべてのL2音を特徴付けているわけではない。なぜなら2つの言語において音韻的に同じ音は音韻表象やそれらの音を産出するgestural
scoreを共有しているから。
→L2学習の初期段階では、L2話者は単に音韻レベルにおいてL1音素とL2音素を同じにし、L1の音と同じに産出する可能性がある。
→心的表象と音の実現 (phonetic realization) からすると、これらの二つは異なっていないようである。言語に特化しない音声の符号化プロセスのきっかけとなる共通の表象が存在する。
*ひとつの共有された音韻的表象が2つの異なる音韻的符号化メカニズムを活性化することができるのだろうか?という問題。処理装置はどのようにしてどのgestural
scoreにアクセスすべきかを知るのだろうか?共有された表象があるため、言語タグが符号化プロセスを導くことは仮定できない。言語の選択を制御する唯一の方法は、抑制(inhibition)
である。
●心理言語学的に考えると、ある場合は表象は共有され、ある場合はL2音素はL1の音から別々にあらわされると考えられる。
11. The Role of L1 in Phonological and Phonetic Encoding and the Acquisition of L2 Phonology (pp. 116-120)
●L2学習者は初期には、同じではないが似たようなL2に対してL1の音素を用い、L2の音韻に対してL1のルールを適用する。また、L1産出のために自動化されたgestural scoreを修正するのが困難である。
●L2の音韻の学習を説明する3つのタイプの理論:
①Markedness differential hypothesis (Eckman, 1977):
→言語において用いられるものを有標性で表す。(頻度が高い:無標、頻度が低い:有標)
→対応するL1よりも有標であるL2は習得するのが難しい。
②Optimality theory (Prince & Smolensky, 1993):
→UGにおける普遍的原則やパラメータの代わり、すべての言語話者が共有する普遍的な制約が存在すると仮定。
→守らなくてもよい制約や、文法的な発話を構成するにあたり制約の重要度が異なる。
→言語話者は最適なアウトプットを目指し、限られた制約を守らず、重要な制約にのみ制限される。
③Ontogeny(個体発生) model (Major, 1987):
→L2の音韻的発達の様々な段階において、普遍的な発達過程や転移は異なる役割を持つ。初期には転移が大きな影響力を持ち、L2の音韻が発達するにつれ、その影響力が小さくなる。転移の影響が小さくなると同時に、普遍的発達プロセスが習得に影響し始める。
●近年、Connectionist model (言語の普遍性を仮定しない)もL2音韻プロセスがどのように学習するかの説明に寄与。
●本節では発話産出に焦点を当て、音韻論の4つのレベル (segment, syllable, stress, intonation) に注目する。またそれぞれのレベルにおいてL1がどのような役割をにない、L2においてこれらの側面がどのように習得されるのかを考える。
●単一の音素における習得と転移については4つの理論がある:
①Feature geometry:音韻的特徴のヒエラルキーが存在する。
→ある特徴は同時に起こり、またある特徴は相互に依存。また音韻的要素の構成はそれらの要素を互いに異なるものにする対照的な特徴によって決定される。
・Rice (1995):英語には接近音 (approximant) と側音 (lateral) があるが、日本語には接近音のみ。
⇒日本人は[l]と[r]を区別できず、一つの音韻表象を持つ。
・Brown (1998):日本人と中国人の[l][r]の発音。L1の特徴配列 (feature geometry) にない特徴について、学習者は適切なL2音韻を産出できない。その代りに、既存のL1特徴を組み合わせて新たなL2表象を創り出す。(ただしL2学習を幼い時から始めた場合は除く)
②Feature competition model (Hancin-Bhatt, 1994):Mac Whinney & Batesのcompetition
modelにならう。
→L2音韻の習得は、L2インプット内の入手可能な音韻特徴により影響される。インプットの中でL2音韻特徴が気づかれるために競争し、目立つものは学習されやすい。
⇔どのようにして音韻特徴が目立ってくるのか疑問。実証研究なしにL2音一覧における特定の特徴を重要なものとしている。その結果はモデルを完全に支持していない。
③Lexical phonology (Mohanan, 1986):2タイプの音韻ルール (lexical / post lexical) を仮定。
→Lexical:単語レベルで機能し、特定の言語において対照的な音素を産出する。
→Post lexical:単語の境を越えて適用され、対照的でない音(異音:allophone)を生じる。
→Post lexicalの規則はL1からL2に頻繁に転移するが、lexicalな規則はあまり転移しない。
・Eckman & Iverson (1995):L2学習者がL1では異音であるL2音を習得したいとき、L2音韻プロセスにおけるL1のpost lexical規則の適用を抑制しなければならない。
④Speech learning model (Flege, 1995):初期のL2学習者がL1音韻一覧にないL2音に出会った場合、それにいちばん近いL1音を当てる。よりL2に触れることで、徐々に新しい音韻カテゴリー(発音するためのgestural
scoreやmotor program、そして心的表象)を構築する。
→L2音素の習得はL2音とそれに類似するL1音の間の音韻的違いによって制限される。学習開始の年齢や、L2使用の頻度も習得に影響を与える。
→Flege et al. (1998):モデルの検証。20名の英語NS、40名の西英バイリンガル。[t]で始まる60語を発音。英語とスペイン語の同語族も含める。
⇒L2能力のレベルにかかわらず、参加者は音を産出する際に、語彙的要因(同語族、頻度、familiarity)による影響は受けなかった。ただし一般化には注意が必要。
●Syllableについて:音節の産出はL1をL2に転移すること、また普遍的有標性や普遍的制約の影響を受ける。L2の音節の分節規則の習得は、新しいL2音韻特徴の学習と同時に起こる。学習者の音節構造の習得は、直線というよりU型である。(Abrahamsson,
2003の例)
●Stressについて:L1の語や文におけるストレスがL2発話においても強く影響する。
→Archibald (1997, 1998):accentual言語とnonaccentual言語を母語とする人の英語の発話。⇒ accentual言語の母語話者がL1をL2に転移。nonaccentual言語の母語話者は転移できなかった。つまりL2のそれぞれの語彙項目のストレス細目をL2の中に保存し、ストレスの配置ルールに基づいて計算しているわけではない。
→accentual言語の母語話者がトーンのある (tonal) 言語を学習する場合、L1のトーンの知識を転移。(構造レベルを超えた転移)
●Intonationについて:L1をL2に転移する傾向。イントネーションにより表現される態度もL1の価値観に基づくと考えられる。
12. Summary of Phonological Encoding Processes (pp. 120-21)
●L2音韻の心理言語学的分野の研究は少ない。
●目標言語にアクセスする際、使用されていない言語の翻訳等価の音韻形式も活性化され、活性化は使用されていない言語のレマからその音韻形式にカスケード的に拡散する。
●2言語間で音素が同じ場合、上級話者は記憶表象を共有する。異なる場合、L1/L2音素の共通のところから引き出す。
●L2音素は個別に学習され、語や音素を構成する音の組み合わせは一つの単位ではない。
●音韻の習得における研究の中心は、L1の影響であるが、転移を生じる要因については研究者間で一致していない。
(鳴海)
ディスカッション&コメント
・ 本文中のgestural scoreは調音時の調音器官の位置を意味するのではないか。(たとえば調音点や口の開き方など)。Motor
programはそれらを動かす機能をもつものと推測される。
(鳴海)
・ Poulisse (1999)が議論するL1とL2の音素の関係性については、バイリンガルのレベルによっても、バイリンガルが使用する言語のペアの違いによっても異なる見解が見られるように思える。更なる研究を待ちたい。
(今野)
・ 音韻習得に関して、L2⇒L1という流れが主なものとして本論では研究されているが、L1からの転移に関しても興味深いと言えるだろう。 (平井)
ページトップに戻る
2008/01/11
Chapter 6 Monitoring (pp. 122-130)
1. Introduction (pp. 122-123)
■ モニタリングの3つの心理言語学モデル
①editor theories:
・Editorが発話産出プロセスにおけるアウトプットの誤りを拒否したり修正できる。
・アウトプットをチェックする規則の独自の体系がある。
・誤りがおきるのは、editorが用いる規則体系が不完全、またはその時点で適用される規則が様々であるから。
⇔editorはプロセスの最終的なoutcomeしかチェックできなく、中間レベルでの誤ったアウトプットを阻止できない。
○ Laver (1980), Nooteboom (1980):処理体系のそれぞれの段階に特化したモニターが存在し、それがそれぞれの処理のoutcomeの正確性をチェックしているのではないか。
→このモデルはdistributed editor theoryと呼ばれる。
②activation spreading theory:
・発話の知覚は活性化のボトムアップの流れを通じて処理されると仮定される。
・モニタリングはボトムアップの活性化拡散の自動的な副産物 (by-product)である。
⇔多くの誤りが話者によって見逃されるのはなぜか、モニタリングがメッセージの語用的
不適切さや情報の不十分さを知覚するということを説明できない。
③ PLT (perceptual loop theory):最も詳細で信頼できる理論である。
・発話理解システムが他者の発話と同様自分の発話にも向けられ、プロセスを検査する3つのループが存在する。
a) 発話前プランが基となる話者の意図と比較される。
b) 発声前にメッセージがモニターされる。(covert / prearticulatory monitoring)
c) 発声後にも発話がチェックされる。
■これらのモデルの検証はL1だけでなくL2においてもなされ、学習者の発話における自己修正
(self-repair) の様々なタイプや、統語的構造、修正のタイミングなどの分析と関連している。
■モニタリングの研究は、学習者が発話処理の異なる側面にどのように注意を配分しているかを明らかにするのにも役立つ。また学習者に目標語の知識の誤りに気づかせる点においても重要である。
2. Monitoring Processes in L2 (pp. 123- 130)
■L1/L2において話者の自己修正の分析がモニタリングの分野においてもっともなされている分析である。(自己修正は最も明示的なモニタリングである)
■話者自身による修正は、話者がアウトプットの誤りや不適切さを感知し、発話の流れを止め、修正をおこなう。しかし、多くの場合、話者は発声の前に誤りに気づき修正する、またはそのまま発話する。
→この二つの現象はモニタリング研究における方法論的な問題を引き起こす。
■隠れた修正 (covert repair) は実験的環境での口頭報告を伴う場合にのみ追求可能である。また修正がなされなかった場合は、発話ではなく後の振り返りにおいてのみ分析可能である。
■本節では様々なタイプの自己修正を生じる心理言語的プロセス、また修正の構造やタイミングが自己修正の産出における認知メカニズムの何を明らかにするかについて議論する。モニタリングの自己修正の分野においては、若干修正を加えたPLTが最適なモデルである。
■修正のタイプの分析(Levelt, 1989; Levelt et al., 1999に基づく):
<概念的段階での修正>
①different information (D-) repair:現在のメッセージとは異なった新しい情報を符号
化しようとする。
○Levelt (1983):異なる情報を選ぶ2つの理由
→意図したメッセージの一部の変更が必要である。(例1)
→メッセージの情報内容が不適切または不正確であることが明らか。(例2)
・もう一つの理由として、ある場合においては話者が最初に意図したメッセージを破棄し、まったく新しい物に置き換えることが考えられる。(例3)→ 問題解決ストラテジーと類似。コミュニケーションストラテジーにおけるメッセージの修正は、もとのメッセージが発話されない場合、発話前プランがformulatorにおくられる前に処理が起こる。
② appropriacy (A-) repair:現在のメッセージの情報内容に修正を加えようとする。
・①と似ているが、話者がもともと意図していた情報を修正された方法で符号化するという点で異なる。
・話者が適切性の修正を行うとき:
(a) 不正確(例4)
(b) あいまいな情報が特定化されなければならない(例5)
(c) 一貫していない用語を用いる(例6)
(d) 語用的に不適切な言語を用いる(例7)← Bredart (1991)によりrepair
for good languageとして分類される。(語用的で正しい言語修正)
○Kormos (1999):語用的・正しい言語の修正は、異なるものである。語用的修正は文脈の意味と関連し、よい言語の修正は表現の洗練に関するものである。(例8)
<言語的誤りの修正>
③error (E) repair:発話前プランは正しいが、メッセージが形成されるときに誤った語が活性化されたり、不適切な統語構造や誤った音素が選択されたりした場合。
○Levelt (1983):語彙的(例9)、統語的(例10)、音韻的(例11)修正と呼ばれ、Leveltモデルのそれぞれの処理レベルに対応する。
○Kormos (1999):3つ目の修正メカニズムのタイプとして、rephrasing repair(言い換え修正)を考案。
→誤り修正 (error repair) とは異なり、同じ発話前プランが出された際、発話前プランの修正はされるがメッセージの内容は変更されない。L2話者が自分の発話の正確さに自信がないとき用いる(コミュニケーションストラテジーと類似)(例12)。
→言い換え修正は能力の問題であるが、誤り修正はパフォーマンスにおける過失である。
■自己修正のタイミング:
・語の認知は、語の開始後200msで生じる。これに基づくと、明示的な修正において、誤りの感知からcutoff
point(修正点?中断点?)までの最短は200ms。
・自分の内的発話の認知は約150msであり、音韻プランの配信と発声までの時間は200~250ms。→ 話者は最大で100msの発声前モニタリング時間があるが、発話の誤りを防ぐのに十分かどうかはわからない。その場合、誤った語は発声開始の直後に中断される。誤り開始と中断店の時間は200msより短い。
・Levelt (1989, 1993)のモデルで並行した処理 (parallel processing) が可能なように、articulatory
bufferには発声のために用意された処理済のマテリアルがすでにあり、その結果、話者は発声前に誤ったアウトプットを阻止できる。(covert
repair)
○Blackmer and Mitton (1991):Levelt (1989)の検証。Error-to-cutoff / cutoff-to-repairの間隔が短い(<150ms)修正を多く見つけた。
→発話の際プランがこの時間内に起こるとは考えにくい。話者は発話の流れが遮断される前に修正処理を開始しているのではないか。
→Error-to-cutoffとcutoff-to-repairの間隔は速い修正においては有意な負の相関。
→遮断点は、誤り認知の点として信頼できる測定値ではない。Cutoff-to-repairの間隔は発話の再プランに遣われる時間と等しくならない。
○Hartuiker and Kolk (2001):コンピュータのシュミレーションを用い、遮断と修正が同時的で並行した処理かを検証。
→遮断とプランが並行した場合にタイミングのパターンがコンピュータにより再現できた。
→L1モニタリングのタイミングの研究より、遮断と修正のプランが同時的に進むだけでなく、非常に短い遮断時間がdistributed
editorの存在を証明することにはならないことがわかる。(distributed editor
modelでは、感知は最低でも200msかかると仮定され、並行処理が許可されていない)
■L2における自己修正のタイミング研究:
○Van Hest (1996):オランダ語話者の母語、英語の発話の3つのタスク(絵の描写、物語、面接)における自己修正のコーパスを用いる。
→音韻的誤りは感知され修正されるのが語彙的誤りより速い。不適切な語は認知されるのが一 番遅い。Levelt
(1989, 1993)モデルでは、音韻的誤りの修正ルートがもっとも短く、ほかの誤りのタイプや不適切なものはオリジナルの意図に対して概念化装置でのチェックが必要である。
→この研究においても、L2話者のcutoff-to-repair間隔はL1の発話より長い。それはL2産出における自動化のレベルが低いためではないだろうか。
○Kormos (2000):30名のハンガリー人の英語話者。3つの熟達度レベル。
→error, appropriacy, different-information repairにおける感知時間の差を考慮しても、activation spreading theoryとPLTの両方が支持された。
→語用的に不適切な語と語彙的誤りの感知の速さは同様だった。つまりモニタリングの間に語彙の語用的特徴は音韻的・意味的形式と同時にチェックされ、またargument
structureも同様である。
→語彙入力 (lexical entry) は意味的細目だけでなく、語用的価値に関する情報も含んでいることを間接的に証明。
→言い直しをする際に、発話の正確さについて話者が自信がない場合は感知スピードがかなり遅くなるため、誤りと言い直しの修正の区別の必要がある。
→言語形式(error / rephrasing repair)や発話の情報内容(appropriate-level-of-information
repair)における若干の修正は、メッセージの情報内容(message abandonment
repair)のような大規模の変更よりも少しの時間しかかからない。(less processing
effort)
→error repairとrephrasing repairにおける発話の再プランに必要な時間が類似していることから、L2話者はアウトプットの正確さについて自信がないときには心理言語的にもっとも単純なストラテジーを用いているといえる。
■自己修正の構造研究:
・自己修正の統語的構造が体系化されているかについては、自己修正の大勢が特定の規則にしたがっていることがわかっている。
→Well-formedness rule(Levelt, 1983):もともとの発話<O> + 修正<OR>は、発話を完成させるためにゼロまたはそれ以上の語<C>のつながりがある時かつその時に限り、well-formedであり、<OC
または R>の連なりはwell-formed である。一方、CはOの最後の要素を直接的に支配する構成素の完成形である。
→つまり発話と修正は統語的な規則に従う。(例13はwell-formed、例14はill-formedの例)
■L2の自己修正のwell-formednessの研究:
→この点においてL1とL2での違いはあまりない。
→Levelt (1983)に従うと、Van Hest のコーパスではL2自己修正の80%はwell-formedであり、Kormosのデータベースでは87.3%がwell-formedの規則に沿っていた。
→L2学習者の自己修正の行動はwell-formednessの規則にしたがっているといえる。
→これらの規則は発話産出のモジュールモデルの観点においてのみ説明可能である。(修正の際、L2学習者がL1話者と同様に発話プランの関連部分を再処理し、活性化拡散理論で仮定されているように、産出の中間段階から発話を再スタートしないため)
(鳴海)
ディスカッション & コメント
・ pragmatic repairとgood language repairは異なる。pragmatic repairは場面に合った言葉を選んだときなどの修正であり、good language repairは同じ言葉を使わないようにする、などの修正のことである。
・ 1980年代あたりに、Leveltがどのような手法をもちいてmillisecond単位を測ったのかという点で話し合いが行われたが、結局結論は出ていない。原本を見て調べる必要がある。
(森本)
ページトップに戻る
2008/01/25
Chapter 6 Monitoring つづき (pp. 130-36)
3. The Role of Attention in Monitoring L2 Speech (pp. 130-132)
■Schmidt (1990, 1993, 1994; Schmidt & Frota, 1986):学習が起こるには、インプットへの意識的なattentionが不可欠である。
■Robinson (1995):気づいたインプットの後にワーキングメモリーにおいてリハーサルが行われることで、インプット⇒インテイクとなる。
■VanPatten (1990, 1994, 1996; VanPatten & Cadiorno, 1993):インプット処理において形式と内容の間でattentionがどのように分配されるかを検証した。
■先行研究ではワーキングメモリの制約により、attentional resourceには制限がある。L2の発話処理においてはこの制限の役割が重要である。メカニズムは部分的に自動的であり、他は意識的な制御(つまりattention)が必要である。
■モニタリングにおけるattentionの役割は、特定の自己訂正の種類の頻度に関する問題を除いてあまり研究されていなく、またこれらの研究ではattentionの分配は重要視されていない。さらに自己訂正の種類の頻度を割合を用いて分析しており、統計的分析を行っていない。もう一つの課題としては、誤りの頻度と訂正の割合、そしてそれらが自己訂正の頻度とどのような関係があるかを検証していないことがある。
■課題はあるが、L2学習者は文法的正確さよりも語彙的正確さにかなり多くのattentionを分配していると考えられている。
■L2自己訂正の研究より、メッセージの情報内容に関する訂正の頻度は、タスクタイプにより異なることが明らかになっている。(Poulisse,
1993; van Hest, 1996)
■Kormos (2002):30名のハンガリー語学習者(3つの熟達度レベル)と10名のハンガリー語の母語話者の協力で、自己訂正の分配、頻度、誤り訂正の割合を調査。
⇒情報交換タスクでは、学習者は情報内容の適切さと言語的正確さに同等のattentionを分配していた。語彙的誤りと文法的誤りの訂正の割合も同じくらいだった。
→しかしこれらの結果は、学習者のattentionが語彙的適切さと文法的正確さのモニタリングの間で等分されているということを示しているわけではない。(暗示的な
(covert)訂正については調査していないため。)
→振り返りの調査により学習者はL2の訂正をする際意識的な判断をしていると述べている。これらの判断は、場面における正確さの要求度、コミュニケーションにおいて誤りがどのくらい深刻な妨げとなるかについての学習者の認識、訂正が発話の流暢さをどのくらい低下させるかという要因の影響を受けるということ。
→一般に言われているようなattentionが言語形式よりも情報内容に向けられているという主張はすべてのタイプのL2学習者には当てはまらないかもしれない。
4. Monitoring and SLA (pp. 132-135)
■自己訂正の回数や性質を言語能力の発達やメタ言語的気づきと比較する研究がL1とL2において行われてきた。
⇒習得プロセス初期においてはメタ言語的気づきに制限があるため、初級学習者は上級学習者よりも多くの誤りや修正を行う。言語能力の発達に伴い、メタ言語的気づきも向上し、学習者の誤りも少なくなり、誤ったアウトプットの訂正率も上がる。
■Herhoeven (1989):55名のオランダに住むトルコ人児童におけるL2自己訂正と言語学習プロセスの関係を2年間調査。
⇒音韻的訂正やrestartの数は6~7歳の間に大幅に減少したが、その後安定する。Restartや意味的訂正の数とL2熟達度に有意な正の相関がどの年齢においてもみられた。しかし統語的訂正の数は6~8歳の間でのみ増加した。
⇒Evans (1985)のL1自己訂正において自己訂正の数とタイプは子どものメタ言語的気づきやオーラル言語熟達度と関連しているという主張を支持する結果。
■O'Connor (1988):異なる熟達度におけるL2自己訂正を検証するため、フランスでフランス語を学習するアメリカ人の初級学習者3名と上級学習者3名を分析。
⇒熟達度の低い話者はより多くの訂正を行い、高い話者の訂正はコミュニケーションにおける障害を避けるために用いられ、談話レベルの訂正と関連するのではないかという仮説。この仮説が支持された。また訂正の性質は2タイプの学習者の間で異なったが、訂正の数はかわらなかった。→ 初級話者における自動性
(automaticity) の欠如が問題を避けるプラン技術の能力や機会を減少させたのではないか。上級者については自動性が高まることでこのストラテジーのためのattentionが解放されるのではないか。
■Lennon (1990):上とは異なる結果。イギリスに6ヶ月間在住後、参加者の発話速度は上昇し、ポーズの数は減少したが、初期のころよりも訂正の回数が増加。
→言語能力の向上とともにモニタリングや自己訂正のためのattentionが使用可能になるのではないか。
■Van Hest (1996):初級と中級学習者は同じ回数の自己訂正をしたが、上級話者の訂正はかなり少なかった。→ 初・中級話者はtrial-and-errorの段階にいるが、上級話者はよりerror-freeの段階に近いからではないか。
■Kormos(2002):モニタリングへのattentionの配分を調べるため、語彙的誤りの訂正と文法的誤りの訂正を分析。
⇒メッセージの言語的正確さへのattention量はSLAの異なる段階において一定であった。上級者の発話符号化メカニズムの自動性レベルが高いため、話者はモニタリングのためにさらなるattentionを向けることができ、発話の談話レベルの側面をチェックできる。
■これらの先行研究より、L2熟達度が高まると同時に、単純な誤り訂正からより複雑な談話レベルの訂正へのシフトがおこるが、全体的な自己訂正の回数とL2能力レベルには関連がないといえる。
■上級話者はより多くのL2に関する宣言的知識を持っていることで、初級者よりも能力の欠如による誤りは減少し、初歩的な言語的誤り訂正は少なくなる。その一方、上級者はL2についてより詳しいだけでなく、それらの知識をより効率よく適用することができる。言語スキルの発達とともに、意識的にコントロール可能な知識(使用の際誤りになりがちな知識)が徐々に自動的で無意識的な過程(規則や記憶に基づいた)によって代わられる。
■練習により、刺激と反応の結びつきは強くなる。特に語彙の抽出や作成済みの(prefabricated)チャンクにおいてそうである。→ 誤ったレマを活性化してしまうことで生じる語彙的言い間違えが上級話者の方が少なくなる。
■自動的処理はattentionを必要としないため、attentional resourceは他の発話段階へと向けられることが可能になる。そのため上級話者は談話や内容レベルのモニタリングに注意を向けることが可能になる。
■モニタリングの役割はSwain (1985,1995)のoutput hypothesis(一般的なアウトプットとpushedアウトプットがSLAを促す)との関連からも研究されている。多くの研究者は、モニタリングはアウトプットの産出と同様に、attentionと意識的な処理の両方に関連するため、次のような理由で習得の効率を高めると述べている。
①L2モニタリングは、学習者の既存の言語システムに対して行われる内的及び外的発話のチェックと関連し、またPLT(perceptual
loop theory)において、理解のプロセスと同様であると仮定されることから、L2学習者は産出的知識よりもより安定し信頼できると考えられる受容的知識を用いることができる。モニタリングに用いられる受容的知識はL2使用においては安定しているとは限らない。→ギャップの気付きを促し、さらなる習得プロセスのきっかけとなる。
②知識におけるギャップに気付くだけでなく、誤りに単に気付くこともL2学習の助けとなる。
・Robinson (1995):気付きは長期記憶における符号化に先立つ短期記憶における発見とリハーサルに関連している。
モニタリングに関しては誤った項目が発見され、error-freeの解決が長期記憶に保存される前にリハーサルされる。このような記憶痕跡は宣言的知識の手続き化やmemorized solution、そして様々なレベルの処理の結びつきを強化することに寄与する。
③L2における自発的な訂正は、聞き手の確認(confirmation)や明確化(clarification)における訂正と基本的に同じである。(前者は話者が誤りに気づき、後者は聞き手が誤りに気付くという点で異なる)pushedアウトプットと同様、自発的な訂正も同様にL2についての仮説を検証し問題解決のきっかけとなり学習者の既存のリソースを拡大するのである。
(鳴海)
コメント&ディスカッション
・習得プロセス初期ではメタ言語的気づきに制限がある、と書かれていたが、初級者はメタ言語的気づきの制限よりも、知識不足のほうが影響が大きいのではないだろうか。
・また、4節のところはメタ言語的気づきのことに冒頭で述べていながらも、そこで紹介されている先行研究ではメタ言語的気づきについてのことをあまり支持していないように思えた。上級者でも下級者でも訂正の数が変わらないというのは、例えば上級者はgood language repairが多く、下級者はもっと下位レベルでの訂正が多くなりそうである。これは知識不足によるものなのか、それともメタ言語の気づきが足りないためなのか?
(森本)
ページトップに戻る
2008/02/08
Chapter 7 Problem-Solving Mechanisms in L2 Speech (前半pp. 137-146)
1. Introduction (pp. 137-8)
■ L1の会話においては問題を迅速、かつあまり労力を遣わずに解決できるが、L2話者は意味の交渉(negotiating meaning)やコミュニケーション中に起こる問題に対処するために多大な時間と労力を費やす。→ L2の問題管理(problem management)はL2理論における重要な問題。
■本章ではL2発話産出におけるproblem managementについて概観する。
■Dornyer and Scott (1997):問題にかかわる3つの原因
(a) 情報や知識の不足 (resource deficit)
(b) 処理時間のプレッシャー
(c) アウトプットにおいて認識される欠陥
■本章の構成:①問題解決メカニズムの定義と特徴、②L2話者がどのように発話の問題を扱うかについての分析(Poulisse(1993)の枠組みに基づく語彙的コミュニケーション・ストラテジー、文法的・音韻的問題解決メカニズム、処理時間のプレッシャー、)、③L2画k集におけるコミュニケーション・ストラテジーの役割
2. Review of Definitions and Characteristics of Communication Strategies (pp. 138-40)
■communication strategies (CSs):Selinker (1972)によりはじめて用いられる。
<CSsの4つの見解>
①Traditional view (Dornyer and Scott, 1997):あるコミュニケーションのゴールを達成する際の問題を解決するための意識的なプラン。
②Interactional view (Tarone, 1980):必要となる意味が共有されていない場合、話者が意味を一致させるために相互に努力すること。
③Extended view (Dornyer and Scott, 1997):コミュニケーションの最中に言語に関する問題と意識していることに対処するためのすべての試み。
④Psycholinguistic view (Poulisse, 1997):最初のプランが符号化できないとなったときの代替プラン。
⇒ここでは④の定義を採用。
■Dornyer and Scott (1997)のCSの2つの定義の基準(Problem-orientedness /
consciousness)において研究者間で意見が一致しない。
■Problem-orientednessの4つの分類(Dornyer and Scott, 1997)
(a) Resource deficit:メッセージを言語化するのを妨げる知識のgap
(b) Own-performance problem:自己訂正メカニズム
(c) Other-performance problem:meaning negotiation strategies
(d) Lack of processing time
■CSsに関連するconsciousnessについての3つの側面(Dornyer and Scott, 1997)
(a) 問題の気づきとしてのconsciousness
(b) 意図 (intentionality)としてのconsciousness
(c) 方略的言語使用の気づきとしてのconsciousness
誤りや言い間違いと異なる点は、CSsを用いる際は話者がメッセージの符号化において問題があるということに気づいている点である。Intentionalityも無意識のポーズや躊躇と区別する必要がある。
■L2発話産出の特別な特徴をLevelt (1989) モデルに組み込むことで、L2使用における問題解決メカニズムの包括的枠組みができる。
①resource deficit:発話前メッセージのプランと符号化における3つの問題解決プロセスと関連。
(a) 語彙的問題解決メカニズム:発話前プランにおいて特定の概念に対応する適切なL2レマを抽出できない。
(b) 文法的問題解決メカニズム:文法的形式の知識が不足。
(c) 音韻/発声の問題解決メカニズム:音に関する知識が不足することで音韻的符号化や発声段階に問題を生じる。
②処理時間のプレッシャーは、L2発話処理が(少なくとも部分的には)連続的で、L1に比べてより多くの注意や処理時間を要するということと関連している。時間を稼いだり、処理により多くの注意を注ぐために、L2話者はさまざまなstalling(行き詰った)メカニズムを適用している。
3. Lexical Problem-solving Mechanisms (pp. 140-46)
■Levelt (1989) によると、発話形成プロセスは語彙中心であり、文法的や音韻的符号化は語彙のエントリーを介している。→ 学習者が直面する多くの問題は語彙に関連するものである。
■Poulisse (1993):
・Levelt (1989)に沿った語彙的コミュニケーション・ストラテジー:
概念化装置でメッセージをプラン→発話前プランを発信→形式化装置(formulator)が発話前プランに沿ったレマを抽出できないために、発話産出プロセスが止まり、モニターに警告シグナルを送る→概念化装置に情報が戻る→発話プランが修正され、概念化装置が新しい発話前プランを発信→形式化装置が処理、または前述のメカニズムを設定する。
・語彙の抽出が困難な場合は2つのオプションのどちらかを用いる:
(a) もとの発話プランを破棄または変更する。→3つの方法で実行
①message avoidance:意図されるメッセージ全体を諦める(破棄する)。
②message reduction:意図された内容を部分的に消去する。
③message replacement:意図された内容を部分的に他の要素と置き換える。
→問題の根源を解決するのではなく、問題を回避してコミュニケーションが行き詰るのを避ける。
(b) マクロプランを変更せずに発話前メッセージのみを修正する。
→lexical compensatory strategiesの基盤となる3つの心理言語学的プロセス。
①substitution strategy:新しいレマを検索する際、発話前メッセージにおける概念細目が変更または消去され、もとの語彙項目が他のものに代わられる。
②substitution plus strategy:レマの概念細目の修正に加え、話者はL1またはL2の形態的/音韻的符号化プロセスを適用する。
③reconceptualization strategy:発話前メッセージの一つ以上のチャンクを変更する。
⇔Kellerman and Bialystok (1997):Poulisse の分類に沿ってこれらのストラテジーの明示的な兆候を分類するのは容易ではない。
■substitution strategies:Poulisse (1993)が主な例としてcode-switchingとapproximationを挙げている。
・code-switching:L2の発話における意図的なL1の使用は発話前プランの中の語彙的概念に付与された言語タグのパラメータをリセットする必要がある。(
[+L2]ではなく[+L1]を選ぶ)
・approximation:1つまたはそれ以上の概念特徴が消去、または代替される。
もう一つのsubstitution strategy
・all-purpose-word:多くの概念特徴は除去され、一般的な特徴( [OBJECT], e.g.,
thing, thingie)や[CAUSE TO HAPPEN], e.g., "make", "do")のみが残り、聞き手は意図された意味を再構築するために文脈のヒントを用いる。
■substitution plus strategies:Poulisse (1993)はforeignizingとgrammatical word coinage(新造語)を挙げる。
・Literal translationはこの分類に当てはまるか??(literal translation:話者ははじめに符号化したい概念の[+L2]タグを[+L1]で置き換え、L1の語彙エントリーができるようになると、その要素を別に考え、対応するL2レマをひとつずつ抽出し、今までメンタルレキシコンに存在しなかった新しいL2の語彙エントリーを作る。)
→literal translationでは形態的または音韻的符号化ではなく語彙的符号化によって代替処理がなされる。しかしliteral
translation, foreignizing, word coinageは同じ心理言語的プロセスを経るわけではない。Literal
translationは語彙的符号化を含むための "plus"要素まで拡大する点でsubstitution
plus strategiesに分類される。
■reconceptualization strategies:Poulisse (1993)は例として、circumlocution(婉曲表現→話者は意図した語彙項目の概念特徴を別々に符号化し、発話前のチャンク全体を変更する)、
semantic word coinage(2つの語彙アイテムが選択され、1つの語にまとめられる)、
mime(phonoligical problem-solvingで述べる)を挙げる。
⇔Kellerman and Bialystok (1997):Poulisse (1993)の3分類はsubstitutionとreconceptualizationストラテジーの明確な区別をしていない。(定義のような構造
"Stuff to kill flies"、例を列挙することで上位概念を表す "tables,
beds, chairs, and cupboards"でFURNITUREを表す)
■どのくらいの語彙的概念がこれらの言語化の例に当てはまるかは疑問であるが、その概念的あいまいさを解決するにはreconceptualizing strategiesを変更の数にするのではなく、より "reconceptualization"の本来の概念に近づける必要がある。Kellerman and Bialystokの例は、概念的にあまり明確ではない語彙アイテムの抽出以上のものを必要としている点で、substitution strategyとは異なる。(語彙項目の組み合わせによって表現するために発話前チャンクのanalysisとdecompositionが必要である)
■analysis, decomposition(分解), recombination(再結合)がreconceptualizationの概念として要約される。
→mictroreconceptualization(一つの発話前チャンクの概念化を要する)とmacroreconceptualization(発話前メッセージの一つ以上のチャンクの修正を要する)を区別できる。
⇒restructuringはmacroreconceptualizationの枠組みに置き換えられる。
例) "On Mickey's face we can see the … so he's he's wondering"
■まとめ:語彙的問題解決メカニズムは、話者のレマ抽出の問題に対処する試みといえる。Poulisse
(1993)に習うと、それらの問題はsubstitution strategiesに分類され、一つまたはそれ以上の概念特徴(subsituation
plus strategies, microreconceptualization strategies, macroreconceptualization
strategies)の変更と関連している。
(鳴海)
コメント&ディスカッション
・さまざまな用語が使用されているが、それぞれの違いや類似性について説明が欲しい。
・また、どのタイミングでどの方略がしようされているのか、どの時点でプランが立てられているのか(伝えたいメッセージを考えるときなのか、メッセージに対応する発話を考えるときなのか)などを理解するのが難しい。
(中川)
ページトップに戻る
2008/02/29
4. Grammatical problem-solving mechanisms (pp. 146-47)
■文法的符号化における問題は符号化プロセスの3つのポイントで生じる。
①発話前メッセージにより活性化されたレマが、任意的または強制的なcompliments,
specifiers,diacritic valuesがないか検査されるとき。
②これらのcompliments, specifiers,diacriticパラメータが処理されるとき。
③句や節がまとめられるとき。
■レマの文法的な形式や構造の十分な知識がないため、メッセージが本来のプラン通りに符号化されることが妨げられ、話者は問題解決メカニズムが必要になる。
■文法的知識の不足における問題解決メカニズムの分類:
(a)grammatical substitution
文法的な形式や構造においてレマの特定の特徴を変更する。2つの方法。
→対応するL1やL3レマの統語情報を用いる(転移)。
→似たようなL2レマの統語情報を用いる(過剰一般化)。
*Faerch and Kasper (1986) のsubsidiary transferに類似。
(b)grammatical reduction
話者が意図的に単純化された文法を使い、聞き手が文脈から意図することを再構築することを期待する。
5. Phonological problem-solving mechanisms (pp. 147-50)
■適切なレマが抽出され、文法的な処理の段階も経た後に直面する音韻的符号化の問題は主に3つある。
①韻律の枠組み(metrical frame)を作ることができない。
②L2話者がある語のlexemeを適切に習得していない場合、情報や音素の特徴を付加したいときや、枠組みにそれらをあてはめる際に問題が生じる。
③話者が分節化され、韻律的に特定されたphonological stringsを音韻または発声プログラムにマップする際に問題が生じる。?
■音韻的符号化における問題解決メカニズム:
(a) phonological retrieval
話者が不完全な音韻情報からlexemeを抽出しようとする。
→言い間違い(tip of the tongue):いくつかのバージョンを発話しテストする。
(b) phonological substitution
話者がある音韻的特徴を代替的に使用(言語間/言語内転移)することによって問題のある語彙項目を符号化、発声する。
→similar-sounding words:発話前のチャンクに合うレマを見つけても、それに伴うlexemeが抽出できないときに、もとの項目に似た音の連なりを産出し、聞き手に目標語を連想してもらう。
・Levelt (1995):lexemeの音韻情報は2種類(語の韻律(アクセントのパターン)と語の形態素の断片)あり、音韻的断片は固定されているわけでなく、発話の中で正しい韻律の位置に挿入されなければならない。
⇒つまりsimilar-sounding wordsは韻律的に本来のlexemeと似たものであり、一つまたはそれ以上の音韻的断片が置き換えられたものと考えられる。
(c) phonological reduction
→mumbling:意図的に理解不能の語を問題のある語彙項目の場所に挿入する。聞き手がそれを推測するのを期待する。
問題のある音韻的断片が適切に置き換えられるのではなく、飲み込まれてしまう点で、similar-sounding
wordsとは異なる。
6. Time pressure-related problem-solving mechanisms (pp. 150-52)
■L2話者の発話産出はL1よりも自動化されていないため、符号化処理が連続的になり、その結果より多くの時間がかかる。
■処理時間の必要性は発話処理の2つの段階で生じる。
①メッセージの内容や形式が作られる際の、マクロ/ミクロプランニングの間。
②発声されるメッセージを構築するために発話前プランが処理されるとき。
■話者が発話を産出するのに、その場面で許容される時間よりも長くかかると認識した場合、次の3つのオプションがある。
(a) プランニングや処理による躊躇を避けるために、メッセージを縮小または棄却する。
(b) もともとの発話前プランの符号化よりも速く符号化できるように代替的な符号化メカニズムを適用し、他のresource deficit関連のストラテジーを用いる。
(c) コミュニケーションのチャネルを開いておき、より多くの時間を確保するために、さまざまなstalling mechanismsを用いる。
→nonlexicalized pause:unfilled pause (沈黙)、umming/erring(あー、えー)、sound
lengthening/drawling(母音を伸ばす)
→lexicalized pause:filler (you know, actually, how can I say that…)
→repetition:self-repetition(直前に言ったことを繰り返す)、other repetition(話者の発話の一部を繰り返す)
7. Communication strategies and language learning (pp. 152-53)
■コミュニケーション・ストラテジーは、知識不足を補ったり、能力が不足していることを信号として送ったりするものとしてとらえられ、L2学習者はL1のストラテジーをそのまま転移して用いることができるので、明示的な教授の必要はないと考えられてきた。
⇔Dornyei (1995):コミュニケーション・ストラテジーが教授可能であると主張。ハンガリーでの実験により、CSsを教えられた生徒の方がCSsをより用いることが分かった。
→CSsは流暢さを高め、コミュニケーションを続けるために役立ち、より多くのアウトプットが出される。そこで学習者がL2に関する仮説を検証し、問題を解決し、既存のリソースを拡大することでL2習得を促す。
■Poulisse and Schils (1989):3グループが異なるタイプのタスクにおいて用いるCSsの違いについて検証。
⇒上級学習者はCSs少ない。上級者は知識のギャップが少ないからではないか。
上級学習者はapproximationを多用する傾向。
中級学習者はL1に基づいたストラテジーを多く使う傾向。
8. Summary
省略
(鳴海)
ディスカッション & コメント
・diacriticとは識別する、というような意味とのこと。ではdiacriticパラメータとは?
・grammatical substitutionで、似たようなL2レマの統語情報を用いるところで「過剰一般化」と書いてあったが、必ずしも過剰には当たらないのでは?正の転移であることもあるのではないか。
・ストラテジーを教えることで、上級者になってもストラテジーを使ってしまうのではないか、という点について議論がなされた。
(森本)
ページトップに戻る
2008/03/14
Chapter 8 Fluency and Automaticity in L2 Speech Production (pp. 154-65)
1. Introduction (p. 154)
■L1の産出と異なり、L2の産出には話者の注意が必要であり、そのため産出のスピードがかなり遅くなる。先行研究においてもspeech
rateとlength of runsに関してL2はL1よりもかなり低いことが分かっている。要因としては様々なことが考えられるが、本章ではautomaticityの程度に焦点を当てる。
■L1では発話プランのモニタリングにおいてのみ注意が必要とされ、それ以外は自動的かつ並行的に無意識に行われる。
■L2では、初心者は統語的/音韻的符号化が自動化されていない、また、上級者においても部分的にしか自動化されていないということもある。automaticityの不足によりL2産出のプロセスはL1のような並行的なものでなく、発話を遅くする。
■本章は、automatizationの観点からL2の発話産出の流暢さについて議論する。
2. Definitions of fluency (pp. 154-56)
■Lennon (1990, 2000):流暢さは2つの意味がある。
①一般的なスピーキング能力(広義)
②スピーキング能力の一つの構成要素(狭義)
■Fillmore (1979):流暢さは4つの異なる説明からなる。(広義の例)
流暢な話者は・・・
①ポーズをいれずに長く話すことができ、話し続けることができる。
②躊躇せずに、また一貫性・合理性を伴い、意味的に深く (semantically dense)
話すことができる。
③幅広い文脈において話すことができる。
④言語使用において創造的かつ想像的である。
⇔ 一般的なスピーキング能力とどのように異なるのかが明確ではない。
■Sajavaara (1987):流暢さは、発話行為のコミュニカティブな容認性 (communicative acceptability) またはコミュニカティブな適合性 (communicative fit)である。(広義の例)
■Lennon (1990):流暢さは、オーラル試験における他の得点(e.g., 正確さ、適切さ)とは異なり、発話プランと発話産出の心理言語的処理が容易にかつ効率よく機能しているかという聞き手の印象である。また流暢さは話者が完成した発話を提示することによって、聞き手が自分のメッセージに注意を向けさせる能力でもある。
■Rehbein (1987):流暢さは、プランと発話の活動が、話者によってほぼ同時的に実施されることを意味する。また流暢さは文脈、つまり話者の聞き手の期待に対する評価にもよる。
■Schmidt (1992):Lennon (1990)に次のことを加える。発話産出における流暢さは、自動的な手続き的 (procedural) スキルであり、流暢な発話は自動的で注意や労力を要しない。
■Lennon (2000):流暢さの実用的な定義は、オンライン処理の時間的制約がある中で、速く、スムーズに、正確に、明快に、考えや意図することの効率的な言語化ができること。
⇒ Kormosはこの定義を支持。
3. Theories of automaticity and the development of L2 fluency (pp. 156-62)
■L2の流暢さの発達は、符号化プロセスの自動化と定型表現 (formulaic language)
という2つの相互に関連した処理と関与している。
■自動化と学習は3つの異なる方法で生じる。
(a)意識的に学習された言語ルールは、話者が注意を必要としないで適用できるようになる。
(b)統語的・音韻的ルールを用いて組み立てられた句や節は、後に記憶において一つのまとまりとして蓄積され、そのまとまりごと抽出される。
(c)学習者は、はじめは統語的・音韻的ルールの適用を意識せずに記憶されたチャンクを用いるが、学習段階のあとの段階には、それらの言語のまとまりから規則を推測する。
■ACT (adaptive control of thought), ATC-R (adoptive control of thought-revised)
theory (Anderson, 1983, 1995):
・自動的な処理の発達は、ルールの迅速な適用とrule-basedの処理からのattentionの撤回
(withdrawal) に関連するだけでなく、マクロプロダクションの構築(小さなまとまりからのチャンク)や一般化(適切な文脈においてルールが適用できる範囲の拡大)、そして差別化
(discrimination) (適切な文脈においてのみルールを適用する)にも関連している。
・しかし、この理論を流暢さの発達に適用するための研究は少ない (Raupach, 1987; Schmidt, 1992)。
・Towell et al. (1996):Andersonの理論をLevelt (1989)モデルと関連付ける。→ 手続き化
(proceduralization) が生じる唯一の論理的な場所はLeveltモデルのformulatorであり、その役割はメッセージに言語的な型を与え、この符号化されたメッセージを発声することである。fluent
runの平均が長くなり、ポーズの平均が不変、または短くなり、発声時間の割合が不変、または長くなれば、手続き化が生じていると仮定。⇒ 2人の参加者のアウトプットを詳細に量的分析し、流暢さの変化は学習者が統語的知識を手続き化するのに成功しているからであると結論付けた。
・Poulisse (1999):3つの熟達レベルのオランダ人の英語学習者の言い間違いを研究。⇒ 低熟達度の学習者がより多くの言い間違い(多様なパフォーマンス)あり。手続き化は主に語彙アクセス、動詞の形態的符号化、音韻的符号化のプロセスにおいて生じている。
・RaupachはACT theoryを認めてはいるが、それをそのままL2学習に適用することに注意を促す。SLAにおいては手続き的知識がすべて宣言的知識を介して符号化されているわけではなく、場合によっては直接的に手続き化したり、L1の手続き的知識を転移したりする。学習者によってはL2構造をimitation(未分析の言語単位)で習得する場合もある。
・McLaughlin (1990)のtheory of L2 learning:ACTmodelとCheng (1985)のtheory
of restructuringを基盤。はじめに発話産出プロセスの自動化が生じ、その後、再構築
(restructuring) が続く。これがL2学習におけるU-shaped behaviorを説明。← このU字型の発達が流暢さ獲得に適用されるかは議論されていないが、初級学習者が限られた量の記憶に頼って、容認可能なスピードでコミュニケーションを図ることは理論的に考えられる。しかし長期的な研究はされていない。
■instance theory (Logan, 1988):ACT, ACT-Rの理論とは異なる。宣言的→手続き的という知識の変換が学習のすべてではない。自動的処理は記憶の抽出と同じと仮定。アルゴリズムの使用が記憶からの一度の抽出によってとってかわられることで自動化される。
・Robinson and Ha (1993):文法性判断において学習者はalgorithm-based メカニズムと記憶抽出のどちらを用いるかを検証。⇒ これらは二者択一的ではなく関連しており、両方が自動化の発達に寄与している。
・DeKeyser (2001):Palmeri (1997)のexemplar-based random walk model(記憶ベースの学習理論の一つ)の方が伝統的なinstance
theoryよりもより良い説明ができるのではないか。
・Pawley and Syder (1983):母語話者的な流暢さは、決まったパターンや定型表現(記憶からまとまりとして抽出されるもの)がどのくらい使用できるかで決まる。流暢さは自動化だけでなく、適切な表現の記憶抽出とも関連している。
・Wray (2002):L2学習における定型表現の研究。このプロセスは自然な環境にある子どものL2学習者にもみられる。先行研究では自然な環境と教室の環境のどちらでも、大人の学習者は定型表現を分析せずに記憶し、コミュニケーションを図るために用いることが分かっている。学習段階の後期にはL2話者(特に教室環境)は、これらのまとまりを分析し、規則を導きだし、それらの規則と定型表現を創造的に活用する。
・定型表現の研究からチャンキング理論が実証的に支持される。つまり、スピーキングのような認知的スキルは、小さなまとまりからマクロプロダクションを構築することで学習され、またまとまりとして記憶されたチャンクから言語規則を抽出することが可能であることがいえる。
・これとは逆のプロセス(rule-based処理から産出した一連の語を練習することで記憶のまとまりとして蓄積し、抽出すること)は可能かという課題。
→Wray (2002):語彙習得のモデルから、このプロセスが可能であることを示唆。⇒ L1話者は大きなまとまりを必要以上には分けないが、L2学習者(post-childhood)は小さな単位から出発し、それらを組み立てる。インプットの中で句や節に出会うが、学習者が気づき、利用しようとするのは単語であり、またそれらがどのように結び付くかである。教室環境の学習者は個々の単語に的を絞り、それ以外の重要な情報を捨ててしまうのである。
■strength theories of automatization:L2産出の語彙的符号化の自動化と流暢さの発達に関連。効率的に語を抽出するためには、概念と語の強い結びつきが構築される必要があり、検索メカニズムがone-stepの直接的抽出にならなければならない。
→この理論は、練習により概念と語彙アイテムのリンクが強化されると仮定。(第3章において、語彙抽出の自動化は、視覚的、または他のタイプのインプットにより活性化された概念が、対応した語彙ノードを最も高いレベルで活性化するときに達成されることが述べられている。)
→定型表現がどのように学習されるかについても説明。学習初期には語と語の結びつきが弱いため、学習者のアウトプットが多様になる。学習により語と語の強い結びつきが構築され、定型表現がまとまりとして抽出されるようになる。
・Oppenheim (2000):6名のNNSsの英語の繰り返しの発話を調査。⇒ まったく同じフレーズを繰り返すのではなく、学習者は部分的に重複したもの(新しい要素を加えたり、順序を変える、組み合わせて大きなまとまりにしたもの)を用いていた。instance theoryを用いると、2回目にはまったく同じ発話が期待されるが、結果はinstance theoryを不支持。→ strength theoryとtheories of chunkingが繰り返しの多様化を説明できる。
・T. Ullman (2001):メタ分析による神経言語的側面から、語彙的・統語的処理について、NS/NNS、初期/後期学習者、熟達度が高い/低い学習者の自動化を検証。
⇒ declarative/procedural modelについて:語彙的記憶に蓄積された音‐意味のペアにおける記憶・蓄積・処理は、宣言的記憶により補助されている。一方、文法の側面に関する学習・表現・処理は手続き的記憶に依存する。思春期後にL2学習を始めた話者、特に言語使用の練習が十分でなかった場合、文法処理について宣言的記憶に頼る傾向がある。つまり手続き的記憶の自動的計算メカニズムを用いる代わりに、ひとまとまりとして言語形式を記憶し、宣言的記憶において意識的に規則を適用する。これは新しい形式にパターンを一般化する連想的語彙記憶の能力を使用しているといえる。
・Ullmanの研究は広く支持され、このモデルは学習が宣言的知識→手続き的知識という変換を通じて生じるという点でACT theoryと類似しているが、語彙と文法学習に異なる計算システムがあると仮定するconnectionist theoriesとは異なり、このシステムは幅広いanatomic distributionがあると主張する。
4. Measures of L2 fluency (pp. 162-65)
■L2学習者の発話の流暢さに関する4つのアプローチ:
①時間的側面(temporal aspect)
②時間的側面+相互作用的特徴(e.g., turn-takingメカニズム)
③音韻的側面
④定型表現の分析 ←もっとも新しいアプローチ
■実証研究で用いられる3つの手法:
①長期的な流暢さの発達を調査
②流暢な話者と非流暢な話者の比較
③流暢さのスコアと時間的変数との相関をみる
*多くの研究において参加者の数は少なく、統計的分析やコンピュータ技術によるポーズの判定はなされていない。
■よく用いられる時間的変数の例。(Table 8.2.)
■先行研究によると、流暢さを最も予測する指標はspeech rate(音節数/分)とmean length of runs(0.25秒以上のポーズ間の発話における音節数の平均)である。Phonation-time ratio(発話を産出するためにかかった時間に占める実際の発話時間の割合)も同様に良い予測指標とされる。
■filled/unfilled pauseの数や繰り返し・言い直し・修正などのdisfluencyに関しては明確な結果が得られていない。(参加者少ない研究ではsilentとfilled
pauseの数が流暢さを区別したが、参加者の多い研究ではfilled/unfilled pauseと流暢さに相関低)
■非流暢なL2話者の発話で、disfluencyはまとまりになって生じるが、流暢な話者のポーズは文法的な句切れにある。
■Riggenbach (1991):流暢さは文脈に依存していると仮定し、流暢さの時間的変数と相互作用的特徴を分析。⇒ topic initiations, back channels(相槌), substantive comments, latching(連続発話), overlapping, amount of speechが流暢さの判断にある程度関与している。
■Hieke (1985):音韻的研究。流暢な発話=連続発音 (connected speech) である。連続発音にはconsonant
attraction(最後の子音が次の語の最初の母音にひきつけられる)などがあり、これはインフォーマルなNNSの発話における流暢さの指標となりえる。
■Wennerstrom (2000):イントネーションが流暢さにどのように影響を与えるかを、英語のNNSとNSの会話から分析。⇒ 流暢さに影響するのは、発話が長いとかポーズが短いとかではなく、一語ずつの発話でなくフレーズことに発話できる能力である。
■Vanderplank (1993):pacing(強勢のある語の数/分)とspacing(強勢のある語/総語数)は、リスニング教材の困難度において、speech rateの指標よりもより良い流暢さの予測指標である。
■Kormos and Denes (2004):どの変数がNSとNNSの教師の流暢さの認識を予測し、L2話者の流暢さを決定するか検証。16名のハンガリア人英語学習者(2つの熟達レベル)の発話をコンピュータを使ったポーズの判断を用いて分析。⇒ すべての教師において、speech
rate, mean length of utterance, phonation time ratio, number of stressed
words/minuteが最も良い流暢さの予測指標となった。しかし、それらが正確さ、語彙の多様性、ポーズの平均的長さにどのくらいの影響を与えているかは、評価者間で異なった。filled/unfiledポーズの数や他のdisfluencyの現象は流暢さの認識に影響を与えていなかった。
5. Summary (p. 165)
■流暢さには、一般的なスピーキング能力と時間制限のある現実的コミュニケーションにおいてスムーズに話す能力の2つの意味がある。
■本章ではLennon (2000)の「オンライン処理の時間的制約がある中で、速く、スムーズに、正確に、明快に、考えや意図することの効率的な言語化ができること」を流暢さの定義とする。
■L2話者が流暢になるためには、3つのプロセス(①統語的・形態的・音韻的符号化処理の自動化、②小さな言語単位から定型的まとまりを構築する、③未分析の単位として記憶されたチャンクから規則を導く)を考慮する必要がある。
■Anderson (1983, 1995)のACT, ACT-R theoryは言語規則の自動化を説明するのに適切であり、strength theoryとtheories of chunkingは定型表現の習得の説明を提供する。theories of chunkingは記憶された単位から、多様な言語規則がどのように推測されるかも説明。
■最も流暢さを予測できる時間的指標はspeech rateとmean length of fluent
runsである。 (鳴海)
ディスカッション & コメント
・ポーズの長さで0.25sが長いのかどうかが議論になった。談話分析などでは0.2sでも記録したりするが、L2で話しているときの0.25sはどうなのだろうか。
・また、fluencyの定義についての議論があった。 (森本)
ページトップに戻る
2008/04/07
Chapter 9 Conclusion: Toward an Integrated Model of L2 Speech Production 前半(pp. 166-73)
1. The general characteristics of the bilingual speech production model (pp. 166-69)
■本章で提案するバイリンガル発話産出モデルは、モノリンガルの発話処理の中でも最も実証的に支持されているLevelt (1989, 1999)の発話産出モデルに基づくものである。
■バイリンガルの発話産出は別々の符号化モジュール(conceptualizer, formulator,
articulator)からなり、それぞれが独自の特徴を持ったインプットにより機能する。
■L1産出と同様にL2産出も漸次的に機能する。
■特定のレベル以上の学習者においては、並行的な処理が原則可能であるが、符号化処理に意識的なコントロールが必要な場合は、符号化は連続的にしか生じない。
■このバイリンガル発話産出モデルは、完全な連続的モデルであるというわけではない。活性化されたが選択されていない語のノードが活性を低いレベルの音韻ノードに拡散することもある。しかし、このモデルはレベル間での活性化の逆の流れを許可せず、またモニタリングは発話理解システムを用いてなされる。
■Levelt (1999)モデルの3つのknowledge stores:
①外的・内的世界の知識
②メンタルレキシコン
③音節文字表 (syllabary)
■新モデルにおいては、長期記憶という一つの大きなメモリ記憶 (memory store)が存在し、その中にエピソード記憶、意味記憶(メンタルレキシコンを含む)、音節文字表、L2規則の宣言的知識が含まれる。(Fig. 9.1参照)
・エピソード記憶:一時的に整理された出来事や経験したエピソードの保存
・意味記憶:言語的・非言語的概念やそれらの概念から連想される意味に関連した記憶痕跡を含む。階層的構造を持ち、3つのレベル(概念、レマ、レキシム)がある。レマレベルは統語的情報、レキシムレベルは形態・音韻的情報を持っている。
・音節文字表:音節を作るために用いられる自動化されたgestural scoreを保存。
■これらすべてのknowledge storesはL1とL2で共有されている。しかし、L2に特有なものとして、L2の統語的・音韻的規則のための宣言的記憶を保存する場所がある。
■T. Ullman (2001):神経画像の調査により、文法に関する宣言的知識は、文法の自動化された規則の処理をする部分とは異なる脳の分野に保存されていることが分かっている。
■エピソード記憶と意味記憶は密接に関連している。エピソード記憶は概念を活性化し、逆も可能である。意味記憶の階層的な特質により、活性は概念→レマ→レキシムと拡散する。一方発話理解においてはこの流れは逆方向になる。
■宣言的知識を保存するということ以外は、バイリンガルの産出モデルはモノリンガル話者のモデルとはそれほど違いはない。
■Abutelebi et al. (2001, 2005):L2産出に関する神経画像の先行研究をまとめる。⇒ L1とL2の脳の活性化レベルにおいても、処理に関連する脳の部位に関しても、L2を早期に学習したバイリンガルと、広くL2に触れることがある上級L2話者の間では違いが無い。しかし、熟達度の低いL1話者や、L2に触れることの少ない学習者は、L1を話すときよりもL2を話すときのほうが広範でかつ異なる脳の部位を活性化した。
⇒上級バイリンガル話者は宣言的知識には頼らないが、初級話者は文法的・音韻的知識を異なるknowledge
storeに保存している。
2. Encoding mechanisms and the structure of knowledge stores in L2 speech production (pp. 169-73)
<概念化>
■L2発話処理はメッセージの概念化から始まる。L1とL2の概念は意味記憶の中に一緒に保存されていると考えられる。このモデルでは、概念は語の意味に関する情報からなる記憶痕跡の集合体であるとされる。概念が抽出されるとき、すべての記憶痕跡が活性化されるのではなく、文脈にあったものだけが活性化される。
■概念が記憶痕跡ネットワークを保持していることはL1とL2の概念が同じ、共有される、分離することがまれであることを容認する。
■L1とL2の概念がどのくらい共有されているかは、概念(概念の明確な名詞は共有される傾向があり、抽象的な名詞は重複が少ない)・L2が習得された環境(2言語が異なる環境で習得された場合概念が別々にある傾向)・話者の熟達レベル(初級者はL2概念がL1概念にmapされるが、上級者のL2概念表象は豊かである)によって異なる。
■言語の選択は大部分が社会言語学的要因(場面の性質、話者の関係など)に依存する。本モデルでは言語選択はlanguage cueという形で示されると仮定する。language cueはそれぞれの概念に別々に付与されるため、たとえば文が符号化される場合、発話前プランはそれぞれlanguage cueが付与された活性化された概念の一連から構成される。(独英バイリンガルの場合の例:The policeman fined the motorist.)
■Leveltの理論や活性化拡散の理論に従うと、本モデルは意味記憶において符号化したい概念だけを活性化するのではなく、意味的に関連している概念も活性化されると仮定できる。L1とL2の同じ語に対して異なる概念が存在する場合、話者が一つの言語を使用するともう一方の言語の概念も活性化される可能性がある。
■使用中の言語における意図された概念のみが次の処理へと進むが、それらは対応する語彙項目だけでなく、意味的に関連するレマ(使用中ではない言語のレマも含む)を活性化する。
■発話の大部分は記憶されている句・節・文の組み合わせ(定型表現)からなる。これはチャンキング(大きな産出の単位)が概念化装置のレベルにおいてなされているからであると考えられる。概念的なチャンクはそれに対応する言語的チャンクへと活性化を拡散し、またこれらは一つのまとまりとして保存・抽出される。
<語彙的符号化>
■本モデルにおける語彙的符号化とは、概念細目やlanguage cueをメンタルレキシコンにおける適切な語彙入力と組み合わせることを意味する。
■概念細目はL1とL2レマの両方を活性化し、両方とも選択のための競争にかけられる。競争に勝ったものがlanguage
cueを含むすべての概念細目を満たす特徴を持ったレマである。
■メンタルレキシコンはL1/L2のレマとレキシムを含んでいる。つまり話者の語形(レキシム)と統語・形態的特徴(レマ)の知識の保管場所となっている。
■バイリンガルのレキシコンは、L1とL2の単一の語だけでなく、概念的チャンクに対応する語の連なり(イディオム、様式表現、成句)も含んでいる。語の連なりは単一のエントリーを形成し、独自の統語情報を持つ。
■概念体系と同様、レキシコンもエントリーが互いに結びついているネットワークを持つ。結びつきはL1とL2のレマやレキシム、そして言語間の項目の間に存在する。
■頻度の高いL2エントリーはネットワークの中心に存在し、多くのほかのアイテムと結びついている。低頻度のL2はネットワークの周辺に位置する。
■結びつきの強さはそれぞれ異なる。初級学習者のL1とL2のリンクはL2同士のリンクよりも強いと考えられる。結びつきは非対称的であり、場合によっては一方向的である(受容語彙のようにL2を聞いたらL1で意味は分かるが、L2で産出はできない)。
<統語的符号化>
■L1産出における統語的符号化の2つの流れ:
①語彙項目に関連した統語情報(ジェンダー、加算性など)の活性化。
→L1話者は宣言的知識に依存する。
②活性化された語や統語的特徴を用いて節や句を組み立てる統語的符号化メカニズムの使用。
→手続き的知識を用いる。
■L2においては、統語的符号化の知識が制限される。
■本モデルでは、一般的な統語的符号化プロセスに関しては、L1とL2産出の間に基本的な違いは無いと仮定する。また統語的な処理はIncremental Procedural Grammar (Kempen & Hoenkamp, 1987、第二章のSyntactic Processingを参照)の段階に従う。つまり統語的符号化は語彙中心であり、明確に異なる段階によって構成されている。
①メッセージの最初の概念的チャンクに対応するレマの統語特性の活性化。
→上級バイリンガル話者の場合、L2レマはあるL2エントリーに特定の統語情報を示すが、初級L2学習者の場合は、L2レマはそれに対応するL1項目の統語情報を示す可能性がある。(L1転移の研究により実証されている)
→この段階でメンタルレキシコンに蓄積されている宣言的知識を引き出す。
②句や節の構造の構築と句の適切な整列。
→ L1話者や上級バイリンガル話者は統語的・形態的規則の(自動化された)手続き的知識を用いる。初級L2学習者は、自動化されている知識もあれば、意識的に用いなければならないような宣言的記憶に保存されている知識もある。また、まったく規則が習得されていない場合も考えられる。この場合はコミュニケーション・ストラテジーを用いる。
<音韻的符号化>
■音韻的符号化には、符号化すべき語の音韻形式の活性化、音節化、声の大きさ・ピッチ・複数の語のイントネーションの設定が含まれる。
■基本的なメカニズムはL1とL2産出において異なっていないが、L2処理における音韻形式の活性化に関しては、選択されていないレマの音韻形式も同様に活性化されると仮定される。またバイリンガルの音韻的符号化においては、L1とL2両方のレキシムが選択のために競争する。⇒ 活性化は使用されていない言語のレマからその音韻形式にカスケード的に流れる。本モデルでは、レマレベルとレキシムレベルの間ではカスケード的活性化が可能であることを意味する。
■音韻的な語形は語の音素を連続的に活性化する。音素は一つのまとまりとして保存されていると考えられる([+voice][+labial][-nasal]という特徴リストではなく、[b]のように一まとまり)。L1とL2の音素は、レキシコンのレキシムレベルで単一のネットワーク内に保存され、L1とL2で同じ音素を持つ記憶表象は共有される。一度習得されると、L1とL2で音素が異なる場合は、異なる表象として蓄積される。
■習得の初期にはL2特有の音素はそれと類似したL1音素と同等に扱われることがある。上級バイリンガル話者は音節化と韻律の符号化は同様に行われる。統語的符号化と同様、初級学習者は語彙的、音韻的規則の宣言的知識に頼り、それが不足する場合は、L1の規則を転移する。
<音声的符号化 (phonetic encoding)>
■音節の発声gestureが抽出される。L1とL2の音節プログラムは音節文字表に一緒に保存されている。de
Bot (1992)によると、初期のL2話者はほとんどL1音節プログラムに依存し、上級L2話者は、L2音節の異なるチャンクを構築している。
<モニタリング>
■モニタリングはL1とL2産出において似たような方法で行われる。
■Levelt (1989)モデルと同様に、3つのモニターループが産出プロセス監視の役割を担っている。
①発話前プランと、もともとの意図を比較する。
②発声前の音韻プランのモニター。(covert monitoring)
③発声された発話をチェック。
■誤りや不適切なアウトプットがいずれかのループで見られた場合は、モニターが信号を発信し、概念化のレベルから再び産出メカニズムを機能させる。モニタリングは発話理解のメカニズムと同じと考えられる。
■L1とL2モニタリングにおける大きな違いは、注意の必要性である。注意力には限界があり、L2の発話では、語彙、統語、音韻処理のレベルで注意が必要なため、L2話者のモニタリングへの注意の配分は小さくなる。そのためL2話者は注意の配分に優先順位をつける。多くの場合は内容>形式、語彙>文法(または逆もありえる)となる。 (鳴海)
ディスカッション & コメント
・ The policeman fined the motoristという文で、policemanとmotoristは+Englishで、finedは+Germanという記述があったが、これはどのようにして定めたのだろうか?実際にその脳の部位が活性化されていたということであろうか?(ただ、言語野の中で更に英語とドイツ語を分けた部位が存在するのかどうかも疑問である) (森本)
ページトップに戻る
2008/04/18
Chapter 9 Conclusion: Toward an Integrated Model of L2 Speech Production 後半(pp. 174-81)
3. Transfer, code-switching, and communication strategies in the bilingual speech production model (pp. 174-76)
■L1とL2発話産出における重要な3つの相違点:
①L2処理におけるL1の影響(転移やコードスイッチング)。
②L2知識の不足を補うためにコミュニケーションストラテジーを用いる。
③L1とL2のアイテムが競争したり、L2の知識が不足したり、また統語・音韻的符号化手続きが自動化されていないために意識的な処理が必要になるため、発話が構築されるスピードが遅くなる。
■転移とコードスイッチングにおけるL1の影響の2つ原因:
①L2の項目(宣言的知識)または手続き的な規則は習得されているが、目標語や構造の代わりにL1の項目や手順を誤って使用してしまう。
→これはL1とL2の概念、レマ、レキシム、音節プログラム、手続き化された規則が一緒に蓄積され、選択のために競争するために生じる。(初級バイリンガル話者は、L1を頻繁に使うため、L1の項目がL2よりも高い活性レベルにあるため、誤ってL1を選択してしまう。→語彙レベルでの無意識のコードスイッチング、文法や音韻に関する自動化された規則の転移、音韻的な言い間違いの原因)
②L2能力が不足しているため、母語の知識に頼らざるを得ない。リソースの限界のために、コミュニケーションストラテジーを用いたり、L2がL1と同様に機能すると考える。
→概念記憶において、L2語の意味が対応するL1の概念から連想させられる。(意味的転移)
メンタルレキシコンにおいて、L2レマがL1の翻訳等価の統語情報を指す。(統語的転移)
→統語的転移およびいくつかの音韻ルールの転移は、L2の句や文を符号化するためにL1規則の手続き的知識を用いることが原因となることもある。
■本モデルはKempen and Hoenkamp (1987) のIncremental Procedural Grammarに基づく。
→L2能力が不足している場合、あらゆる熟達レベルにおいて、すべてのL1の統語規則が転移できるわけではないと仮定。
■Pienemann (1998) のprocessability theoryに従うと、転移は習得階層 (acquisition
hierarchy) に
依存している。(L2学習者は階層の上位にあるL1の統語構造を転移できるようになる前に、その下位にある文法的符号化ができるようになる必要がある。)
意図的な語彙のコードスイッチング
■話者が発話前プランにおけるある特定の概念を表すL2細目をL1細目と意図的に置き換えるときに生じる。→ これが生じる理由:
・適切なL2語彙アイテムの知識の不足
・L1の語彙アイテムがL2語よりも概念的(意味的・語彙的)細目の条件を満たしている。
■Myers-Scotton (1993) の matrix language frame modelに従うと、コミュニケーションにおいて一つの言語がもう一方よりも支配的であり、発話の概念構造も使用中の言語に応じて組み立てられる。発話の概念構造が抽出される語順や、どのように文が組み立てられるかを決定する。
■発話内では、支配的ではない言語 (embedded language) のある概念のためのlanguage
cueを再度設定することも可能である。→ embedded languageにおけるその概念に対応するレマが抽出されるが、matrix
languageに関連する、またはmatrix languageのレマによって活性化される統語的手続きが文を符号化するために用いられる。
コミュニケーションストラテジー
■L2話者がコミュニケーションストラテジーを用いる4つの問題:
(a)知識の不足 (resource deficit)
(b)処理時間のプレッシャー
(c)自身が認識している言語アウトプットにおける能力不足 (deficiency)
(d)相手のメッセージの解読 (decode) において自身が認識している能力不足(発話産出よりも理解と関連)
■語彙的コミュニケーションストラテジーの3つのプロセス
(a)代替ストラテジー (substitution strategy):ある概念について適切なL2レマを抽出することができない場合、その概念の1つまたはそれ以上の特徴を修正する。
(b)代替ストラテジーと更なる段階の音韻・文法的プロセスを組み合わせて使用する。
(c)発話前プランによって特定された語彙概念を一つ以上修正する。
■文法的問題解決メカニズ:L2話者が意識的に、レマのある統語特徴を文法形式および項構造 (argument structure) の観点において、L1やL3からの転移やL2の過剰般化によって変更することを意味する。
■音韻的問題解決メカニズム:問題のある語彙アイテムについて、一つまたはそれ以上の音韻的特徴を置き換えることで符号化・発声する。
■L2の語彙・統語・音韻に関する知識の不足に加え、L2話者は制限されたattentional
resourcesのために実際のコミュニケーションの時間的な拘束の中でメッセージを処理できないという問題。
→Dornyei and Kormos (1998):その場合L2学習者は、メッセージを縮小または破棄する、知識の不足と関連したストラテジーを用いる、またはfilled/unfilled/lexicalized pauseや繰り返しなどのstallkingメカニズムに頼るといった方法をとる。(lexicalized pauseや繰り返しは、一つのまとまりとして記憶から抽出され、意識的な符号化を必要としないため、学習者のattentional resourcesを開放するのに役立つ)
■L2話者は自分の発話が正確か、適切か、聞き手にとって理解可能かどうかを決定する際にも問題を抱えており、それはモニタリングの段階で生じる。符号化プロセスが完全に自動化されていない、または記憶において適切に符号化されていない場合に生じる。その結果、学習者は自分の発話に誤りがあるかを判断することができない。
4. Developing of L2 competence in the bilingual mode (pp. 176-78)
■発話産出におけるL2能力の発達に関する学習の3つの重要な側面:
①宣言的知識の習得
②自動的符号化手続きの発達
③頻繁な刺激に対する応答の記憶
・factual information (事実に基づく知識) として習得される2つの基本的な知識のタイプ:
①意味・統語・形態・音韻・スタイル・語用・イディオム的特徴を含む語
②(少々の例外について)文法・音韻的符号化の規則 → 幼少期の場合、L2規則は宣言的知識という形で意識的には学習されない。
・いったん宣言的に規則が学習されると、手続き化が開始し、意識的に制御されていた知識の自動化が開始される。産出規則だけではなく、factual information (語など)の抽出プロセスも自動化される。
・一般的には学習段階初期においては、意図した概念に対応する語や、特定の語に関する統語・音韻的情報は検索メカニズムを用いて抽出される。熟達レベルの向上に伴って、これらの情報が自動的にアクセス可能となる。
・言語学習の重要な側面の一つとして、コミュニケーションでの意図の広い範囲を表現するために用いる、大きな産出単位の記憶もある。
■どのようにこれらの学習メカニズムがバイリンガル発話産出モデルに組み込まれるのか?
■語の習得とは語形(レマ)の記憶痕跡の構築と概念体系におけるレマの意味的指示対象の確立。
→習得段階の初期には、L2の語形は通常対応するL1概念の意味的特徴と結びついており、L2特有の新しい意味・スタイル・語用的特徴は習得プロセスの中で徐々に構築される。
■メンタルレキシコンに蓄積されている統語・音韻・形態的情報の習得には、同様に新たな記憶痕跡の構築が必要。場合によっては、L2学習者がL2レマと対応するL1レマの統語的(まれに音韻的)情報をはじめに結びつけ、後にL2特有の表象が発達するときもある。
■文法や音韻の規則に関する知識は、学習者に明示的に提示された規則を記憶することで習得される。そこで学習者は、文法と音韻のための宣言的知識の保存場所において、産出規則のための記憶痕跡を作り出す。
■規則はインプットの分析により演繹的学習されることもある。(宣言的な知識として規則が記憶され、それからそれを自動化する)
■自然的な環境および早期のL2習得においては、インプットを通じて直接的にルールが自動的に適用されることもある。
■文法・音韻的規則はformulatorにおいて手続き化される。質的・量的変化を通じて、規則の宣言的知識が自動的な手続きに変換される。(どのように生じるかについてはEncoding
Mechanisms and Structure of Knowledge Storesを参照)
■語彙的抽出および統語・音韻的情報へのアクセスは、インプットアイテムが対応する語彙・統語・音韻的ノードに最も高いレベルの活性化を拡散したときに自動化されると考えられる。
■factual informationの抽出に関する主要な自動化プロセスはインプットとそれに関連した情報の結びつきの強化と関連している。
■記憶された産出の大きなまとまりの習得はconceptualizerおよびレキシコンで生じると仮定される。学習者はまずL2における様々なコミュニケーション機能(会話の開始、別れ、依頼、謝罪、忠告など)を表す概念的まとまりを概念からのチャンクを作ることで構築する。次にチャンキング(?)、そして項目間の結びつきを強化する。学習を通じてレマ間において強い結びつきが構築され、定型表現を構成するレマが一つのまとまりとして抽出される。
5. Summary (pp. 178-79)
■本章は、L1とL2の発話処理の最新の知識を組み込んだバイリンガル発話産出モデルに関してであり、Levelt (1999) に基づき、修正を加えたものである。
■本モデルはモジュラーの原理に従っている。特定の機能においては専門的な処理モジュールが存在し、それらは完全に連続的なものではなく、語彙的符号化と音韻的符号化のレベルの間でカスケード的活性化が認められる。
■本モデルは産出メカニズムが基本的にL1とL2において同じであり、またほとんどknowledge
storesがL1とL2において共有されていると仮定している。
■L2産出に関して加えるものは、統語・音韻的規則の宣言的知識の保存である。
■LeveltモデルにおけるKnowledge storesも記憶研究の理論に従って多少再構築されている。このモデルでは、すべてのknowledge
storesが長期記憶内に位置し、4つの記憶体系(エピソード記憶、意味記憶、音節文字表、L2規則の宣言的知識)を持っている。意味記憶はさらに概念/意味的・統語的・音韻的レベルに分けられる。
■発話処理の様々な段階における、L1とL2処理の違い:L1とL2アイテムの競争、符号化の流れ、L2産出において不足する知識を補うメカニズムの必要性。
■2言語の分離は、概念化の段階で概念に対して付与されるlanguage cueによってコントロールされると仮定される。→ ある言語に特化した情報の符号化は、language cueと適切な項目のマッチングによって生じる。
■本モデルは、コミュニケーションストラテジー、コードスイッチング、転移についても説明し、定型表現の使用や符号化プロセスの発達も含んでいる。しかし、未完成な側面も多い。(特に統語的・音韻的符号化の分野や複数言語が混在した発話における統語的処理に関して)
■L2発話の習得の心理言語的プロセスにおける更なる研究によって、言語についての宣言的知識の記憶痕跡の発達や、rule-basedメカニズム、記憶された形式
(formulas) の構築に関する知識が洗練されていくだろう。
6. Recommended readings
省略
7. Glossary
省略
ディスカッション & コメント
・今回で本書のまとめが終了となる。
・用語について巻末のglossaryを見ることでこれまで解釈に不安のあった点が解決されるかもしれない。
・language cueについて、これまでにも別の用語(language tag)として出てきていたが、処理するさいに、ある語がどの言語に属するかをどのようにtag付けしているかについて検証方法が具体的に説明されていない。bilingual
activation modelなどでは、2言語において意味情報や音韻情報の活性化がどのように起こるかを反応時間や正確さの面から検証したりもしているが、tag付けについての検証方法はどのようなものがあるか、また、本当にtag付けされているかについて本書のみからでは理解が不十分なままであった。
(中川)

ページトップに戻る
ご意見やコメントがあればこちらまでお寄せください。