







![]()
| �l���Љ�Ȋw�����ȁ@���m�ے��R�[�X �@�ٕ������ꋳ��]���_ (Testing in Second Language Education) |
�ٕ������ꋳ��]���_�Ŏg�p���Ă���w��w�p�ꋳ��w��(2011).�@�p�ꋳ���S�@13���e�X�e�B���O�ƕ]���x
��C�ُ��X�@���|�[�g
![]() 2012�N4��18���@��1�́@�p��w�͕]���_�@(pp. 3-10) �S���FY.Y
2012�N4��18���@��1�́@�p��w�͕]���_�@(pp. 3-10) �S���FY.Y
��1�� �p��w�͕]���_
1�D����e�X�g�ɂ�����\���T�O
�e�X�g�́u�l�̍s���̓��L�̃T���v�����o�����߂Ɍv�悳�ꂽ����̂��߂̓���v�i�r�c�E��F�i�ďC�j, 1997: 24�j�ł���B����e�X�g�ɂ����錤���Ώۂ�
����Z�\�⌾��^�p�\�͂�����(measurement)
����\�͂�����(assessment)
�e�X�g�Ƌ���s���̊W��T�鋳���]���ievaluation�j
�e�X�g�Ƃ��̌��ʂ̏ȂɊւ���ϗ��K��̐����E�E�E�Ȃ�
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�ł���B
����e�X�g�Ƃ��̃f�[�^��p���Ă��ꎩ�g��]���E���f���邽�߂ɁA�M����(reliability)�E�Ó���(validity)���m�ۂ���K�v������BLongman Dictionary of
Language Teaching & Applied Linguistics (2002)�ł͂����̗v�f��
�@Reliability:�ca measure of the degree to which a test gives consistent results. A test
is said to be reliable if it gives the same results when it is given on
different �@occasions or when it is used by different people. (p. 454)
�@Validity:�cthe degree to which
a test measures what it is supposed to measure, or can be used successfully for
the purposes for which it is intended. A number of different statistical
procedures can be applied to a test to estimate its validity. Such procedures
generally seek to determine what the test measures, and how well it does so.
(p. 575)
�@�@�ƒ�`�Â����Ă���B�M�����͂��̃e�X�g�����肵�Ă�����̂̃X�R�A���ǂꂾ�����肵�A�M���̂�������̂ł��邩�������l�ł�����ɏd�v�Ȃ��́@�@�ł���B���l�Ƀe�X�g�쐬�̍ۂɏd�v�������w�W���Ó����ł���B�Ó������ɂ���ăe�X�g���_�Ƒ���Ώ۔\�͂̊֘A����������邽�߁A����e�X�g�@�@�����̔\�͂𑪒肵�Ă��邩���������߂ɑÓ����̓e�X�g��_����ɕs���ȗv�f�ł���B�p��̃e�X�g�̏ꍇ�A�u�p��́v�Ƃ����\���T�O(construct)���@�@��`����Ă��Ȃ���Ή��𑪒肵�Ă��邩�s���Ăȃe�X�g�ɂȂ�B���̂��߁A����\�́ie.g.��b�T�C�Y�A���@�́j�͈̔͂����肵�A���̍\�������A�@�@�����̍\���v�f�Ԃ̊W�t���𗝘_���������\���T�O�̒�`(construct definition)�m�ɂ��Ȃ�������Ȃ��B
����\�͂������邽�߂ɂ́u����\�́v�𗝘_�Â���K�v�����邪�A���̍ۂɂ͂��̍\���T�O���`�Â��Ȃ���Ȃ�Ȃ��B���̗��_�́u�X�̎��ۂ̔w��ɐ��ދK���������A�\���T�O��p���āA�������`�������ꂽ�@���Ƃ��Ē��A�X�̎��ۂ����̂悤�Ȉ�ʓI�@���̘_���I�A���Ƃ��Đ�������v���̂ł���B���_�Â��̂��߂ɂ͌��؉\��(verifiability)����������邱�Ƃ��K�v�����ł���A������m�ۂ��邽�߂ɐ�����(accuracy)�A��������(consistency)�A���(inclusiveness)�A�Ȍ���(conciseness)�����K�v������B�e�X�g�̎��p�̍ۂɋ������g����Ƃ�������������邽�߁A�Ȍ����͏d�v�ł���A�e�X�g�����p��(practicality)�ɒ�������B
���肷�邽�߂ɂ͒��ۓI�ȍ\���T�O�i���ꗝ�_�j����̓I�ɖ������Ȃ���Ȃ�Ȃ��B�R�~���j�P�[�V�����ւ̊S�E�ӗ~�E�ԓx�Ƃ����̂ł͒��ۓI�������A�ώ@�ҁi�̓_�ҁj�ɂ���ĕ]���̎�@�����قȂ�i�̓_�����M�����̌��@�j�ꍇ������A����̊ώ@�҂̏ꍇ�ł���т�����Ŋώ@���邱�Ƃ͓���i�̓_�����M�����̌��@�j�B��̓I�ȃ^�X�N��݂��A������w�K�ҁi�ҁj�ɍs�킹�邱�Ƃł͂��߂č\�z���ꂽ���ꗝ�_�ɂ���Ē�`���ꂽ����\�͂������邱�Ƃ��ł���B�^�X�N��ʂ��A�҂̔\�͂𐄎@(inference)���A���ꂪ�ǂ̒��x�K���m�F�����Ƃ�Ó����̌���(validation)�Ƃ����B����ł͉p��w�́��p����g����\�͂ƔF������Ă��邪�A����̊ϓ_����͌���ɊW����m���i�������j��r�����邱�Ƃ͂ł��Ȃ��BMcNamara(1996)�͍\���T�O�̒�`������ہA1) ����̒m�����K�����邱�ƁA 2)����̏�ʂŎ��ۂɎg����悤�ɂȂ邱�Ɓ@�Ƃ��Ă���B
�p����͂��߂Ƃ��錾�ꋳ��ɂ�����\���T�O�i�����ꗝ�_�j�́A����E�Љ�̗v�����ď�Ɍ`��ς��Ă���s�ς̂��̂ł͂Ȃ��B���̂��߁A�\���T�O�̒�`�Â��A�e�X�g�̑Ó������͕s���ł���B
2�D�p��w�͘_�O�j
���������ɂ͐��w���͂��߂Ƃ��邷�ׂĂ̊w�Ȃ͉p��Ŏ��Ƃ��s���A���ȏ����p��ŏ����ꂽ���̂ł������B���̂��ߊw�K�҂�content-base�Ŕۂ����ł��p����w����Ȃ������B�������A���̌�|�ꂽ���ȏ��A���{��ŋ�������w���҂����������Ƃ���w�K�҂̉p��\�͂����X�ɍ�������ێ��ł��Ȃ��Ȃ��Ă����B�u��O�̍��Z�E���w�Z�����p��̃��x���͖����E�吳���̕p�o���ނł������p��1�����x���ɑ�������v�i���E�]����, 2004�j�Ƃ���悤�A���������ɔ���X�ɉp��w�K�҂̕��ϓI�\�͂��ቺ���Ă��邱�Ƃ͔ۂ߂Ȃ��B���̂��߁A���a�����ɂ͉p��p�~�_����������悤�ɂ��Ȃ����B
�������̓����p��ł͌��q����A�lj��A�������A�p�앶�A�f�B�N�e�[�V�����A�p��b�̂悤�ȃ^�X�N���ݒ肳��A��I�ȉp��\�͂̑��肪�s���Ă������Ƃ��킩��B
|
|
Speaking |
Listening |
Reading |
Writing |
Grammar |
|
�c��`�m |
�� |
�� |
�� |
|
|
|
����p��w�Z |
�� |
�� |
�� |
�� |
|
|
���Ɗw�Z���w���� |
�� |
�� |
�� |
�� |
�� |
|
�������Ɗw�Z�\�� |
�� |
�� |
�� |
�� |
�� |
|
�����t�͊w�Z |
�� |
�� |
|
|
|
�⑫
Assessment�AMeasurement�AEvaluation�̒�`�ɂ���(Payne,
1997)
Assessment: A
term often used interchangeably with testing; but also used more broadly to
encompass the gathering of language data, including test data, for the purpose
of evaluation and making use of such instruments as interview, case study,
questionnaire, observation techniques.
Measurement: The
process of quantifying the performance of test takers. It is concerned with
systematic collection, quantification and ordering of information.
Evaluation: It describes a
general process of making judgments and decisions. The data used to make
evaluations can be quantitative and/ or qualitative.
(Payne, D. A.,
1997, Applied Educational Assessment. Wadsworth Publishing)
�@�@���؉\���ɂ��Ă̕⑫����
����w�͐l���w��Љ�w��1����ł���Ƃ݂Ȃ���邱�Ƃ��������A�`�����X�L�[���������@�����R�Ȋw�̈�A�܂�o���Ȋw�Ƃ��Ĉʒu�t�������Ƃ��@�@��A���f�[�^��p���Č��ꌤ�����s���ۂɂ́A���؉Ȋw�̎菇�ɏ]���Č������s�����ƂɂȂ����B
�@���R�Ȋw�̌����́A1�j�����̐ݒ�A2�j�����̎��ؓI�����A3�j���Ɋ�Â��ĉ������̑����ꂽ�ꍇ�̔��W�A�܂��͊��p���ꂽ�ۂ̉����ݒ�̂�蒼���A�Ƃ�������ɉ����čs����B���̂��߁A������[�߂�ۂɁA���̉ߒ��������O��A�������͗�����ɌJ��Ԃ���Ȃ���Ȃ�Ȃ��Ƃ����B���̂悤�ɉߒ����J��Ԃ���邽�߂ɂ͉��������؉\�Ȍ`�Őݒ肳��Ă��Ȃ���Ȃ�Ȃ��B�܂�A���؉\���Ƃ́A�����̐ݒ肪�ł�������̂��A�Ƃ������̂ł���B�Ⴆ�A�_�[�E�B���̐i���_�����\���ꂽ�ۂɂ͌����s�\�ł��������߁A���̗��_�͉Ȋw�I�ł͂Ȃ��Ƃ݂Ȃ��ꂽ���A���݂ł͈�`�q��͓���ʂ��A���؉\�ƂȂ��Ă���i�ΐ�A2006�j�B
![]() ��1�́@�p��w�͕]���_�@(pp. 10-20) �S���FR.F
��1�́@�p��w�͕]���_�@(pp. 10-20) �S���FR.F
3. �w�K�w���v�͉̂p��w�͂��ǂ̂悤�ɒ�`���Ă����̂�
�w�K�w���v�̂Ɍ���\���T�O, �u�R�~���j�P�[�V�����v�Ƃ����p��̞B����, �w�K�w���v�̂ƕ]����̐ݒ�
|
�N |
�ڕW |
���� |
���P�_ |
|
1947(��22) |
�p��ōl����K���A�����b���A�ǂݏ����A�p��b�ҁA���̏K���ɂ��Ēm�� |
|
|
|
1951(��26) |
4�Z�\�̓��� |
���ʔ\�̗͂Ꭶ���� |
|
|
1956(��31) |
�p�ꕶ�������E���ȕ������� |
��b���̋K�� ex) 1�N�F500-800�� ��̓I�Ȏw�����e���� |
���ȕ����ɂ��Č��y |
|
1958(��33) |
�����E��b�E���@����������ޗ��Ƃ���4�Z�\�ɂ��^�p |
���@�\���Ɋ�Â��V���o�X ��b���̎w�� |
a�w�����e�ʂ��K�� |
|
1969,
1970 |
|
�w�K���e�̍폜 ex) ���w
1100~1300 a 950 ~
1100 |
���k�̔\�͍��ɑΉ������w�� |
|
1977(���w) 1978(���Z) |
�����I�ȉp���p���ĊȒP�Ȏ�����b���A���� �����I�ȉp���lj��A���� |
�ȒP�ȁE�����I�ȁA���p�o |
���w�T3���ԑ̐��� �w�����e�E����ޗ����팸 |
|
1987(��62) |
���H�I�R�~���j�P�[�V�����\�̗͂{�� |
�w�K���i���y�� ����ޗ��̎����I�팸 |
�v��I�g�D�I�w����e�Ղɂ��� |
|
1998�i��10�j |
���H�I�R�~���j�P�[�V�����\�͏d���Ƌ��ɓ��ɒ��w�ŕ����A�b���A���d�� |
���w�F�@�\��100�� �@�@�@���ꐔ900�� |
��Ƃ苳�� �T5���� |
|
|
|
�ڕW������]�� �ϓ_�ʕ]�� |
n �p��w�͊ς̗��j
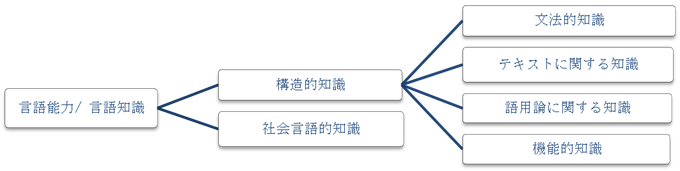
�e�X�g��������݂��\���T�O�̒�`�̗v�f�����邪�A�p��^�p�\�͂̒�`�A�e�v�f�̊W�t���邽�߂̒�`�������Ă���B
4. ����]�����������錾��\��
4.1 �\���T�O�Ƃ��̒�`�@--- �j�I�敪
n Chalhoub-Deville
& Deville(2005)�@a�{���ł͈��p
�@
�\�̓x�[�X�@�A�K�w�I�@�B�p�t�H�[�}���X�E�x�[�X�@�C�k�b�ɂ����鑊�݊W
n Bachman
(2007)
�@
�Z�\�Ɨv�f�@�A���ڃe�X�g�@�B��p�_�e�X�g�@�Ccommunicative
testing �D���ݍ�p�\�́@�E�^�X�N�E�x�[�X����^�p�e�X�g�@�F���ݍ�p��`
n Chapelle
& Brindley (2002)
�@
�����\���d���A�v���[�`�F����̌���g�p��ʂ�z�肹���A���ۓI�\�͂Ƃ��č\���T�O���`
�@�@�e�X�g�ł̌���g�p�͐��ݔ\�͂̌���
�A
�����^�p�d���A�v���[�`�F�ώ@���ʂ�����ۂǂ̒��x���ꂪ�g���邩�������邽�߃e�X�g���g�p
�@�@�@�@�@�@�^����ꂽ�^�X�N���v�����ꂽ��Ƃ��s���邩������
4.2�@�l�ɓ��݂��錾��\�͊ςɊ�b���������\���T�O�̒�`
4.2.1 �l�ɓ��݂���\�͂Ƃ��Ă̌���\�͊�
�O�R�~���j�J�e�B�u�̎���
n Lado
(1961): �S�Z�\�A�����A���@�A��b�B���������̉��l�ς̋C�Â�
�@�@�@�@�u�O���ꋳ�炪���ݏo������ő�̉��l�͋��炻�̂��̂ł���v
n Carroll(1968)
�@
����͋K���̑̌n�@�A����\�͂͑��݂ɊW����������A�̏K�����琬�藧�@�B������������\�͂�����^�p�ƌĂԁ@�C����\�́A����^�p�A���Ɍl������B
�E�h���E�����E�^�X�N�ɋ�̉����A���f�A��b�A�`�ԑf�Ɠ���ɉ����A���ׂĂ����������I����^�p�Ƃ��ĉ�b�E�����E�lj��E���C�e�B���O�\�͂Ȃǂƌ�����T�O��
�E�w���ƕ]���ƌ��ꂪ��̉����Ă�������
4.2.2 �n�C���Y�̃R�~���j�P�[�V�����\�͗��_
n Hymes(1971)
:
�E�@����\�͎͂Љ�œ�����o���A�Љ�I�j�[�Y�A�o���ɂ���đ��i�����A���@�A�o���Ȃǂ��܂�
�E�@�`�����X�L�[�̌��ꗝ�_�́A����̎Љ�I���ʂ��̏ۂ��Ă���Ɣᔻ
�E�R�~���j�P�[�V�����\�͂��u������g�p���邽�߂̔\�́v�ƌ��������邪�A�K���͕��@�\�͂̏K���Ɠ��l�̌�b�ŋL�q���邱�Ƃ��ł���A�Ǝ咣
n �n�C���Y�̃R�~���j�P�[�V�����\�͗��_�́A�o���Ȋw�Ƃ��Č��؉\���A�������A����ȂǗl�X�ȗv����Njy���悤�Ƃ��Ă���A����̌`�����Ƃ����`�����X�L�[�̎��݂�荢��ł���Ƃ����B
4.2.3 �O����K�������ɂ�����R�~���j�P�[�V�����\�͂̒�`
n 1980�N��A����z�肵���n�C���Y�̗��_���Q����K���ɉ��p���鎎�݂��s����
n Canale
& Swain (1980):
���@�\�́A�Љ��I�\�́A�����I�\�͂��R�~���j�P�[�V�����\�͂̍Œ���̍\���v�f�ł���B
n Canale(1983):
�E�\�͂���������^�p(performance)�̑���ɁA����g�p�̃T���v�������ۂ̃R�~���j�P�[�V����(actual communication)�Ƃ��ċ敪�B�n�C���Y���w�E��������O�v����ϋɓI�Ɋ܂߂��B


n Bachman
&Palmer(1983):
a����̉�݁A�����I�\�͂̑�����A�K�Ȍ���g�p���s����
��ӁF�s���Ȃǂł͂Ȃ��A�g�s�b�N�ɑ���ے�I����Ȃ�
n Schachter(1990):
�E�R�~���j�P�[�V�����\�͕͂��@�\�͂ƌ�p�_�I�\�͂��琬�邪�A�����I�Љ�I�K���͕��@�A���C�A����A��p�_���ׂẴ��x���ɉe����^����̂ł́H
�E�Љ��I�\�́E�����I�\�͂Ɠ��l�ɕ��@�\�͂��d�v
4.2.4�K�w�I����\�͘_
n Chalhoub-Deville
& Deville(2005)
�E�K�w�I����\�͘_�͎҂̌���\�͂Ɋւ���F�m�I�\�ۉ��̗��_�ł���A�Ƃ��ᔻ�I�B
�EACTFL�F�S�Z�\���T�i�K�ɕ����A�e�i�K���L�q�q(descriptors)�œ����Â���(CEFR,
can-do���ڂ�����)
a�\���T�O���K�w�I�Ɏ����ɏ\���ȗ��_�I�����A���ؓI�؋����f�������@�Ɣᔻ
n Hulstijn(2008)
�ECEFR
levels�̑�Ă��
�E����^�p�̂R��̉\���Fa. ����ꂽ��ʂł̎g�p�A�ǎ��̎g�p����A b. �L�͈͂̏�ʂł̎g�p�A����̎������A c.����^�p�͈̔͂Ǝg�p����̎�����v�@(CEFR��a,b,�̍l�������@)
a���
��P�i�K�F�@����g�p��ʂŕK�v�Ƃ����@�\���L�q�@�A�L�q���ꂽ��Ɛ��s�̂��߂ɕK�v�Ȍ���\�̓��x�����A�����Ɛ藣���Č���m���̃e�X�g���s��a�M�����A�Ó����̌����e��
��Q�i�K�F���i�҂̂ݑΏۂƂ��A����g�p��ʂƃ^�X�N��^���A�^�X�N���s���e�X�g�Ba�M�����A�Ó����̊m�ۂ�����
Chalhoub-Deville
& Deville(2005) A look at and forward to what language tests measure. In E.
Hinkel (Ed.) Handbook of research in
second language teaching and learning (pp. 815 ? 831). NJ: Lawrence
Erlbaum.
�\���T�O�̒�`�ɂ��āA�e������敪���čl�@�B
�@
�\�̓x�[�X�ɂ���`�i�O�R�~���j�J�e�B�u����j
n Lado(1961)
�\����`�I�A�v���[�`�ł���A skills(4�Z�\�Ȃ�)��elements(���@�A��b�A�����I�m��)�Ō���m���𑪒�B����Ώۂ�performance�i����g�p�j�ł͂Ȃ��Acompetence�i�\�́j�Ƃ����B
n Carroll(1986)
����e�X�g�Ƃ͌���p�t�H�[�}���X�𑪒肷�ׂ��B(1)����̓�����(���b�E�����\�͂�������)�@(2)�e�X�g�̐^����(authenticity,
real life)�̖ʁA�̂Q�_���d�����ׂ��B
n Canale
& Swain (1980)
L2�̍\���v�f�Ƃ��āA����m���݂̂Ȃ炸�A���p�I�m��(pragmatic
knowledge)��K�v�Ƃ����BCanale(1983)������Ƀf�B�X�R�[�X�\�͂��������B(�O�W����p.2�Q��)
n Bachman
& Palmer(1980)
Canale & Swain(1980)�̃R�~���j�P�[�V�����\�͂̑���W�������B����m���݂̂łȂ�����\�͂��܂݁Acommunicative
language ability (CAL)model�Ƃ��Ē�`�Â����B
�A
�K�w�I�i����\�́j�ɂ���`
ACTFL�͍L���p�����Ă������A�ᔻ������
ACTFL�Ɋւ���ᔻ
n �҂̃p�t�H�[�}���X���A�\�͂܂��͎������ł̌���g�p�̋K��(paradigm)�ƌ��ѕt���郂�f���������Ă���B
n ACTFL�̃K�C�h���C���͕\�ʏ�A�^�����Ɗw�K�҂����Љ�ōs���p�t�H�[�}���X�^�X�N���������Ă���悤�ɂ݂���B�������A���ۃK�C�h���C���́A��ʓI�Ő��k�̎��ۂ̕K�v�������邱�ƂȂ��I������Ă���B
������ �O��܂�
������
�p��͂Ƃ͉����Ƃ����u�\���T�O�v��, ���̑�����@�Ɋւ��錤�����T�ς���.
4. ����]�������ɂ����錾��\��
4.3 ������u�g����p��v�̍\���T�O�Ƒ���ɂ��� (pp. 21-29)
4.3.1
�p�t�H�[�}���X�e�X�g
n �p�t�H�[�}���X�e�X�g�Ƃ�
(Canale & Swain, 1980; McNamara, 1996)
�E4�Z�\����������g�p, �����^�̃e�X�g
�E�^����ꂽ�^�X�N���s���ߒ��œ���ꂽ����f�[�^���̂��̂�����\�͂ł��邱�Ƃ�O��Ƃ���.
�E�p�t�H�[�}���X�e�X�g�ɂ�錾��^�p�\�͂̋q�ϓI���肪�ǂ��܂ʼn\�Ȃ̂���, �̓_��, �]���, �^�X�N�Ǝ҂̌���^�p�Ƃ̊W���猟����Ă���.
n �p�t�H�[�}���X�e�X�g�ɂ�����^�X�N�̖���
<Bachman (2007) �ɂ�镪��>
[1] �҂����ݓI�Ɏ����Ă��錾��\�͂������o��
�@? ����\�͂͌l�̊w�K�҂ɓ��݂�����̂��ƌ��Ȃ� (Bachman, 2007), ���ݎ҂��ǂ̂悤�Ȕ\�͂������Ă��邩�𑪒�ΏۂƂ���.
[2] �����҂����ۂ̌���g�p��ʂŃ^�X�N���s�����Ƃ��ł��邩�𑪒肷��
�@? �����҂̎������̌���g�p��ʂŎg����\���̍����^�X�N��ݒ肵, ���̃^�X�N�����s�ł��邩�ǂ����������� (Norris et al., 2002).
<McNamara (1996) �ɂ�镪��>
[1] �����Ӗ��ł̃p�t�H�[�}���X�e�X�g: �҂�����ۑ�������ł��邩�ǂ���������̑Ώۂł���, ����\�͂����łȂ��F�m�E��ӁE�Љ�v���ȂǂɃ^�X�N�̊����x�͍��E�����. ����������, ����^�p�\�͂�K����������ł���킯�ł͂Ȃ�.
[2] �ア�Ӗ��ł̃p�t�H�[�}���X�e�X�g: �҂��猾��^�p�\�͂̃T���v������т���ɒ��ڊ֘A�����v�f���̎悷�邱�Ƃ�, ����^�p�\�͂𑪒肷��.
�R�~���j�P�[�V�����\�͂̍\���T�O�Ƃ���, ��\�� (e.g., �����I�\��, ��ӗv��) ���܂߂�Ƃ������g�݂���,
�����̗v�����ǂ̂悤�ɑ���ΏۂƂ���̂��͖����̌n������Ă��Ȃ�.
�@? �S��������g��Ȃ��e�X�g�͌���e�X�g�Ƃ͌ĂׂȂ�. �����܂�, ����\�́E����R�~���j�P�[�V������ (����, 2008) �𑪒肵�悤�Ƃ��Ă��邱�Ƃ�O���ɒu���ׂ�.
4.3.2 ����g�p��ʂɂ����鑊�ݍ�p����b�Ƃ����\���T�O
n �e�X�g�����ɂ����鑊�ݍ�p
�E����^�p�́u����\�͂���������у��^�F�m�����Ƒ��ݍ�p���邱�Ɓv�ōs����
�@(Canale &
Swain, 1980; Canale, 1983; Bachman & Palmer, 1986) �ƍl���闧��𑊌ݍ�p��`�ƌĂ� (Chapelle, 1998).
�E���ݍ�p�̌��ʂƂ��Č���\�͂��ω����邱�Ƃ͏\�����蓾�邽�� (Chalhoub-Deville, 2003), �������Ƃ̂����╶���̉e�����҂̃p�t�H�[�}���X�ɉe����F�߂闧���, ���Ƀ~�j�}���X�g���ݍ�p
(Bachman, 2007) �ƌĂ�.
n �ߔN�̑��ݍ�p��`
�E�Љ�����_
(Kramsch, 1986, 1998; Vygotsky, 1987; Lantolf, 2009) �̗�������ތ���^�p
�@���_�Ɋ�Â��l���Ƃ���, �u����^�p�\�͂�, �҂̓��ɂ�����̂ł͂Ȃ�,
���ݍ�p
�@�ɂ���č���鑊�ݍ�p�\�� (interactional competence) �ł���v�Ƃ���.
�E�܂�, ����\�͂͌l�̓��̒��ɑ��݂��� (McNamara & Roever, 2006), �w�K�҂̐��ݔ\�͎͂Q���҂Ƃ̂����̒��Ō�����Ƃ��闧��.
�@�@? �^�X�N�������ł������ǂ����ł͐��ݔ\�͂��ώ@���邱�Ƃ͂ł��Ȃ�.
�E���̗��_�����p�����e�X�g�Ƃ���, Johnson (2001) �̎��H�I��b�\�̓e�X�g (the Practical Oral Language Ability: POLA) ����������.
�@�@? ACTFL�̌����\�͑��莎���̂悤��,
�g�s�b�N�����O�Ɍ��߂��Ă���, �������ɂ���Ď��R�ȉ�b����������Ă���e�X�g�ɑ�, �P�Ȃ���̂����ł͂Ȃ�,
�Q���ғ��m�̑��݂̊ւ��𑪒肷��e�X�g.
4.3.3 �Љ�����_�̋���ςƃ_�C�i�~�b�N�E�e�X�e�B���O
n �_�C�i�~�b�N�E�e�X�e�B���O�Ƃ�
�E���ݍ�p��`�̌����Ɋ�Â����e�X�g���_�ł���, �e�X�̎҂������I�Ȏw���ƂƂ��Ƀe�X�g����Ƃ������� (Sternberg & Grigorenko, 2002).
�E�]���̐ÓI�ȃe�X�g
(static test) �ł�, �w�� (�t�B�[�h�o�b�N) �����邱�Ƃ̓e�X�g�̑���덷�ނ��߂ɔ�����ׂ����̂Ƃ��ꂽ��, ���̗��_�ł�, ���ݍ�p�ɂ���Đ��܂ꂽ�덷�����ꔭ�B (= ����\��) ��\���Ă���Ƃ���.
�@�@? ����̔��B�Ɖ^�p�͋�ʂ������̂ł͂Ȃ� (Lantolf, 2009).
�@�@? ����S������̃e�X�g�]�w���ɂ�����, ATI ���� (aptitude,
treatment, interaction: �\�͂�K���ɂ���Ă��̐l�ɓK�������������Ⴄ) �Ƃ��֘A����.
�����̎Љ�����_��, �]���Ǝw���̈�̉��Ƃ����_�ɂ����ė��z�I���ƍl������.
4.3.4 �p��w�͕]���ɂ�����Љ�����_�̖��_
1)
�Ҍl�̐��ݔ\�͂𐄑����悤�Ƃ��Ă�, ���ݍ�p��ʂɂ�����҂��ꂼ��̍v���x�_�����邱�Ƃ��ł��Ȃ�.
2)
���ݍ�p��ʂ͂��̏����̂��̂ł��邽��, �҂̕��ՓI�ȓ������ώ@���邱�Ƃ��ł��Ȃ�.
3)
�ҊԂɋ��ʂ̓������ώ@���邱�Ƃ��ł��Ȃ�.
4)
�������̔\�͂Ɏ҂̔\�͂����E����邽��, �҂̃����N�t���Ȃǂ͂ł��Ȃ�.
4.4 �`���I�e�X�g�̗L�����ɂ���
n �ߔN�̃e�X�g�����ł�, ����m���ł͂Ȃ�����^�p�\�͂Ɋւ���\���T�O���𖾂��邱�Ƃ�ړI�Ƃ��Ă���.
n ������, �S�Z�\�ƌ�b�E���@����Ȃ錾��g�p�\�͊ς����H�̏�ł͗L���ł��邱�Ƃ�O���ɒu���ׂ��ł���.
5. �Ӗ��̂���p��w�͂�]�����邽�߂ɕK�v�ȏ�����
5.1 ����Ɏc���ꂽ�ۑ�
n ����\�͂̒�`�ɂ���
�E�ǂ̏�ʂł��ǂ̖ړI�ɂ����v�����P��S�\�̕]���@��\���T�O�͑��݂����Ȃ�����,
�@���_�����ɂ�����, ������������ߓx�ȕ��Չ��͌��������ׂ��ł���.
�E�t��, �ɒ[�Ɍʉ���������\�͂̒�`��, �w�K�Ҍl�̌���\�͂̈�ʉ�����ł��Ȃ�
�@����.
n �\���T�O�̒�`�ɂ���
�E����\�͂Ƃ��ďd�v�ȗv�f�����̂ł͂Ȃ�, ���������ĈӖ��Â��邽�߂�
�@�g�g�݂��K�v�ƂȂ�.
�E�]���̊w�K�w���v�̂�, �K�����ׂ�����ޗ���Z�\, ���ʋZ�\�����X�g������ɂƂǂ܂��Ă�����, ����������u�R�~���j�P�[�V�����ւ̊S�E�ӗ~, �\���̔\��, �����̔\��, ����╶���̒m���E�����v�Ƃ����]���ϓ_���������͉̂���I�ł���.
�E����^�p�\�͂ɊԐړI�Ɋւ��m���̍\���T�O���`���邱�Ƃ��s�\���ł���. �O���ꋳ��ɂ�郁�^�F�m�̔��B�Ȃ�, �l�X�Ȓm��������ڕW�ƂȂ肤�����, �������\���T�O�Ƃ��Ē�`�Â����Ƃ��K�v�ɂȂ�.
5.2 �Ӗ��̂���p��w�͕]���Ɍ�����
�p��͂��ǂ̂悤�ɑ����Ă���̂������邱�ƂȂ��ɂ͈Ӗ��̂��鑪��͂ł��Ȃ����Ƃ�O���ɒu���ׂ�.
1. �p��w�͂̑���
1.1 ����̊�{�T�O
���p��w�͂̑���͋���@�ւ���Љ�ɂ����ėl�X�ȖړI����@�ɂ����{����Ă���B
������̊�{�T�O
�@�@measurement�F���m�ȋK���Ǝ菇�ɏ]���āA�҂̓����𐔗ʉ�������@
�@�@�@�@�@�@�@�@�@�����ʉ��F�ΏۂƂȂ�����ɐ��l�����蓖�Ă邱��
�@�Aassessment�F���v�I���\���ȍ������������葱���ɏ]���āA�S����Ώۂɂ���
�̏������W����v���Z�X
�Bevaluation�F�A�Z�X�����g�̌��ʂ𗘗p���ĉ��炩�̔��f�⌈����s�����Ɓi���l���f���܂ށj
1.2 ����̎葱��
������̎葱���͇B�i�K�Ő�������A���̎葱�����o�ē���ꂽ�e�X�g���_�͕ϐ��ƌĂ��B
�@���F�����܂��͍\���T�O���T�O�I�ɒ�`���邱��
�@���F�\���T�O�𑀍�I�ɒ�`���邱��
�@��O�F�ώ@���ꂽ���̂𐔒l�����邱��
�����i�K�ɂ���
�@����́u�N�ɑ��āv�u�ǂ̂悤�ȖړI�Łv���{����̂��m�����A����ɓK�������@�őΏۂƂ�
��\���T�O���`����K�v������B�\���T�O�̒�`���@�͇@�V���o�X�Ɋ�Â��ꍇ�A�A���_���f���Ɋ�Â��ꍇ��2�ʂ肪�l������ (Bachman & Palmer, 1996�j�B
�����i�K�ɂ���
�@���肵�����\���T�O�̐��_���\�ɂ��錾��^�p���A�ώ@�����蓱���������肷��菇�������
���鎖���s���B�菇����������邱�Ƃō\���T�O�𑀍�I�ɒ�`���邱�Ƃ��ł��A�ǂ̂悤�ȃ^�X�N���ۂ��ǂ̂悤�ɍ̓_����̂��Ƃ���������̎葱�������m�������B���肵�����\���T�O�̎w�W�Ƃ��ĕϐ������߂��邽�߂̘_���I������^����̂�����I��`�ł���ƌ�����B
����O�i�K�ɂ���
�@�ώ@���ꂽ����^�p�ɑ��鐔�l���̎菇���߂�i�K�B�e�X�g�⎿�⎆�A�ʐڂȂǂ����{����ꍇ�͈ȉ�2�ʂ�̐��l���̕��@������B
�@�@���炩���ߒ�`���ꂽ�i�K�ʂ̕]��ړx�Ɋ�Â��A�ώ@���ꂽ����^�p�̎��␅�����ǂ̒i�K�ɑ�
�����邩�f������@�i�҂Ɍ���Y�o�����߂�^�X�N�F���C�e�B���O�E�X�s�[�L���O�e�X�g�j
�@�A�X�̃^�X�N�⍀�ڂɑ��鉞���ɐ����E�듚��^������A�����_��^�����肷�邱�Ƃœ��_�����A
���v������@�i�Z�����̍��ڂ̏ꍇ�F�����I����E�����߂Ȃǁj
���e�X�g���_��p�������v���͌��ʂ��Ӗ��̂�����̂ƂȂ邽�߂ɂ́A����̐M�����E���߂̑Ó������m�ۂ���Ă���K�v�����邪�A����f���邽�߂ɂ͑���̎葱���i�K�����m������Ă��邱�Ƃ��K�v�ł���B
1.3 ����ړx�̎��
���ώ@���ꂽ����^�p�𐔗ʉ�����ƁA���̐��l�͑��肵���\���T�O������킷�ϐ��ƂȂ�B
���\���T�O���ǂ̂悤�ɒ�`���A�ǂ̂悤�ȋK���E�菇�ő��肵�����ɂ���Đ��l�̎�ނƏ��ʂ͈�
�Ȃ�B���l�̎�ނƏ��ʂɉ����Ē�`���ꂽ�̂��ȉ�4��ނ̎ړx�ł���A�@���C�̏��ɏ��ʂ�
�����B
�@���`�ړx�F�W�c��l�̑�������ʂ��邽�߂̎ړx
�A�����ړx�F���肵���������̓x�����̈قȂ鐅���ɁA���l�����ԂɊ��蓖�Ă��ړx
�@�@�@�@�@�@�����̋�ʂɉ����A�u�ǂ��炪�傫�����v�Ƃ����������̏����܂�
�B�Ԋu�ړx�F��������̐����Ԃ̊Ԋu���������ꍇ�ɁA�����̈قȂ鐅���𐔒l�������ړx
�@�@�@�@�@�@�����̋�ʁE�������ɉ����A�u�ǂ̂��炢�傫�����v�Ƃ��������܂�
�C�䗦�ړx�F��ʐ��E�������E���Ԋu���ɉ����Đ�Ό��_�i���̓������S���Ȃ���ԁj�����݂����
�x�B���鐔�l���ʂ̐��l�ɑ��ĉ��{�傫�����Ƃ����������B
2. �e�X�g���_�̋L�q���v
2.1 ���_���z
���e�X�g���_�v��������O�ɓx���i����K���Ɋ܂܂��f�[�^�̌��j�̕��z�}��`���A�`����m�F���Ă������Ƃ��d�v�B
�����_���z�ɂ͂��܂��܂Ȍ`���邪�A�ᓾ�_���獂���_�܂ō��E�ϐĂɕ��z���A�����̓x���������Ȃ��Ă��镪�z�̑�\�I�Ȃ��̂����K���z�ł���B
�������̓x�����傫�����K���z��蕪�z�̌`�Ƃ����Ă���ꍇ���v���X�̐�x
�������̓x�������������z���Ȃ��炩�ȏꍇ���}�C�i�X�̐�x
�������_�ɓ��_�W���E�ᓾ�_�ɐ����������}�C�i�X�̘c�x�E���z�͕��ɘc��ł���
���ᓾ�_�ɓ��_�W���E�����_�ɐ����������v���X�̘c�x�E���z�͐��ɘc��ł���
�����z�����K���z�ɂǂꂭ�炢�ߎ����Ă��邩�Ƃ������Ƃ����W�������߂�����A�e�X�g���_���z�̈Ⴂ�ɂ��Đ��_�����肷��ꍇ�ɏd�v�ƂȂ�B
�@���W�c������e�X�g�F���K���z�ł��邱�Ƃ��\�z�����
�@���ڕW������e�X�g�F��x���v���X�ŕ��ɘc���z�ł��邱�Ƃ��\�������
2.2 ��\�l�Ɠ��_�̎U���
���x�����z�}�œ��_���z�̌`����m�F������A��萳�m�ɓ��_���z�̏Љ����L�q���邽�߂ɁA��\�m�Ɠ��_�̎U���̒��x�Ɋւ��铝�v�ʂ����߂�B
����ȑ�\�l
��\�l�F���z���\����l�̂��ƂŁA���_�̒��S�X����\���B��\�l�Ƃ��Ă͍ŕp�l�E�����l�E���ϒl���ǂ��p������B
�ŕp�l�F�����Ƃ������̎҂��������_
�@�@�@�@���S�Ă̎ҏ��͔��f���Ă��Ȃ��B���`�ړx�E�����ړx�̒l�ɓK�ȑ�\�l�̎w�W�B
�����l�F�҂_�̒Ⴂ�����獂�����ɏ��ɕ��ׂ��Ƃ��̒����̓��_�B�҂������̏ꍇ�͒����l��2�ƂȂ�̂ŁA���̓��_�����v��2�Ŋ��������𒆉��l�Ƃ���B
�@�@�@�@���S�Ă̎ҏ��͔��f���Ă��Ȃ��B�����ړx�E�Ԋu�ړx�̒l�ɓK�ȑ�\�l�̎w�W�B
���ʐ��F�e�X�g�_���ɕ��ׁA�Ⴂ������25���̒l�����l���ʐ��A50���̒l�����l���ʐ��C
�@�@�@�@75���̒l���O�l���ʐ��Ƃ����B
�@�@�@�@�������ړx��c�݂��������z�ɗL�����p�\
���ϒl�F�҂̓��_��S�č��v���ĎҐ��Ŋ������l
�@�@�@�@���S�Ă̎ҏ��f���Ă���A�O��l�̉e����������B�Ԋu�ړx�E���l�v�Z������ꍇ�E�������v�ɍœK
�����z�ɘc�݂��L��ꍇ�ɂ͍ŕp�l�E�����l�E���ϒl�̂��ׂĂ��L�q���Ă������Ƃ��]�܂����B
����\�l�ɉ����A���_�̎U����̒��x�����_���z���L�q�����ŏd�v�Ȏw�W�ł���A�ł��悭�p������U���̒��x�̎w�W���W�����ł���B
���W�����F�Ԋu�ړx�̒l�̎U����\���œK�Ȏw�W�B�W�{�̕��z���L�q����ꍇ�ɗp����B
���W���������̓��a���Ґ�N�Ŋ������W�{���U�̕�����
���s�Ε��U�F�W�{�����Ƃɕ�W�c�̕��z�𐄑��������ꍇ�ɗp����B
���s�Ε��U�����̓��a���Ґ�N�|�P�Ŋ������W�{���U�̕�����
���W�����_�F�����W�c�Ɏ��{���ꂽ�قȂ�e�X�g�̓��_�𑊌݂ɔ�r�������ꍇ
�@���W�����_�F���_���畽�ϒl�������ĕW�����Ŋ������l�B�W�����_��10�{����50���������l��Z���_�ƌĂ��i���{�ł͕��l���_�Ƃ��Ă��j�B
2.3 �e�X�g���_�Ԃ̊W
��2�ȏ�̃e�X�g���W�c�Ɏ��{���A����ꂽ2�ȏ�̓��_���z�̊W�ׂ�ꍇ������B����̕ϐ��̑����ɂ�đ����̕ϐ�����������ꍇ�𐳂̑��֊W������ƌ����A�t�Ɉ���̕ϐ��̑����������̕ϐ��̌����ɑΉ����Ă���ꍇ�̑��֊W������Ƃ����B
���ϐ��Ԃ̊W��\�����v�ʂ����W���ł��邪�A���̎�ނ͗l�X�Ȃ̂ő���ړx�̎�ނƕ��z�̏ɂ��A�K�ȑ��W����p����K�v������i��\��F�s�A�\���̐ϗ����W���C�X�s�A�}���̏��ʑ��W���j�B
���ϗ����W���F
�@2�̕ϐ����Ԋu�ړx�ł��邱��
�@�A�ɂȂ��Ă���ϐ��͂��ꂼ�ꑼ�̕ϐ�����Ɨ����Ă��邱��
�@�B���K���z�ł��邱��
�@�C���`�������邱��
�����ʑ��W���F2�̕ϐ��Ԃɐ��`�̊W�͂��邪�A�ǂ��炩�̕ϐ��������ړx�ō\������Ă���ꍇ�ɗp������B
��������̑��W�����A�|1����1�܂ł̒l�ƂȂ�A���W���̐�Βl���傫���Ȃ�قNJW���������Ƃ������B
�����W���̉��߂̍ۂ̒��ӓ_
�@���W���ƈ��ʊW�͕ʕ��B���W������������Ƃ����ĕK������2�̕ϐ��ԂɈ��ʊW�����邱�Ƃ��Ӗ�����킯�ł͂Ȃ��B
�A��3�̕ϐ��̑��݂�2�̕ϐ��ԂɌ�������̑��ւ��݂���ꍇ�A�Α��W����p����B
�B�f�[�^�����K���z�ł͂Ȃ��ꍇ�E����덷�����݂���ꍇ�E2�̕ϐ��Ԃ����`�W�ɖ����ꍇ�E�ꕔ�̐��i���������邱�Ƃɂ��I�����ʂ܂��͐ؒf���ʂ����݂���ꍇ�A�O��l���L��ꍇ�A�w�ʉ����ꂽ�f�[�^�̏ꍇ�A�҂̔\�͈͂̔͂ɐ���������ꍇ�Ȃǂ̑��W���̒l�ɂ͒��ӂ��K�v
�����W�����Ӗ�������̂Ƃ��ĉ��߂��邽�߂ɂ́A2�̕ϐ��Ԃɂǂ̂悤�ȊW������̂��ɂ��āA���_���s�����A�o���Ɋ�Â��Ę_���I�ȗ��R����������邱�Ƃ��d�v�ł���B
![]() 2012�N5��30���@��2�́@�p��w�͑���_ (p.38~47)�@�S���FN.T
2012�N5��30���@��2�́@�p��w�͑���_ (p.38~47)�@�S���FN.T
3. ���ڕ��́@(p.38
~)
�� ���ڕ���
(item analysis): �e�X�g���ڂ̓��v�I�ȓ��� (�K�ȓ��_���z�E�M����) �𖾂炩�ɂ��邱�ƁB
a ��: �X�̃e�X�g���ڂ̉ɂ��Đf�f�I�ȏ��̒�
a �����E�v���O�����J����: �w�����P�ɖ𗧂��̒�
a �e�X�g�J���ҁE�쐬��: ���O�̃e�X�g�̓��_���z��e�X�g�̓�Փx���x���̒����E���I��ѐ��̐M��
���̌���E�L���ɋ@�\���Ă��Ȃ����ڂ̎��O�̔�����C���ɖ𗧂���
3.1 �ÓT�I���ڕ���
�e���ڂ̓��_�̐ςݏグ�����v�_�ƂȂ�B
�@ �����E�듚:
[ 2�l�^�̓_ ] ���� = 1�_, �듚 = 0�_
�A �����_��^������@
a �҂̊e���ڂւ̉��������l������邽�߁A���ړ��_�̕��z�v�I�ɋL�q���邱�Ƃ��\�B
�@ ���ڕ��͂̌��ʁA�e��̍��ړ��v�� (��Փx�E�ٕʗ�) ���Z�o�����B
�� ���ړ�Փx:
�e���ڂ��ǂ̂��炢������������w�W�B������듚�̐��ݓI�Ȗ���f�f�ł���B
�@�� ���ړ�Փx�w�W (item difficulty index, p):
0 �� p �� 1
2�l�^�̓_����:
�����Ґ��^�S�Ґ��@�̊���
�����_�̓_����: ���ړ��_�̕��ϒl�^(�����_�̍ő�\�l�|�ŏ��\�l)�@�̊���
��������I�҂̊����E�e�����_���҂̊��������߂邱�Ƃ��\�B
�� ���ڕٕʗ�:
�e���ڂ��ǂꂾ�����я�ʎ҂Ɖ��ʎ҂ʂł��邩�̎w�W�B
���_���z�̌`���M�����ɉe����^����B
�@�� ���ڕٕʗ͎w�W (item discrimination index, D):
-1 �� D �� 1, �v���X�̒l���傫���قǕٕʗ͂������B
(���̍��ڂɉ������я�ʌQ�^�S��) ? (���щ��ʌQ�^�S��)�@
���я�ʌQ�E���ʌQ�̐l���́A���v�_�ł��ꂼ��3����1���邢��27%
�� �_�o�W�� (point-biserial correlation coefficient): ���ړ��_�ƍ��v�_�̑��W�����v�Z�����@
�@�@2�l�ړx�̍��ړ��_�̊Ԋu�ړx�Ƃ��Ă̍��v�_�@�̐ϗ����W��
�@�@�����鍀�ڂٕ̕ʗ͂�������A���̍��ڂ̐����҂̍��v�_�͂�荂���A�듚�҂͂��Ⴂ�B
�@�@�@a ���ړ��_�ƃe�X�g�̍��v�_�Ƃ̊Ԃɂ͋������̑��֊W������A�Ƃ����\�z��O��Ƃ�����́B
�@�� �ٕʗ͎w�W�͋������̃e�X�g�ŗp���������ŁA�_�o�W���͑�K�̓e�X�g�ŗp������B
�� ���ڃo���N:
�e�X�g�̕i���Ǘ��Ƃ��āA���ڂ̓��e�ƍ��ړ����l�̏����L�^����B
�� ���ڑI���̊:
�y �W�c������e�X�g �z
�� ���ړ�Փx��0.5�O��̍��ڂ𒆐S�Ƃ���B
a ��Փx���ɒ[�ȏꍇ�́A�ٕʗ͎w�W���Ⴂ�X���ɂ���B
�� �ł��邾���ٕʗ͂̍������ڂ�I�� (D ��0.3,
D < 0.2 �̏ꍇ�͍폜���C�����]�܂���)
�@a �W������傫�����邱�Ƃ��ł��A���I��ѐ��̐M���������߂邱�Ƃ��ł���B
�y �ڕW�K�������e�X�g �z ���ۂ̕���_�̊����ɋ߂����ړ�Փx�w���������ڂ�I������B
3.2 �ÓT�I���ڕ��͂̌��E
(1) �W�{�Ɉˑ������L�q���v�ʂ��������Ȃ��B�y�W�{�ˑ��z
�@���ړ��v��a �e�X�g����������̏W�c��҂Ɉˑ�����B
�@�e�X�g���_a �e�X�g���\���������̍��ڌQ�Ɉˑ�����B
a �ҏW�c���قȂ�ꍇ�͍��ړ��v�ʂ̔�r�E�e�X�g���قȂ�ꍇ�ɂ́A�҂̓��_�̔�r������
a �w�͂̐L�т𑪂邽�߂ɕ��s�e�X�g���K�v�����A�ÓT�I���ڕ��͂Ɋ�Â����ړ��v�ʂ���쐬���邱
�Ƃ͍���B
(2) ���鍀�ڂ̍��ړ����l�Ƃ���҂̔\�͐����l�Ƃ����т��������Ȃ��B
(3) ���ڂƂ��������1�� (��: facet) �݂̂��������Ă��Ȃ��B
�E �X�s�[�L���O��C�e�B���O�̃e�X�g�ł́A�����̃^�X�N�����肻����̕]��҂��]������B
�@ a �]��҂̑��ΓI�Ȍ������̏���K�v������B
4.�@���ډ������_
4.1 �l����
�� ���ډ������_
(item response theory: IRT):
�E�ÓT�I�e�X�g���_�̌��E���������邽�߂ɊJ�����ꂽ���胂�f��
�E�e�X�g���ڂɑ��鑽���̎҂̉����p�^�[������A���ڂ̓����l�Ǝ҂̔\�͒l�𐄒肷��B
a �\�͒l�͉��肳�ꂽ���ݓ����ړx��Ɉʒu�Â��ĕ\�����B
a ���ڂ̍���x�Ǝ҂̔\�͒l�Ƃ��Ɨ��̓����l�Ƃ��Đ��肳���B
��
�҂̊w�́E�\��
(��) �͍��ڂɑ��鐳��̉����p�^�[�����琄�肳���B
a ����̑O�� = �u�\�͂̍����҂͂�肻�̍��ڂɐ�������m���������v
��
�Ǐ��Ɨ��̉���
(local independence assumption): �������̔\�͒l�������l�̍��ڂւ̉����͂��ꂼ��̍��ڂŌ݂��ɓƗ��ł���B
= 1�������̉���
(unidimensionality assumption): ���ׂĂ̍��ڂ�1�̓����݂̂����ʂ��đ��肵�Ă���B
4.2 ���ړ����Ȑ�
�� ���ړ����Ȑ�
(item characteristic curves): �e�X�g���ڂ̓�����\���Ȑ��ŁA����\�͒l�����҂�
���̍��ڂɐ�������m����\���B�҂̔\�͒l�������Ȃ�A�������������Ȃ�Ƃ����O��B
(a) ���ڍ���x�p�����^
(difficulty parameter): ���ړ����Ȑ����E�ɂ���قǁA���ڂ𐳓����邽�߂ɗv��
�����\�͒l���x���������̂ŁA������ڂł���B
(b) ���ڎ��ʗ̓p�����^
(discrimination parameter): ���ړ����Ȑ��̌X�����}�ȂقǁA�\�͒l�̍�������
���m�Ɏ��ʂ��� (����1, 3)�B
(c) ���Đ��ʃp�����^
(guessing parameter): �\�͒l�̒Ⴂ�҂̐����m����0�łȂ��ꍇ�́A���Đ���
�Ő�������\���������B�����I�������ڂł悭������B
���p�����^: ���ړ����Ȑ��̌`������肷��̂ɕK�v�Ȓ萔�B
�� ���ډ������_�̊�{���f����:
�\�͒l���̎҂�����j�ɐ�������m���B
a ���W�X�e�B�b�N����p����Ɛ��w�I�Ɉ����₷���B
�@ �� 1 �p�����^�E���W�X�e�B�b�N�E���f��(1PLM = ���b�V�����f��): (b) �݂̂��܂߂�
(a = c = 0)
�� 2�p�����^�E���W�X�e�B�b�N�E���f��(2PLM): (a), (b) ���܂߂�
( c = 0)
�� 3�p�����^�E���W�X�e�B�b�N�E���f��(3PLM): (a), (b), (c) ���܂߂�
a �܂߂�p�����^��������قǁA���肵������l�邽�߂ɑ����̎҂��K�v�ɂȂ�B
��2�l�^IRT���f�� (dichotomous IRT model): ���ړ��_��1��0�ō̓_�����2�l�^���ڂ�ΏۂƂ���B
�@�̑��l�^IRT���f��:
�����_��i�K�_�ō̓_�����B

�}1�@���ړ����Ȑ��̗� (p. 42��蔲��)
4.3 ���ʂƏ���
�� ���ڏ���
(amount of item information): �҂̔\�͒l�����𐄒肷��ہA���鍀�ڂ��\�����ʁB
���ڏ����ŕ\�����B
�� �\�͒l�����ɉ����ď��ʂ��قȂ�Ba ���ʂ��傫���Ɛ��x�̍�������l (estimates) ��������B
�� �e�X�g����
(amount of test information I(��)): �e�X�g���\������e���ڂ̍��ڏ��ʂ����v�������́B
�� �e�X�g����
(test information function): ����\�͒l�ŗ^������e�X�g���ʂ�\�����Ȑ��B
�e�X�g������e�\�͒l�����ɂ�������ʂ̑傫���𐄒肷��B
�� ����̕W���덷
(standard error of estimation): �e�\�͒l�����ɂ����鑪�萸�x�B�@1�^�@���e�X�g���
�� �قȂ�\�͒l�����ɂ����čő�̍��ڏ��ʂ���鍀�ڂ�I�ʂ��邱�ƂŁA���萸�x�̍����e�X
�g���쐬�ł���B
�y�W�c������e�X�g�z���L���\�͒l�����ōő�̏��ʂ������鍀�ڂ�I������B
�y�ڕW�K�������e�X�g�z���ۂ̕���_�ɋ߂��\�͒l�ōő�̏��ʂ������鍀�ڂ�I������B
4.4 �e�X�g�J���ւ̉��p
�� ���ډ������_�̓���
�E�ҏW�c�ɑ��݂��Ȃ����ړ����l������ł���B
�E����̃e�X�g���ڌQ�Ɉˑ����Ȃ��҂̔\�͒l������ł���B
�E�҂��Ƃɂ��̃e�X�g�ɂ�鑪�萸�x��]�����邱�Ƃ��ł���B
a �e�X�g (�ړx)
�̓�����e�Ղɂ��邽�߁A�e�X�g�J���̑��胂�f���Ƃ��Ă悭�p������B
�� �e�X�g�̓���
(equating): �e�X�g�̈قȂ�ł��瓾��ꂽ���茋�ʂ𑊌݂ɔ�r�\�ɂ��邽�ߋ���
�ړx��ŕ\�����߂̎葱���BEx. TOEFL PBT�̃e�X�g�͂ǂ̉�̃e�X�g����r�\�Ƃ���Ă���B
�� �p��͂̌o�N�ω��̌���:
���ډ������_�̓����ɂ��A�����N�x�̊w�̓e�X�g����r�\�ƂȂ�B
�E���Z���̉p��͂�Z���^�[�����ő��肳���p��͂��N�X�ቺ���Ă���B
�E�p��͂̊w�Z�Ԋi�����L�����Ă���B
�� ���̑��̖���
�EDIF (���ٍ��ڋ@�\)
�̍��ڂ̌��o
�E���ʎړx��ō���x�⎯�ʗ͂����肳��Ă��鍀�ڃo���N�̍쐬
�E�w�͂̍��۔�r����
4.5�@�������b�V�����f��
n ���b�V�����f��: 1�̑� (fact) �݂̂͂̃v���Z�X�ň����B
n ����̑�: ����̃v���Z�X�Ńe�X�g���_�ɉe����^����ƍl�����鑤�ʁB
ex.
���ځE�^�X�N�E�]��ҁE�E�ŁE�e�X�g���@�@a �e���͕����̏��� (condition) ���܂ށB
n �������b�V�����f��: ���b�V�����f���̊g�����f����1�B�����̑��̕��͂��s�����Ƃ��\�B
ex.
�҂������̃^�X�N��^�����ă^�X�N���ƂɈقȂ�]��҂ɂ���ĕ]�肳���ꍇ
a ���ڂ̑��ΓI�ȍ���x�ɉ����ĕ]��҂̑��ΓI�Ȍ������̒��x�̏������B
a ���f���ɓK�����Ȃ����ځE�]���҂���� a ���ڂ̏C���E�폜��]��҂̍̔ہE�ČP��
n ���w���b�V�����f���ɂ�FACETS program (Linacre & Wright, 1993) ���p������B
n FACETS: ���W�b�g�ړx (����0,
�W����1�ɕW�������ꂽ�ړx) ��ŁA���ڂ̍���x��]��҂̈ӌ������̒��x�𐄒�l�Ƃ��Ď����B
|
���W�b�g�l |
���� |
�]��� |
|
�v���X (�傫��) |
������� |
�������]��� |
|
�}�C�i�X (������) |
�Ղ������� |
���]��� |
a Infit: �f�[�^�ƃ��f���̓K���x��\���w�W�B
�}2�ȏゾ�ƓK���x������ (misfit)�@a ���ځE�]��҂̕ύX�E�C���ɐ�������
n FACETS�ł͑��̑g�ݍ��킹�����ѐ��������Ȃ�����Ɋւ�����������B�y���ݍ�p�z
1)
�]��҂Ǝ�, 2) ���ڂƎ�, 3) ���ڂƕ]��� ��3��ނ̑g�ݍ��킹�̏ꍇ
1)
�������̏W�c�ɂ͊Â��̓_������]���
2)
���鍀�ڌQ�ɂ��Ĉ�ѐ��̂Ȃ��A�܂��̓o�C�A�X�̂���]�������]���
3)
����̍��ڌQ�ɓ��ʂȉ����������
![]() 2012�N6��6���@��2�́@�p��w�͑���_ (p.47~58)�@�S���FY.Y
2012�N6��6���@��2�́@�p��w�͑���_ (p.47~58)�@�S���FY.Y
5�D�M����
5.1
�l����
�E�M����(reliability)�Ƃ́A����̈�ѐ�(consistency)���邢�����萫(stability)�����x�ł���B
�E�e�X�g���_�́A���肵�����\�͈ȊO�ɂ����܂��܂ȗv���ɂ���ĉe�����A�ϓ�����B
l
�҂̑̒�
l
�e�X�g���{�菇�̈Ⴂ
l
���Ԃ̌o�߂ɂ��҂̔\�͂̕ω�
l
�e�X�g�̔ł̈Ⴂ
l
�]��҂̈Ⴂ�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@
�Ȃǂ�����덷(measurement error)�̌����ƂȂ�B
���M������e�X�g���_�Ƃ́A���肵�����\�͂��ő�����f���A����덷���ɗ͊܂܂Ȃ����_�B
������덷�̌��������S�ɏ������邱�Ƃ͂ł��Ȃ��B
�E�M�������̗��_�Ƃ��āA�ÓT�I�e�X�g���_�i����덷���ꊇ���Ĉ����j����ʉ��\�����_�i�덷��v���ɕ����Ĉ����j������B
5.2
�ÓT�I�e�X�g���_�Ɋ�Â��M��������
5.2.1. �M��������̃��f��
�E�ÓT�I�e�X�g���_�ł́A����덷�͈ꊇ���ă����_���ɔ��������Ɖ��肷��B
�E�e�X�g�̊ϑ����_(observed
score)= x�A�^�̓��_=![]() �A�덷���_=
�A�덷���_=![]() �Ƃ���ƁA
�Ƃ���ƁA
![]()
�e�X�g�ϑ����_�̕��U=![]() �A�^�̓��_�̕��U=
�A�^�̓��_�̕��U=![]() �A�����_���Ȍ덷���U=
�A�����_���Ȍ덷���U=![]() �Ƃ���ƁA
�Ƃ���ƁA
![]() =
= ![]() +
+ ![]()
�̎������藧�B
�E�ϑ����_�̕��U�ɑ��āA�^�̓��_�̕��U���傫����Α傫���قǁA�܂��덷���U����������Ώ������قǁA���̃e�X�g�̊ϑ����_�͂��M�����������Ƃ�����B
�E���_��̐M����(![]() )�́A�ϑ����_�̕��U�ɂ��߂�^�̓��_�̕��U�̊����A
)�́A�ϑ����_�̕��U�ɂ��߂�^�̓��_�̕��U�̊����A![]() �ł���ƒ�`����A�M�����W����0��r��1�̋�ԂŎ������B
�ł���ƒ�`����A�M�����W����0��r��1�̋�ԂŎ������B
���^�̓��_�̕��U��덷���U�̑傫���͎��ۂɂ͂킩��Ȃ��B
5.2.2.
�M�����̐�����@
�E�ÓT�I�e�X�g���_�Ɋ�Â��M�����̐�����@�ɂ́A(1)������ѐ��Ɋ�Â����@�ƁA(2)���萫�Ɋ�Â����@������A�M�����̐���͈ȉ��̂R�i�K�ōs����B
1�D����덷�̌��������
2�D�Ɨ��ŕ��s��2�̓��_�����W���邽�߂̌����v��𗧂Ă�
3�D2�̓��_�̓K�ȑ��W���A�܂��̓e�X�g���_�̕��U�Ɋ�Â����W�����Z�o����
�i1�j ������ѐ��̐M��������
�E������ѐ�(internal consistency)�̐M��������̕��@�Ƃ��āA�ܔ��@(split-half method)�����ڕ��U(item variance)��p������@������B
�P�j�@�ܔ��@�ɂ��M��������
�E�e�X�g���_��2�������A1�l�̎҂ɓ�����2�̓��_�̑��W�������߁A�M�����̐���l�Ƃ�����@�B
�E�������@�Ƃ��āA�����ԍ��Ɗ�ԍ��̍��ڂɕ�������@����ʓI�����A���e�⑪�肵�Ă���\�͂̓_����2��������ȂǁA���炩�̊��݂���2��������ꍇ������B
�E��ʓI�ɂ͒����e�X�g�i���ڐ��������j�ق����Z���e�X�g�����M�����������Ȃ�B
�E�ܔ��@�ł̓e�X�g���ɂ����̂ŁA���̒����̒Z�k�̂��߁A����ꂽ���ւ��C������K�v������B���̂��߂ɗp������������X�s�A�}���E�u���E���̏C�������ł���B
�M�����W����2![]()
�Q�j�@���ڕ��U�ɂ��M��������
�E�X�̍��ڂ̕��U�Ɋ�Â��ĐM�����W�����v�Z������@�ŁA�e���ڂ̕��U�ƁA�S�̓��_�̕��U��p���ē�����ѐ��̐M��������l���v�Z����B
�E�Ԋu�ړx�ȏ�ŕ����_�̓_�̏ꍇ�A���W��(coefficient alpha)���p������B
![]()
�E����ō̓_�����2�l�f�[�^�̏ꍇ�AKR20
(Kuder-Richardson formula 20)�AKR21��p����B
�E���ڐ��𑝂₵�ăe�X�g������ƁA�ق��̏����������ł���ΐM�����͍����Ȃ�B
�E�e�X�g�����邱�Ƃłǂ̒��x�̐M�����������邩���肷����@���X�s�A�}���E�u���E���̗\�z����(Spearman-Brown
prophecy formula)�ł���B
�Ek=���݂̍��ڐ��̔{���A![]() =�]�܂����M�����̐����A
=�]�܂����M�����̐����A![]() =���݂̐M�����̐����Ƃ����Ƃ��A�ȉ��̌����ŋ��߂���B
=���݂̐M�����̐����Ƃ����Ƃ��A�ȉ��̌����ŋ��߂���B
![]()
�i2�j ���萫�̐M��������
�P�j�@�ăe�X�g�M��������l
(test-retest reliability estimates)
�E�����ҏW�c�ɓ����e�X�g��2����{���A�����̑��ւ����߂邱�ƂŐM�����𐄒肷����@�B
�E2�̃e�X�g���_�s����Ƃ��Ĉ����A���Ԍo�ߌ�̃e�X�g���_�̈��萫�𐄒肷��B
�E�����e�X�g��2����{����̂��덷�̌����͎҂ɂ����ƍl������B
�ăe�X�g�@�̖��_
1�D���K����(practice
effect)���l�����邱�ƁA
2�D2��ڂ̃e�X�g���{�܂łɎ҂̔\�͒l�������ω����邱�ƁA
3�D1��ځA2��ڂƂ��Ƀ����_���Ȍ덷�������邱��
�Q�j�@�������i���s����j�M��������l(equivalence
reliability estimates)
�E���萫�̂Ȃ�������e�X�g�̔�(forms)�̈Ⴂ����N�������Ƃ�����A�e�X�g�̔ł�������(equivalence)����������K�v������B
�E���肳���\�͂ƍ��ڂ̓��e��`�����������ƍl������2�̃e�X�g�̔ł��쐻���A����W�c�Ɏ��{������A2�̃e�X�g���_�̑��W�����Z�o���A������������M��������l�Ƃ���B
�E���������̉\�����ŏ������邽�߂ɁA�ލ��^�v��(counterbalanced design)��p���A�W�c���ƂɎ�e�X�g�̔ł̏�����ς��邱�Ƃ��]�܂����B
�R�j�@�]��҂̈�ѐ��ɂ��M��������l
�E��l�̕]��҂���ѐ��̂Ȃ��̓_������ꍇ�A�����̕]��ҊԂōŒ�̕s��v��������ꍇ���l������B
�]��ҊԐM����(inter-rater
reliability):
�]��҂�2���̏ꍇ�A2�̕]��̑��W���A�܂��̓��W�������߁A�M�����̐���l�Ƃ���B3���ȏ�̏ꍇ�A�]��҂̕]������v���A���W�������߂邱�Ƃɂ���ĐM�����̐���l�����߂�B
�]��ғ��M����(intra-rater
reliability):
1�l�̕]��҂Ɏ����������āA2�x�̓_���Ă��炢�A�����҂ɂ���2�ʂ�̕]��A�]��Q�̑��W���A�܂��̓��W�����Z�o���A�M�����̐���Ɖ��߂���
5.2.3.
����̕W���덷�ƐM�����
�E�M�����W���́A�l�̃e�X�g���_�̐��m���Ɋւ�����͒��Ȃ��B
�E�l�̃e�X�g���_�̐M�����Ɋւ�����邽�߂ɂ́A����̕W���덷(standard
error of measurement: SEM)�����߂�K�v������B![]() �͊ϑ����_�̕W�����A
�͊ϑ����_�̕W�����A![]() �͐M�����W���ł���B
�͐M�����W���ł���B
![]()
5.3
��ʉ��\�����_
5.3.1.
�l����
�E�ÓT�I�e�X�g���_�ł͌덷��������܂Ƃ߂Ɉ����A�S�Ă̌덷�������_���ɔ�������ƍl����B
�������_���ȑ���덷�ƌn���I�ɔ������鑪��덷�Ƃ���ʂ��邱�Ƃ��ł��Ȃ��B
�E��ʉ��\�����_(generalizability
theory: G-theory)�ɂ���āA�e�X�g���_�ɉe�����y�ڂ��l�X�ȕϓ��v���̑傫���𐄒肷�邱�Ƃ��ł���B
5.3.2.
��ʉ��\�������i�f�����j
�E���U���̓��f����p���āA���_�̕ϓ����ǂ̂悤�ȗv���ɂ���Ăǂ̒��x�������Ă���̂���������B
�E�Ⴆ�A���C�e�B���O�\�͂𑪒肷�邽�߂Ɏ҂Ƀ^�X�N��^���A�����̕]��҂��̓_����ꍇ�ł́A����Ώۂ͎Ҍl�̃��C�e�B���O�\�͂ł���A�^�X�N�ƕ]��҂���(facet)�ƂȂ�B���̏ꍇ�A2�̑������邽�߁A2���v��(two-facet design)�ƌĂ��B
�E�l���̑ΏۂƂȂ�S�^�X�N�ƑS�]��ҁi��W�c�j���A���ꂼ�����e�ϑ����(universe
of admissible observations)�ƌĂԁB
�EG�����̖ړI�́A�l�X�ȕ��U�v���̑��ΓI�Ȋ����𐄒肷�邱�ƂŁA����l�͕��U����(variance components)�ƌĂ�A![]() �Ŏ������B
�Ŏ������B
�E�e�X�g�J���҂�G�����̑��i�K�Ƃ��āA�e�X�g�Ɋ܂߂鑪��̑�����肷��B
�P�j
�P���v��
�E�P�̑�(facet)�݂̂̃e�X�g�̏ꍇ��P���v��(one-facet design)�Ƃ����B
�E�q�σe�X�g�̂悤�ȃP�[�X�ł͕ϓ����鍀�ڂ͎҂Əo�荀�ڂ����ł���A���̏ꍇ�̑��͏o�荀�ڂ̂݁B
�E�҂����ׂĂ̍��ڂ���ꍇ�A�҂ƍ��ڂ̃f�[�^��������B���̂��Ƃ��N���X�v��(crossed
design)�ƌĂԁB
�E�P���N���X�v��ł́A3�̕ϓ��v���A
�@����̑Ώہi�ҁjp�A�A���ڂ̑�i�A�B�҂ƍ��ڂ̌��ݍ�pp�~i
���l������A����ȊO�œ��_�ɉe����^���鐬���͌덷�̕��U�Ƃ���B
�E�덷�͌��ݍ�p�̕��U�����Ɋ܂߁A���v���_�̕��U![]() �͂��ꂼ�ꕪ�U�����̘a�Ő��������B
�͂��ꂼ�ꕪ�U�����̘a�Ő��������B
�E���U�����̐���ɉ����A�e���ڂ̓�Փx�̎w�W�Ƃ��Ă����̕��ϒl�����肳���B
�Q�j
2�����S�N���X�v��
�E���C�e�B���O�̃e�X�g�ŁA�����̃^�X�N���҂ɗ^�����A�^�X�N�ɑ���͕����̕]��҂ɂ���č̓_����A�܂��A�S�҂����ׂẴ^�X�N�ɉ������A�S���]��ґS���ɂ���č̓_�����悤�ȏꍇ�́A�^�X�N�ƕ]��҂�2�����S�N���X�v��(fully crossed design with two facets)�Ƃ����B
���̏ꍇ�A
�@��p�A�A�^�X�Nt�A�B�]���r�A�C�҂ƃ^�X�N�̌��ݍ�pp�~t�A
�D�҂ƕ]��҂̌��ݍ�pp�~r�A�E�]��҂ƃ^�X�N�̌��ݍ�pr�~t�A
�F�c��(residual)�Ƃ��Ď҂ƕ]��҂ƃ^�X�N�̌��ݍ�p�ƌ덷p�~r�~t, e
�𐄒肵�A�����̍��v���_�̕��U![]() ���A������7�̕��U�����̍��v�ŕ\�����B
���A������7�̕��U�����̍��v�ŕ\�����B
�E���ڑ��̕��ϒl�ƕ]��҂̑��̕��ϒl�������A���ꂼ�ꍀ�ړ�Փx����ѕ]��̌������̎w�W�Ƃ��ĉ��߂����B
3�j 2���}������v��
�E���ׂĂ̑����N���X�����̂łȂ��A1���̑������̑��Ɠ���q�ɂȂ��Ă���ꍇ�A2���}������v��(two-facets
nested design)�ƌĂ�Ap�~(i;t)�ŕ\�����B
�E���[�f�B���O��X�j���O�̃e�X�g�̂悤�ɁA1�̃e�L�X�g�ɕ����̐ݖ���ꍇ�A�ݖ�i���ځj���e�L�X�g�ɓ���q�ɂȂ��Ă���ƍl���Ai:t�ŕ\���B
�E2���}������v��ł�
�@��p�A�A�e�L�X�gt�A�B�e�L�X�g�̒��̍���i:t�A�C�҂ƃe�L�X�g�̌��ݍ�pp�~t�A
�D�c���i�e�L�X�g�̒��̎҂ƍ��ڂ̌��ݍ�p�ƌ덷�jp�~i : i,
e
�𐄒肵�A���v���_�̕��U![]() �͂����5�̕��U�����̍��v�Ő��������B
�͂����5�̕��U�����̍��v�Ő��������B
�E�e�e�L�X�g�̕��ϒl�������A�����̓e�L�X�g�Ɋ܂܂�鍀�ڂɂ���đ���ꂽ�e�L�X�g�̓�Փx�̎w�W�Ƃ��ĉ��߂����B
5.3.3.
���茤���i�c�����j
�ED�����̖ړI�́AG�����œ���ꂽ���U�����̏���p���āA����덷���ŏ�������悤�ȑ���葱���v�悷�邱�ƂŁA�ȉ��̏��D�����ɂ���ē�����B
�@
�e�X�g���_�ɐ�߂镪�U�����̑��ΓI�傫���̏��
�A
�ϑ����_���꓾�_�̐���l�ɂǂ̒��x�ˑ����Ă��邩�Ƃ����M���x(dependability)�̏��
�E��ʉ��\�����_�ł͍��v���_�̕��U![]() �́A�꓾�_���U
�́A�꓾�_���U![]() �ƌ덷���U
�ƌ덷���U![]() �̍��v����\�������
�̍��v����\�������
�E�꓾�_���U��D�����Ő��肳���̂ŁA�M���x����̂��߂ɁA�덷���U�𐄒肷��B
�E��ʉ��\�����_�ł͑���덷���A
�@�@���ΓI�ȑ���덷(relative
measurement error)�F�W�c������e�X�g�ɑΉ�
�A�@��ΓI�ȑ���덷(absolute
measurement error)�F�ڕW������e�X�g�ɑΉ�
��2�ɋ�ʂ���B
�E���ΓI����̂��߂̐M���x����ʉ��\���W��![]() (generalizability coefficient: G�W��)�A
(generalizability coefficient: G�W��)�A
�E��ΓI����̂��߂̐M���x���M���x�W����(index
of dependability:�@�ӌW��)�ƌĂ��B
�E��ʉ\�����_�̕��U������A�M���x����l���Z�o����v���O�����Ƃ��āAGENOVA (Crick
& Brennan, 1983)��mGENOVA
(Brennan, 2001)�Ȃǂ�����B
5.4
��ʉ��\�����_�̗��_�ƌ��E
�E��ʉ��\�����_�̌ÓT�I�e�X�g���_�ɑ������_�́A
�@�@�����̌덷�v���̑��ΓI�ȉe���̑傫���𐄒肷�邱�Ƃ��ł���
�A�@���ꂼ��̑���덷�̗v���̑傫���U�����Ƃ����`�Ő��肷�邱�Ƃ��ł���
�B�@����̊e���ɂ���������̐������邱�ƂŁA����̐M�������œK���ł���
�C�@���ΓI�덷�Ɛ�ΓI�덷�Ƃ���ʂ��ANRT�ɂ�CRT�ɂ��Ή��\�ȐM���x����l���Z�o�ł���
�E����A��ʉ��\�����_�����E�Ƃ��āA
�@�@2�̃e�X�g���_���瓾����M��������l�́A����̎ҏW�c�Ɉˑ�����
�A�@�ǂ��������덷���ǂ̔\�͒l�����ɂ����Ă������ł��邱�Ƃ�O��Ƃ��Ă���
�_����������B
�������̖��_����������̂����ډ������_�ł���B
6.
����
6.1
�l����
�E�e�X�g�̓��_�����ɍs���邱�����������⌈��́A�e�X�g���_�����̂悤�ɉ��߂��g�p���邱�Ƃ̑Ó������S�ۂ���Ă��邱�Ƃ��O��ƂȂ�B
�E�e�X�g���_�̉��߂�g�p���Ó��ł��邱�Ƃ�ۏ��邽�߂ɗl�X�ȏ؋������ɘ_���I����������K�v������A���̉ߒ���Ó���������(validation)�Ƃ����B
�E�Ó������u���肵�Ă���Ǝ咣������e���ǂ̒��x���肵�Ă��邩�v�Ɋւ���T�O�ł���Ƃ���A
�@ ���e����(content validity)
�A ��֘A�Ó���(criterion-referenced validity)
�B �\���T�O����(construct validity)
��3��ł���Ƃ���Ă������A���݂ł��\���T�O�Ó����ł�����Ó������\�������Ƃ����l�����A�Ó����͒P��̊T�O(a unitary concept)�ł���Ƃ����l�����嗬�ƂȂ��Ă���B
�EMessick(1989)�͑Ó������ȉ��̂悤�ɒ�`�Â��Ă���B
�u�Ó����Ƃ́A�e�X�g���_�܂��͂���ɗނ��鑼�̕]���@�����ɂ��čs�����_�ƍs�ׂ̑������Ȃ�тɓK�ؐ��ɂ��āA������x������o���I�؋��Ɨ��_�I���R�Â��̓x���������������I�ȕ]�����f�������v
�EMillaer, Linn & Gronlund (2012: 72-73)�͑Ó����Ƃ����p���p���钍�ӓ_�Ƃ��Ĉȉ���4�_�������Ă���
�@�@�u�e�X�g�̑Ó����v�́A��萳�m�ɂ́u�e�X�g���ʂ����ƂɂȂ������߂⓾�_�g�p�̑Ó����v
�A�@�Ó����͒��x���ł���A�Ó������܂������Ȃ������芮�S�ł�������Ƃ������Ƃ͂Ȃ�
�B�@�Ó����́A��ɓ���̎ҏW�c�ɑ��āA����ْ̖��ł̎g�p����߂ɓK�p�������̂ŁA���ׂĂ̖ړI�ɑ��đÓ��ł���悤�ȕ]���͑��݂��Ȃ�
�C�@�Ó����͒P��̊T�O�ł���A��I�ȕ]�����f���܂ނ��̂ł���
6.2
�Ó����̌���
�E�e�X�g���_�̓���̉��߂��Ó��ł���ƍl����������I�Ș_��W�J���Ă����A�_�Ɋ�Â��A�v���[�`(argument-based approach)�Ƃ����l�������A�Ó����̌����̊�{�ł���B
�E�_�Ɋ�Â��A�v���[�`�ɂ��Ó��������ł́A
�@�@���ߓI�_��(interpretive
argument)�c�Ó����̘_��W�J���邽�߂̘g�g�݂��
�A�@�Ó����̘_��(validity
argument)�c���ߓI�_�̑S�ʓI�ȕ]��
���s����B
Kane(2006:
23-25)�ɂ��_�Ɋ�Â��A�v���[�`
�E���ߓI�_�̒i�K�ł́A�@�̓_(scoring)�A�A��ʉ�(generalization)�A�B�O�}(extrapolation) �A�C����(decision)
�̂S�̐��_���^���A���ꂼ��̐��_�ɑ��Ap.57�̂悤�ȉ������l����B
�E�Ó����̘_�̒i�K�ł́A�e���_�ɂ����鉼�����K�Ȃ��̂Ɣ��f�ł��邩�A�K�ȏ؋���p���ĕ]������B
�̓_�̐��_�ł́A�̓_����K���A�̓_�̎��Ǘ����O�ꂵ�čs���Ă��邩���f�����B
�E��ʉ��̐��_�ł́A�M�������ʉ��\�������A�e�X�g�Ɋ܂߂��鍀�ڕW�{�̑�\���ɂ��Ă̔��f�����߂���B
�E�O�}�̐��_�ł́A�e�X�g������Z�\�ƃR�[�X�ŕK�v�Ƃ����Z�\�̏d�Ȃ�̒��x�f������A�e�X�g���_�ƃR�[�X�ɂ�����p�t�H�[�}���X�̑���l�i���сj�Ƃ̊W�����ؕ��͂����肷��B
�E����̐��_�ł́A���肩�瓾��ꂽ�l�X�Ȏ�ނ̘_���ɂ́A�e���_��x�����鉼���Ɋ֘A���āA���Ƃ̔��f�A���،����A��s�����̌��ʁA���l���f�����܂܂��B
�EBachman(2005)��Bachman
& Palmer(2010)�́Akane(2002; 2006)�̘_�Ɋ�Â��Ó��������̘g�g�݂����ɁA����e�X�g�̑Ó��������̂��߂ɁA�e�X�g�g�p�Ɋւ���_��(Assessment Use Argument: AUA)�Ƃ����l������W�J�����B
�EAUA�ł́A�Ó��������Ƃ����p��̑����������(justification)��p����B
�E�Ӑ}�����e�X�g�g�p�ł��邱�Ƃ��ǂ̒��x�������ł���̂��A�Ƃ����ϓ_����e�X�g�g�p�̐��������s���B�E
�EAUA�ł͊e���_�̒i�K�ŏq�ׂ���u�咣(claim)�v�ɑ��āA�u���R�t��(warrant)�v�Ɓu����(rebuttal)�v���q�ׂ���B